人工神经网络训练图像分类器
磐创AI我们将仅使用全连接层在20000张图像上训练图像分类模型。所以没有卷积和其他花哨的东西,我们将把它们留到下一篇文章中。
不用说,但你真的不应该使用普通的人工神经网络来分类图像。图像是二维的,通过展平图像,你将失去使图像可识别的模式。尽管如此,它还是很有趣且可行的,并且会让你洞察这种方法的所有错误。
使用的数据集和数据准备
我们将使用Kaggle的狗与猫数据集。它是根据知识共享许可证授权的,这意味着你可以免费使用它:
图1:狗与猫数据集:
该数据集相当大——25000张图像均匀分布在不同的类中(12500张狗图像和12500张猫图像)。它应该足够大,可以训练一个像样的图像分类器,但不能使用人工神经网络。
唯一的问题是——它的结构不适合直接使用。你可以按照之前的文章创建一个适当的目录结构,并将其拆分为训练集、测试集和验证集:
缩小、灰度化和展平图像
让我们导入相关库。我们需要很多,需要安装Numpy、Pandas、TensorFlow、PIL和Scikit Learn:
我们不能将图像直接传递到Dense层。单个图像是三维的——高度、宽度、颜色通道——而Dense层需要一维输入。
让我们看一个例子。以下代码加载并显示训练集中的cat图像:
src_img = Image.open('data/train/cat/1.jpg')
display(src_img)
图2——猫的图片示例

图像宽281像素,高300像素,有三个颜色通道(np.array(src_img).shape)。
总的来说,它有252900个像素,在展平时转化为252900个特征。让我们尽可能节省一些资源。
如果有意义的话,你应该对你的图像数据集进行灰度化。如果你能对不以颜色显示的图像进行分类,那么神经网络也应该如此。可以使用以下代码段将图像转换为灰色:
gray_img = ImageOps.grayscale(src_img)
display(gray_img)
图3:灰色猫图像

显然,它仍然是一只猫,所以颜色在这个数据集中并没有起到很大作用。
灰度图像宽281像素,高300像素,但只有一个颜色通道。这意味着我们从252,900 像素减少到84,300 像素。仍然很多,但肯定是朝着正确的方向迈出了一步。
数据集中的图像大小不同。这对于神经网络模型来说是个问题,因为它每次都需要相同数量的输入特征。
我们可以将每个图像调整为相同的宽度和高度,以进一步减少输入特征的数量。
下面的代码片段调整了图像的大小,使其既宽又高96像素:
gray_resized_img = gray_img.resize(size=(96, 96))
display(gray_resized_img)
图4:调整大小的猫图片

当然,图像有点小而且模糊,但它仍然是一只猫。但是我们的特征减少到9216个,相当于将特征的数量减少了27倍。
作为最后一步,我们需要将图像展平。你可以使用Numpy中的ravel函数来执行此操作:
np.ravel(gray_resized_img)
图5:扁平猫图片
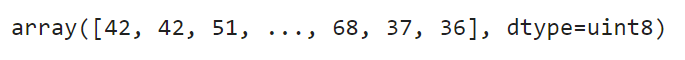
计算机就是这样看待猫的——它只是一个9216像素的数组,范围从0到255。问题是——神经网络更喜欢0到1之间的范围。我们将整个数组除以255.0即可:
img_final = np.ravel(gray_resized_img) / 255.0
img_final
图6-扁平和缩放的猫图像
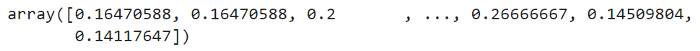
作为最后一步,我们将编写一个process_image函数,将上述所有转换应用于单个图像:
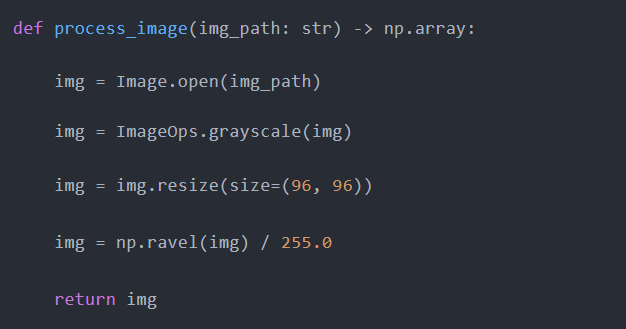
让我们在随机的狗图像上进行测试,然后反转最后一步,以直观地表示图像:
tst_img = process_image(img_path='data/validation/dog/10012.jpg')
Image.fromarray(np.uint8(tst_img * 255).reshape((96, 96)))
图7:经过变换的狗形象

就这样,这个函数就像字面意思。接下来,我们将其应用于整个数据集。
将图像转换为表格数据进行深度学习
我们将编写另一个函数——process_folder——它迭代给定的文件夹,并在任何JPG文件上使用process_image函数。然后,它将所有图像合并到一个数据帧中,并添加一个类作为附加列(猫或狗):
让我们将其应用于训练、测试和验证文件夹。每个文件夹需要调用两次,一次用于猫,一次用于狗,然后连接集合。我们还将把数据集转储到pickle文件中:
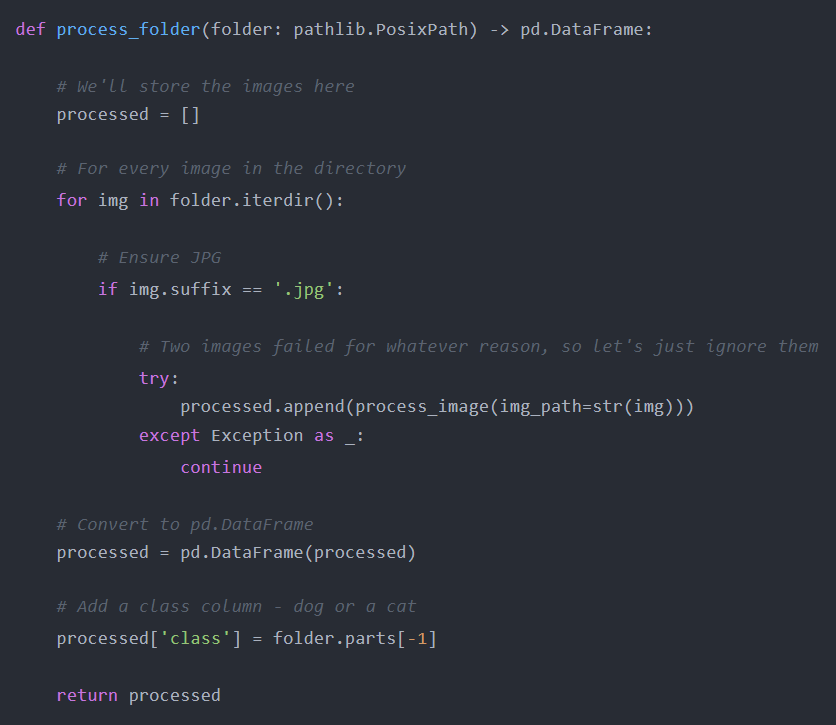
下面是训练集的样子:
# Training set
train_cat = process_folder(folder=pathlib.Path.cwd().joinpath('data/train/cat'))
train_dog = process_folder(folder=pathlib.Path.cwd().joinpath('data/train/dog'))
train_set = pd.concat([train_cat, train_dog], axis=0)
with open('train_set.pkl', 'wb') as f:
pickle.dump(train_set, f)
# Test set
test_cat = process_folder(folder=pathlib.Path.cwd().joinpath('data/test/cat'))
test_dog = process_folder(folder=pathlib.Path.cwd().joinpath('data/test/dog'))
test_set = pd.concat([test_cat, test_dog], axis=0)
with open('test_set.pkl', 'wb') as f:
pickle.dump(test_set, f)
# Validation set
valid_cat = process_folder(folder=pathlib.Path.cwd().joinpath('data/validation/cat'))
valid_dog = process_folder(folder=pathlib.Path.cwd().joinpath('data/validation/dog'))
valid_set = pd.concat([valid_cat, valid_dog], axis=0)
with open('valid_set.pkl', 'wb') as f:
pickle.dump(valid_set, f)
图8——训练集

数据集包含所有猫的图像,然后是所有狗的图像。这对于训练集和验证集来说并不理想,因为神经网络会按照这个顺序看到它们。
你可以使用Scikit Learn中的随机函数来随机排序:
train_set = shuffle(train_set).reset_index(drop=True)
valid_set = shuffle(valid_set).reset_index(drop=True)
下面是它现在的样子:
图9——随机后的训练集

下一步是将特征与目标分离。我们将对所有三个子集进行拆分:
X_train = train_set.drop('class', axis=1)
y_train = train_set['class']
X_valid = valid_set.drop('class', axis=1)
y_valid = valid_set['class']
X_test = test_set.drop('class', axis=1)
y_test = test_set['class']
最后,使用数字编码目标变量。有两个不同的类(cat和dog),因此每个实例的目标变量应该包含两个元素。
例如,使用factorize函数进行编码:
y_train.factorize()
图10-factorize函数

标签被转换成整数——猫为0,狗为1。
你可以使用TensorFlow中的to_category函数,并传入factorize后的数组,以及不同类的数量(2):
y_train = tf.keras.utils.to_categorical(y_train.factorize()[0], num_classes=2)
y_valid = tf.keras.utils.to_categorical(y_valid.factorize()[0], num_classes=2)
y_test = tf.keras.utils.to_categorical(y_test.factorize()[0], num_classes=2)
因此,y_train现在看起来是这样的:
图11——目标变量

从概率的角度考虑——第一张图片有100%的几率是猫,0%的几率是狗。这些都是真实的标签,所以概率可以是0或1。
我们现在终于有了训练神经网络模型所需的一切。
用人工神经网络(ANN)训练图像分类模型
我随机选择了层的数量和每层的节点数量,以下2部分不能更改:
· 输出层——它需要两个节点,因为我们有两个不同的类。我们不能再使用sigmoid激活函数了,所以选择softmax。
· 损失函数——我们使用分类交叉熵。
其他部分可以随意更改:
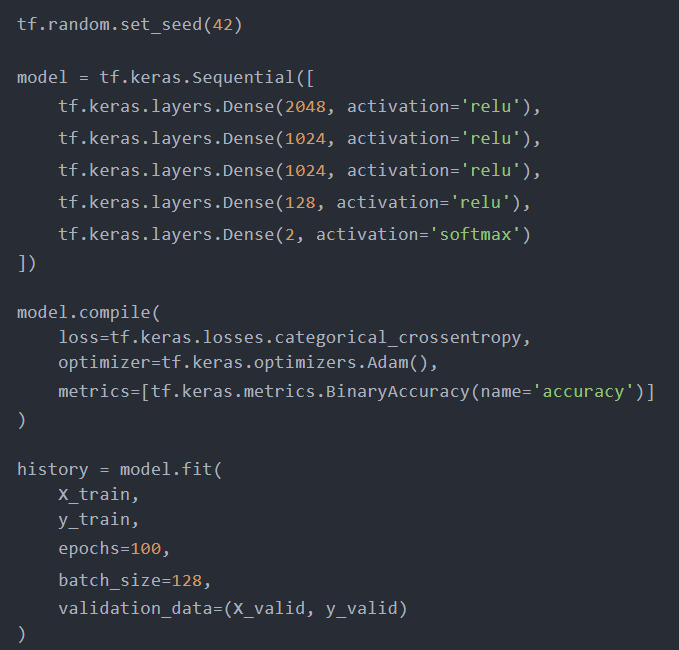
以下是我在100个epoch后得到的结果:
图12:100个epoch后的ANN结果

60%的准确率比猜测稍微好一点,但性能一般。尽管如此,我们还是来检查一下训练期间指标发生了什么变化。
以下代码片段绘制了100个epoch中每个epoch的训练损失与验证损失:
plt.plot(np.arange(1, 101), history.history['loss'], label='Training Loss')
plt.plot(np.arange(1, 101), history.history['val_loss'], label='Validation Loss')
plt.title('Training vs. Validation Loss', size=20)
plt.xlabel('Epoch', size=14)
plt.legend();
图13:训练损失与验证损失
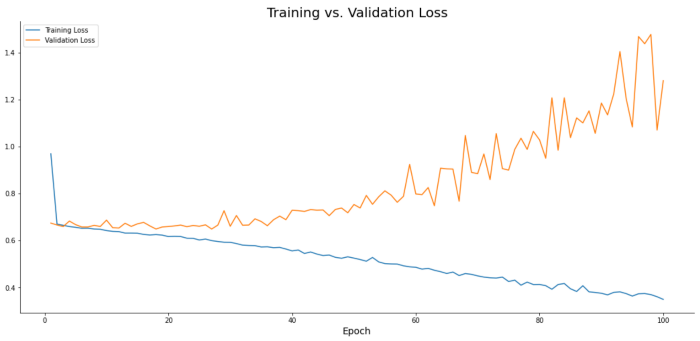
该模型能很好地学习训练数据,但不能推广。随着我们对模型进行更多epoch的训练,验证损失继续增加,这表明模型不稳定且不可用。
让我们看看准确度:
plt.plot(np.arange(1, 101), history.history['accuracy'], label='Training Accuracy')
plt.plot(np.arange(1, 101), history.history['val_accuracy'], label='Validation Accuracy')
plt.title('Training vs. Validation Accuracy', size=20)
plt.xlabel('Epoch', size=14)
plt.legend();
图14:训练准确度与验证准确度
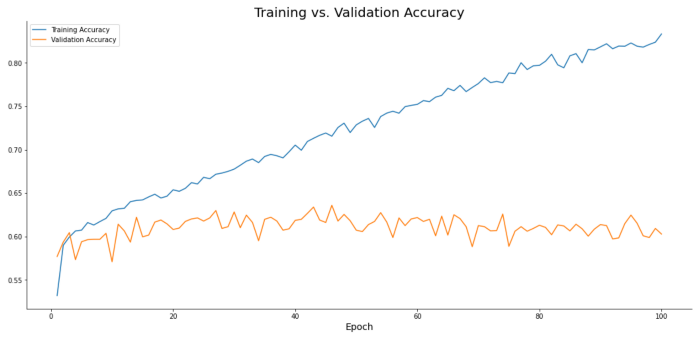
类似的图片。验证精度稳定在60%左右,而模型对训练数据的拟合度过高。
对于一个包含20K训练图像的两类数据集,60%的准确率几乎是它所能达到的最差水平。原因很简单——Dense层的设计并不是为了捕捉二维图像数据的复杂性。
结论
现在你知道了——如何用人工神经网络训练一个图像分类模型,以及为什么你不应该这么做。这就像穿着人字拖爬山——也许你能做到,但最好不要。
