科普 | 共识专栏之HotStuff共识
趣链科技
—— ?前言 ——
我们已经了解到分布式系统一般通过状态复制机[1]原理来实现一致性。其核心思想是系统中所有副本运行着相同的状态机,只要所有副本都以相同的初识状态开始,并基于相同的初识状态执行一组相同顺序的操作,那么所有的状态最终会收敛一致,即整个系统对外表现出一致性。而确定这一组相同顺序的操作需要系统达成共识,进一步说即所有诚实节点对执行顺序达成共识,这便是著名的拜占庭将军[2]问题。
拜占庭类共识算法的理论安全保证,即n>3f,n为总的节点数量,f为恶意节点数量。一个拜占庭共识算法需要保证两个性质:
其中s是一个抽象的概念,可以理解为系统内存在一个变量S,这个变量S的取值为系统状态,系统内节点接收一系列关于S的操作指令,某时刻(假设每个节点时钟没有误差)就S的取值进行共识,所有诚实节点确定变量S=s则满足安全性,所有诚实节点对变量S的取值必须做出决定且终止则满足活性。
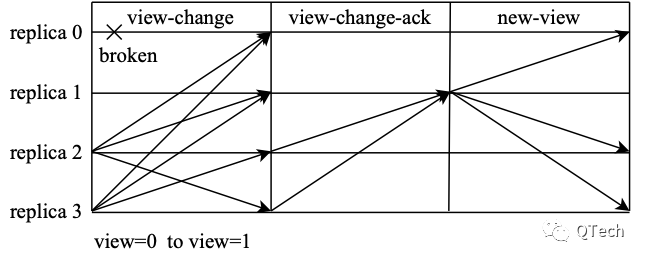
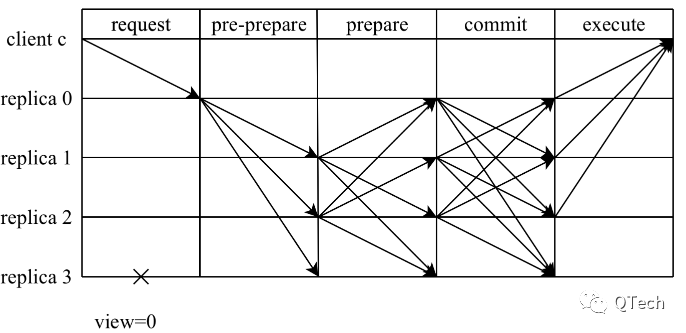
以往,在分布式系统的研究中,拜占庭类共识往往都伴随着较高的通信复杂度,对网络造成的消耗极大,系统规模不易扩大。如经典的PBFT算法,其达成共识需要经过三个阶段,PRE-PREPARE阶段主节点将请求消息发送给其他节点,其他节点对该消息验证过后,各自发送prepare消息给其他节点,这个阶段产生了n^2条消息。为了保证跨视图上的一致性,节点在收到至少quorum的prepare消息后再发送commit消息给其他节点。当节点最终收到至少quorum的commit消息时,再最终对该请求进行提交。而网络异常节点超时触发视图切换时,则需要o(n^3)的通信复杂度
理解PBFT中每个阶段的工作是HotStuff的基础,PBFT中每个阶段都目标都是为保证安全性和活性。
假设系统某时刻收到指令S'=S+1,主节点将这条指令S'=S+1发送给非主节点(这是pre-prepare消息),因为是拜占庭问题,诚实节点不确定自己收到的是否和其他诚实节点一致(主节点发送不一致消息),节点之间需要进行一次相互通信,确定自己和其他诚实节点收到的消息一致(确定主节点没有发送不一致消息),每个节点发送prepare消息给其他所有节点,之后若收到quorum个数量的prepare消息,且通过验证(验证prepare中指向的指令与自己一致),达成第一轮共识(这是PREPARE阶段)。此时,似乎可以确定了诚实节点收到的消息一致。但是这里隐含条件是,达到共识的节点只是在自己的视角看到:我收到并验证了quorum个一致的消息。但其他节点不一定和自己一样收到quorum个prepare消息达成共识,如果此时进行提交,出现了网络故障,提交了的节点知道已经达成共识,只要等网络恢复,这条指令一定会被整个系统提交。但其他节点可能由于网络故障还未达成共识,他们无法确定一直等下去能否提交。为了让系统保持活性,进行视图切换,此时新的主节点需要确定是在S'还是S的基础上执行新的指令。如果没有发现部分节点已经提交了该指令,且对另一条指令S''=S+2进行了共识并提交,系统对变量S的取值产生了不一致。因此,在此时提交有安全性的问题。
如果再进行一个阶段的共识,在达成PREPARE共识之后,各自再发送一个commit消息,各自节点等待接受并验证quorum个commit消息之后再提交。会遇到同样的问题,达成COMMIT共识的节点提交了,他们知道如果网络正常,系统迟早都会提交,但是其他未达成COMMIT共识的节点不确定最后能否提交。网络发生故障后新视图中的主节点如果没有发现已经提交了的节点,依然会造成不一致。这里的矛盾是我们为了活性需要切换视图继续共识;为了安全性还要确保新视图开始共识前S的取值一致,已经提交了的指令在新视图中也一定需要被提交。而在PBFT中采用视图切换时向其他节点发送消息证明自己S的状态的方法,即发送自己最新的S的一条pre-prepare消息和对应的quorum条prepare消息。视图切换时,新主节点共识前就能判断S'=S+1是否需要提交。
按照这种规则安全性和活性就得到了保证,而这种方法带来的复杂度却是o(n^3)。因此该算法依然不能够运用在大规模的网络当中。尹茂帆等人提出的HotStuff共识算法[4]具有线性视图变更的特性,解决了经典的PBFT甚至BFT类共识的瓶颈,主节点的切换无需增加其他协议和代价,系统仍能对外工作表现一致性,使得共识流程通信复杂度降低至o(n)。
—— ?HotStuff 基本概念 ——
了解hotstuff算法需要介绍几个与共识流程相关的概念:
1)门限签名[5](Threshold signatures):一个(k,n)门限签名方案指由n个成员组成的签名群体,所有成员共同拥有一个公共密钥,每个成员拥有各自的私钥。只要收集到k个成员的签名,且生成一个完整的签名,该签名可以通过公钥进行验证。
2)证书(Quorum Certificate,QC):主节点收到至少quorum个节点对用一个提案的投票消息(带签名)后,利用门限签名将其合成一个QC,这个QC可以理解为门限签名生成的完整签名,表示对该次提案达成一次共识。
3)视图(View):视图是共识的基本单元,一个视图至多达成一次共识,并且单调递增,每个视图逐渐轮换推进共识。
4)共识状态树:每个共识区块可以看做是一个树节点,每个树节点内包含对应的提案内容(前文的操作指令)和相对应的QC,每个树节点包含一个父亲树节点的哈希,形成一棵树状结构,主节点基于本地最长的分支生成新的树节点。落后节点根据其他节点的最长分支上的最新树节点来同步中间缺失的树节点。
—— ?HotStuff 共识流程 ——
HotStuff的核心围绕着三轮共识投票展开,原论文中提出了三种形式:简易版HotStuff(Basic HotStuff),链状HotStuff(Chained HotStuff),事件驱动的HotStuff(Event-Driven HotStuff)。接下来将通过对比PBFT中每个阶段共识的过程来理解HotStuff算法。
▲?Basic Hotstuff
Basic HotStuff是共识的基本过程。其中,视图以单调递增的方式不断切换。每个视图内都有一个唯一的主节点负责提案、收集和转发消息并生成QC,整个过程包括4个阶段:准备阶段(PREPARE)、预提交阶段(PRE-COMMIT)、提交阶段(COMMIT)、决定阶段(DECIDE),主节点提交(达成共识)某个分支,在PREPARE、PRE-COMMIT、COMMIT三个阶段收集quorum个共识节点带签名的投票消息,利用门限签名合成一个QC,然后广播给其他节点。
HotStuff 结合门限签名可以将之前互相广播共识消息的方式,转为由主节点处理、合并转发,通信复杂度可以降低到o(n),简而言之就是HotStuff用门限签名+两轮通信达到了PBFT一轮通信的共识效果。
对比PBFT算法,共识开启于主节点将请求附带在pre-prepare中发送给其他节点,主节点即履行完了该轮共识的职责,接下来和其他节点一样。整个共识过程包括一个广播提案阶段(PRE-PREPARE阶段),两个共识阶段(PREPARE阶段、COMMIT阶段)。
PREPARE阶段:
主节点:1)根据收到的quorum条New-View消息,该消息中包含了发送方的状态树中高度最高的prepareQC,主节点在收到的prepareQC中计算出高度最高的QC,记为highQC;
2)根据这个highQC的节点所指向的分支,打包区块创建新的树节点,其父节点为highQC指向的节点;
3)将生成的提案附带在prepare消息中发送给其他从节点,且当前提案包含highQC。
从节点:1)收到该prepare消息之后,对prepare中的信息进行验证,包括qc中签名的合法性;是否当前视图的提案;
2)prepare消息中的节点是否扩展自lockedQC的分支(即孩子节点)或者prepare消息中的highQC的视图号大于lockedQC(前者为安全条件,后者为活性条件保证节点落后时及时同步);
3)生成prepare-vote消息并附带一个签名发送给主节点。
PRE-COMMIT阶段:
主节点收到quorum个当前提案的prepare-vote消息时,通过聚合quorum个部分签名得到prepareQC;然后主节点广播pre-commit消息附带聚合得到的prepareQC。
从节点:其他节点收到pre-commit消息,验证之后,发送pre-commit vote消息给主节点。
??注意此时,在主节点发送的pre-commit中的prepareQC就表明了prepare消息中的提案消息,所有节点投票成功达成了共识,这一时刻与PBFT中PREPARE阶段达成共识类似。
Commit阶段:
主节点:与pre-commit阶段类似。1)主节点先收集quorum个pre-commit vote消息,然后聚合出这一阶段的pre-commitQC,附带在commit消息中发送给其他节点。2)设置本地lockedQC为pre-commitQC。
从节点:收到commit消息时,消息验证通过同样更新本地的lockedQC为commit消息中的pre-commitQC,对其签名并生成commit vote并发送给主节点
??注意此时,主节点发送的commit消息附带的pre-commitQC即与PBFT中的第二轮COMMIT阶段共识类似,其中PBFT中该阶段共识表明了节点对的第一阶段达成共识这件事的共识,即确保了至少quorum个节点已经完成PREPARE阶段,在发生视图切换时,有足够多的节点能够证明对该提案达成了PREPARE共识,在新视图中提案内容需要被提交。
DECIDE阶段:
主节点:1)收集到quorum个commit vote消息时,聚合得到commitQC,并且附带在decide消息中发送给其他节点;
2)当其他节点收到decide消息时,其中commitQC指向的提案中的交易就会被执行;
3)之后增加视图号viewnumber,开启下一轮共识,根据prepareQC构造New-View消息。
从节点:验证消息后执行decide消息中commitQC指向的树节点的交易。
nextView interrupt阶段:在共识中任何其他阶段发生了超时事件,发送新视图的new-view消息,都会直接开启下一轮新的共识。
??注意,HotStuff中一笔交易从开始到提交进行了三轮共识,第三轮共识的加入,克服了经典两阶段范式的共识算法扩展的瓶颈。PBFT中为了保证系统在遇到恶意节点时能继续工作(活性),需要进行视图切换,而新视图中为了确定上一个视图中的区块是否达成共识,需要在view-change消息中附带自己收集到的quorum个prepare消息和相对应的一个pre-prepare消息作为证明,然后每个节点广播view-change消息请求视图切换,此时广播的消息复杂度o(n^2),消息的量级为o(n),因此视图切换的复杂度为o(n^3)。安全性和活性让PBFT需要o(n^3)的通信复杂度,对于网络的负载极大,限制了其向大规模网络的扩展。而HotStuff中如果我们对某一区块达成了两轮共识,在更换主节点时便能确定,主节点只需要基于最新的两轮共识节点产生新节点是安全的。换句话说,只需要根据区块自身的状态(经过几轮共识)就可以确定是否在新的视图中基于该区块打包块新区块,降低了在视图切换时候的通信复杂度。
▲?Chained HotStuff
可以发现在Basic HotStuff中的各个阶段流程都高度的相似,HotStuff的作者便提出了Chained HotStuff来简化Basic HotStuff的消息类型,并允许Basic HotStuff的各个阶段以流水线方式进行处理交易。
Chained HotStuff的流程如图:
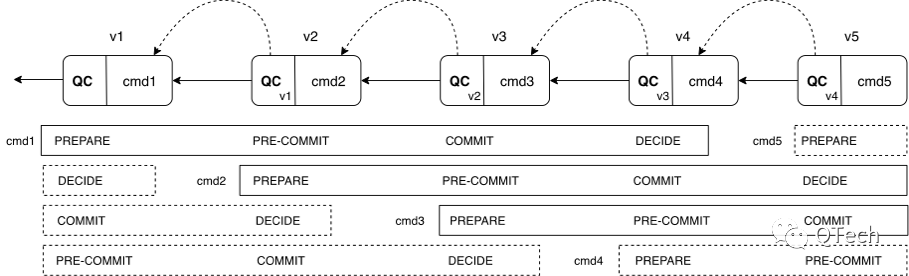
从图中可以看出,每个阶段都会切换视图,因此每个提案都有自己的视图。节点对于不同的提案来说处在不同的视图上,PREPARE阶段的投票被当前视图的主节点合成QC,并转发给下一个视图的主节点,即下一视图在进行PREAPRE阶段的同时,也在进行上一个视图的PRE-COMMIT阶段。每个阶段具有类似的结构,视图v+1的PREPARE阶段可以看作是视图v的PRE-COMMIT阶段。视图v+2的的PREPARE阶段看作是视图v+1的PRE-COMMIT阶段和视图v的COMMIT阶段。v1中的cmd1将在视图v1,v2,v3中分别进行PREPARE、PRE-COMMIT、COMMIT阶段,在v4中就进行提交。cmd2以此类推。每个阶段的cmd提案产生将会附带上一阶段投票产生的QC。经过流水线简化版本的HotStuff工作过程如下:
主节点:1)等待NEW-VIEW消息,发出自己的提案;
2)等待其他节点进行投票;
3)向下一个主节点发送NEW-VIEW消息。
从节点:1)等待主节点的提案消息;
2)检查提案中的QC,更新本地highQC,lockedQC,发送投票;
3)向下一个主节点发出NEW-VIEW消息。
▲?Event-driven HotStuff
从Chained HotStuff到Event-driven HotStuff,实现原论文中将整个协议的安全性(safety)和活性(liveness)解耦开,活性成为单独的pacemaker模块。pacemaker模块保证了在全局稳定时间(GST)之后的活性。提供两个功能:
换而言之,在如此低的视图切换代价下,pacemaker中可以采用任何合适的节点轮换机制,以及任何提案生成策略。
Event-driven Hotstuff与其他版本原理还是核心的三阶段共识,区别只是工程实现上的便利,具体可见论文伪代码[4]
—— ?HotStuff 之改进优化-NoxBFT ——
活性机制优化
活性机制是共识能够持续推进的关键。在原HotStuff论文中活性机制使用了一个全局一致的超时时间确定了视图超时。在NoxBFT中,我们设计了更灵活的机制应对网络环境的不稳定。
具体:每个节点进入新的视图后,根据配置等待超时时间,如果本视图未超时,则定时器时长不变。若超时,则不断广播TimeoutMsg,直到收到quorum个TimeoutMsg进入下一视图,此时定时器置为配置时间k倍,连续超时n次则置超时器为k^n倍。以此类推,这样避免在网络不稳定时频繁切换视图。
交易缓存池
在区块链的应用中,为避免交易丢失,我们设计了交易缓存池缓存客户端交易。共识模块主动拉取交易进行打包。交易池也可以减轻共识工作量,进行交易去重,我们通过交易内容hash标识交易,将已经执行的交易写入布隆过滤器,防止双花攻击,提升共识算法的稳定性。
快速恢复机制
不稳定的网络环境可能使共识节点丢失共识消息,导致节点落后。在HotStuff原论文中,作者将此部分具体实现留给了开发者。我们实现了工程可用的同步算法,让落后共识节点恢复定序功能,分为两步:
1)节点落后较多,直接向其他节点拉取区块执行恢复到最新检查点。
2)检查点之后的共识进度落后,向其他节点拉取最新的CommitQC快速恢复共识进度。
为提高效率,我们采取并行向不同节点拉取区块的机制,可以灵活配置并行度。并行拉取的区块先进行持久化再有序执行,同时记录各个节点拉取效率的分数,以便下次高效选取目标节点进行同步。整个过程可以以最快的速度拉取所有丢失的交易,减少整个过程的等待时间。
聚合签名
NoxBFT中实现并改进了Ed25519聚合签名算法。一方面通过编译预先计算的数据加速;另一方面,我们实现了大数类型专用的加速Ed25519的计算过程,压缩大数的存储。最终Ed25519算法要比官方快2.5倍,签名算法也实现了更高的性能。
总结
在BFT类的共识研究中,安全性的要求需要在视图切换时,主节点确保自己是基于最新的系统状态工作的,视图切换与系统状态的共识产生了o(n^3)的通信复杂度。而HotStuff通过增加一轮共识来解决,再结合门限签名降低了通信复杂度。不仅如此,流水线的工作方式,让算法变得足够简洁优雅,这与raft的工作方式相似,采取了先上链再共识,通过三轮共识之后再执行。这种链式的结构,不再区分每个阶段通信的意义(PBFT中prepare、commit),灵活的主节点更换的机制,在节点更换时不需要通信来确定最新共识的状态,对安全性与活性进行隔离,投票保证了安全性,pacemaker保证了其在网络异步时的活性。
作者简介
程泰宁 趣链科技基础平台部共识算法研究小组
参考文献
[1] Schneider F B . The state machine approach: A tutorial[J]. Springer New York, 1990.
[2] Lamport L , ?Shostak R , ?Pease M . The Byzantine Generals Problem[J]. ACM Transactions on Programming Languages and Systems, 1982, 4(3).
[3] Castro M, Liskov B. Practical Byzantine fault tolerance[C]. OSDI.1999, 99(1999): 173-186.
[4] Yin M , ?Malkhi D , ?Reiter M K , et al. HotStuff: BFT Consensus in the Lens of Blockchain[J]. ?2018.
[5] Shoup V . Practical Threshold Signatures[C]// International Conference on Theory & Application of Cryptographic Techniques. Springer-Verlag, 2000.
我们已经了解到分布式系统一般通过状态复制机[1]原理来实现一致性。其核心思想是系统中所有副本运行着相同的状态机,只要所有副本都以相同的初识状态开始,并基于相同的初识状态执行一组相同顺序的操作,那么所有的状态最终会收敛一致,即整个系统对外表现出一致性。而确定这一组相同顺序的操作需要系统达成共识,进一步说即所有诚实节点对执行顺序达成共识,这便是著名的拜占庭将军[2]问题。
拜占庭类共识算法的理论安全保证,即n>3f,n为总的节点数量,f为恶意节点数量。一个拜占庭共识算法需要保证两个性质:
- 安全性:所有诚实节点都认为某一时刻系统状态为s
- 活性:所有诚实节点最终能确定s为系统状态
其中s是一个抽象的概念,可以理解为系统内存在一个变量S,这个变量S的取值为系统状态,系统内节点接收一系列关于S的操作指令,某时刻(假设每个节点时钟没有误差)就S的取值进行共识,所有诚实节点确定变量S=s则满足安全性,所有诚实节点对变量S的取值必须做出决定且终止则满足活性。
以往,在分布式系统的研究中,拜占庭类共识往往都伴随着较高的通信复杂度,对网络造成的消耗极大,系统规模不易扩大。如经典的PBFT算法,其达成共识需要经过三个阶段,PRE-PREPARE阶段主节点将请求消息发送给其他节点,其他节点对该消息验证过后,各自发送prepare消息给其他节点,这个阶段产生了n^2条消息。为了保证跨视图上的一致性,节点在收到至少quorum的prepare消息后再发送commit消息给其他节点。当节点最终收到至少quorum的commit消息时,再最终对该请求进行提交。而网络异常节点超时触发视图切换时,则需要o(n^3)的通信复杂度
理解PBFT中每个阶段的工作是HotStuff的基础,PBFT中每个阶段都目标都是为保证安全性和活性。
假设系统某时刻收到指令S'=S+1,主节点将这条指令S'=S+1发送给非主节点(这是pre-prepare消息),因为是拜占庭问题,诚实节点不确定自己收到的是否和其他诚实节点一致(主节点发送不一致消息),节点之间需要进行一次相互通信,确定自己和其他诚实节点收到的消息一致(确定主节点没有发送不一致消息),每个节点发送prepare消息给其他所有节点,之后若收到quorum个数量的prepare消息,且通过验证(验证prepare中指向的指令与自己一致),达成第一轮共识(这是PREPARE阶段)。此时,似乎可以确定了诚实节点收到的消息一致。但是这里隐含条件是,达到共识的节点只是在自己的视角看到:我收到并验证了quorum个一致的消息。但其他节点不一定和自己一样收到quorum个prepare消息达成共识,如果此时进行提交,出现了网络故障,提交了的节点知道已经达成共识,只要等网络恢复,这条指令一定会被整个系统提交。但其他节点可能由于网络故障还未达成共识,他们无法确定一直等下去能否提交。为了让系统保持活性,进行视图切换,此时新的主节点需要确定是在S'还是S的基础上执行新的指令。如果没有发现部分节点已经提交了该指令,且对另一条指令S''=S+2进行了共识并提交,系统对变量S的取值产生了不一致。因此,在此时提交有安全性的问题。
如果再进行一个阶段的共识,在达成PREPARE共识之后,各自再发送一个commit消息,各自节点等待接受并验证quorum个commit消息之后再提交。会遇到同样的问题,达成COMMIT共识的节点提交了,他们知道如果网络正常,系统迟早都会提交,但是其他未达成COMMIT共识的节点不确定最后能否提交。网络发生故障后新视图中的主节点如果没有发现已经提交了的节点,依然会造成不一致。这里的矛盾是我们为了活性需要切换视图继续共识;为了安全性还要确保新视图开始共识前S的取值一致,已经提交了的指令在新视图中也一定需要被提交。而在PBFT中采用视图切换时向其他节点发送消息证明自己S的状态的方法,即发送自己最新的S的一条pre-prepare消息和对应的quorum条prepare消息。视图切换时,新主节点共识前就能判断S'=S+1是否需要提交。
- 如果没有任何一个节点就S'=S+1达成PREPARE阶段共识,则不会继续对S'=S+1进行提交。
- 如果存在一个节点对达成了S'=S+1达成了PREPARE阶段共识,则不可能对一条冲突的指令S''=S+2达成共识并提交,
按照这种规则安全性和活性就得到了保证,而这种方法带来的复杂度却是o(n^3)。因此该算法依然不能够运用在大规模的网络当中。尹茂帆等人提出的HotStuff共识算法[4]具有线性视图变更的特性,解决了经典的PBFT甚至BFT类共识的瓶颈,主节点的切换无需增加其他协议和代价,系统仍能对外工作表现一致性,使得共识流程通信复杂度降低至o(n)。
—— ?HotStuff 基本概念 ——
了解hotstuff算法需要介绍几个与共识流程相关的概念:
1)门限签名[5](Threshold signatures):一个(k,n)门限签名方案指由n个成员组成的签名群体,所有成员共同拥有一个公共密钥,每个成员拥有各自的私钥。只要收集到k个成员的签名,且生成一个完整的签名,该签名可以通过公钥进行验证。
2)证书(Quorum Certificate,QC):主节点收到至少quorum个节点对用一个提案的投票消息(带签名)后,利用门限签名将其合成一个QC,这个QC可以理解为门限签名生成的完整签名,表示对该次提案达成一次共识。
3)视图(View):视图是共识的基本单元,一个视图至多达成一次共识,并且单调递增,每个视图逐渐轮换推进共识。
4)共识状态树:每个共识区块可以看做是一个树节点,每个树节点内包含对应的提案内容(前文的操作指令)和相对应的QC,每个树节点包含一个父亲树节点的哈希,形成一棵树状结构,主节点基于本地最长的分支生成新的树节点。落后节点根据其他节点的最长分支上的最新树节点来同步中间缺失的树节点。
—— ?HotStuff 共识流程 ——
HotStuff的核心围绕着三轮共识投票展开,原论文中提出了三种形式:简易版HotStuff(Basic HotStuff),链状HotStuff(Chained HotStuff),事件驱动的HotStuff(Event-Driven HotStuff)。接下来将通过对比PBFT中每个阶段共识的过程来理解HotStuff算法。
▲?Basic Hotstuff
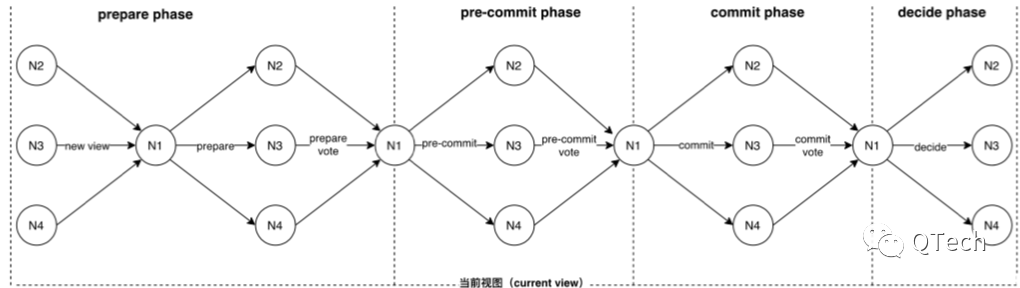
Basic HotStuff是共识的基本过程。其中,视图以单调递增的方式不断切换。每个视图内都有一个唯一的主节点负责提案、收集和转发消息并生成QC,整个过程包括4个阶段:准备阶段(PREPARE)、预提交阶段(PRE-COMMIT)、提交阶段(COMMIT)、决定阶段(DECIDE),主节点提交(达成共识)某个分支,在PREPARE、PRE-COMMIT、COMMIT三个阶段收集quorum个共识节点带签名的投票消息,利用门限签名合成一个QC,然后广播给其他节点。
HotStuff 结合门限签名可以将之前互相广播共识消息的方式,转为由主节点处理、合并转发,通信复杂度可以降低到o(n),简而言之就是HotStuff用门限签名+两轮通信达到了PBFT一轮通信的共识效果。
对比PBFT算法,共识开启于主节点将请求附带在pre-prepare中发送给其他节点,主节点即履行完了该轮共识的职责,接下来和其他节点一样。整个共识过程包括一个广播提案阶段(PRE-PREPARE阶段),两个共识阶段(PREPARE阶段、COMMIT阶段)。
PREPARE阶段:
主节点:1)根据收到的quorum条New-View消息,该消息中包含了发送方的状态树中高度最高的prepareQC,主节点在收到的prepareQC中计算出高度最高的QC,记为highQC;
2)根据这个highQC的节点所指向的分支,打包区块创建新的树节点,其父节点为highQC指向的节点;
3)将生成的提案附带在prepare消息中发送给其他从节点,且当前提案包含highQC。
从节点:1)收到该prepare消息之后,对prepare中的信息进行验证,包括qc中签名的合法性;是否当前视图的提案;
2)prepare消息中的节点是否扩展自lockedQC的分支(即孩子节点)或者prepare消息中的highQC的视图号大于lockedQC(前者为安全条件,后者为活性条件保证节点落后时及时同步);
3)生成prepare-vote消息并附带一个签名发送给主节点。
PRE-COMMIT阶段:
主节点收到quorum个当前提案的prepare-vote消息时,通过聚合quorum个部分签名得到prepareQC;然后主节点广播pre-commit消息附带聚合得到的prepareQC。
从节点:其他节点收到pre-commit消息,验证之后,发送pre-commit vote消息给主节点。
??注意此时,在主节点发送的pre-commit中的prepareQC就表明了prepare消息中的提案消息,所有节点投票成功达成了共识,这一时刻与PBFT中PREPARE阶段达成共识类似。
Commit阶段:
主节点:与pre-commit阶段类似。1)主节点先收集quorum个pre-commit vote消息,然后聚合出这一阶段的pre-commitQC,附带在commit消息中发送给其他节点。2)设置本地lockedQC为pre-commitQC。
从节点:收到commit消息时,消息验证通过同样更新本地的lockedQC为commit消息中的pre-commitQC,对其签名并生成commit vote并发送给主节点
??注意此时,主节点发送的commit消息附带的pre-commitQC即与PBFT中的第二轮COMMIT阶段共识类似,其中PBFT中该阶段共识表明了节点对的第一阶段达成共识这件事的共识,即确保了至少quorum个节点已经完成PREPARE阶段,在发生视图切换时,有足够多的节点能够证明对该提案达成了PREPARE共识,在新视图中提案内容需要被提交。
DECIDE阶段:
主节点:1)收集到quorum个commit vote消息时,聚合得到commitQC,并且附带在decide消息中发送给其他节点;
2)当其他节点收到decide消息时,其中commitQC指向的提案中的交易就会被执行;
3)之后增加视图号viewnumber,开启下一轮共识,根据prepareQC构造New-View消息。
从节点:验证消息后执行decide消息中commitQC指向的树节点的交易。
nextView interrupt阶段:在共识中任何其他阶段发生了超时事件,发送新视图的new-view消息,都会直接开启下一轮新的共识。
??注意,HotStuff中一笔交易从开始到提交进行了三轮共识,第三轮共识的加入,克服了经典两阶段范式的共识算法扩展的瓶颈。PBFT中为了保证系统在遇到恶意节点时能继续工作(活性),需要进行视图切换,而新视图中为了确定上一个视图中的区块是否达成共识,需要在view-change消息中附带自己收集到的quorum个prepare消息和相对应的一个pre-prepare消息作为证明,然后每个节点广播view-change消息请求视图切换,此时广播的消息复杂度o(n^2),消息的量级为o(n),因此视图切换的复杂度为o(n^3)。安全性和活性让PBFT需要o(n^3)的通信复杂度,对于网络的负载极大,限制了其向大规模网络的扩展。而HotStuff中如果我们对某一区块达成了两轮共识,在更换主节点时便能确定,主节点只需要基于最新的两轮共识节点产生新节点是安全的。换句话说,只需要根据区块自身的状态(经过几轮共识)就可以确定是否在新的视图中基于该区块打包块新区块,降低了在视图切换时候的通信复杂度。
▲?Chained HotStuff
可以发现在Basic HotStuff中的各个阶段流程都高度的相似,HotStuff的作者便提出了Chained HotStuff来简化Basic HotStuff的消息类型,并允许Basic HotStuff的各个阶段以流水线方式进行处理交易。
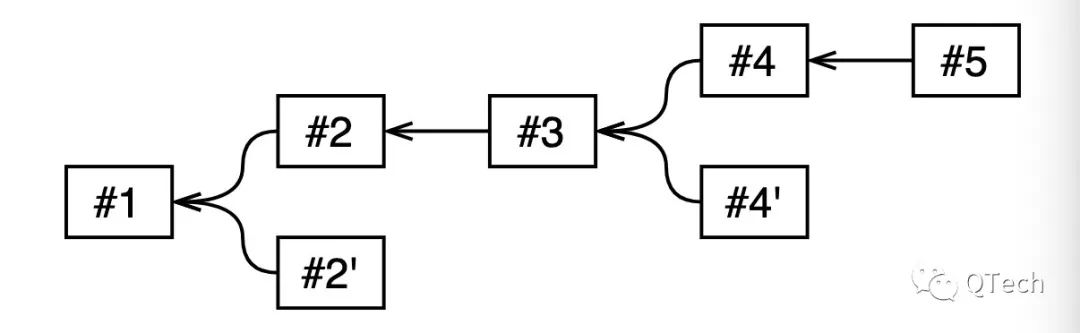
Chained HotStuff的流程如图:
从图中可以看出,每个阶段都会切换视图,因此每个提案都有自己的视图。节点对于不同的提案来说处在不同的视图上,PREPARE阶段的投票被当前视图的主节点合成QC,并转发给下一个视图的主节点,即下一视图在进行PREAPRE阶段的同时,也在进行上一个视图的PRE-COMMIT阶段。每个阶段具有类似的结构,视图v+1的PREPARE阶段可以看作是视图v的PRE-COMMIT阶段。视图v+2的的PREPARE阶段看作是视图v+1的PRE-COMMIT阶段和视图v的COMMIT阶段。v1中的cmd1将在视图v1,v2,v3中分别进行PREPARE、PRE-COMMIT、COMMIT阶段,在v4中就进行提交。cmd2以此类推。每个阶段的cmd提案产生将会附带上一阶段投票产生的QC。经过流水线简化版本的HotStuff工作过程如下:
主节点:1)等待NEW-VIEW消息,发出自己的提案;
2)等待其他节点进行投票;
3)向下一个主节点发送NEW-VIEW消息。
从节点:1)等待主节点的提案消息;
2)检查提案中的QC,更新本地highQC,lockedQC,发送投票;
3)向下一个主节点发出NEW-VIEW消息。
▲?Event-driven HotStuff
从Chained HotStuff到Event-driven HotStuff,实现原论文中将整个协议的安全性(safety)和活性(liveness)解耦开,活性成为单独的pacemaker模块。pacemaker模块保证了在全局稳定时间(GST)之后的活性。提供两个功能:
- 选择、校验每个视图的主节点。
- 帮助主节点生成提案。
换而言之,在如此低的视图切换代价下,pacemaker中可以采用任何合适的节点轮换机制,以及任何提案生成策略。
Event-driven Hotstuff与其他版本原理还是核心的三阶段共识,区别只是工程实现上的便利,具体可见论文伪代码[4]
—— ?HotStuff 之改进优化-NoxBFT ——
活性机制优化
活性机制是共识能够持续推进的关键。在原HotStuff论文中活性机制使用了一个全局一致的超时时间确定了视图超时。在NoxBFT中,我们设计了更灵活的机制应对网络环境的不稳定。
具体:每个节点进入新的视图后,根据配置等待超时时间,如果本视图未超时,则定时器时长不变。若超时,则不断广播TimeoutMsg,直到收到quorum个TimeoutMsg进入下一视图,此时定时器置为配置时间k倍,连续超时n次则置超时器为k^n倍。以此类推,这样避免在网络不稳定时频繁切换视图。
交易缓存池
在区块链的应用中,为避免交易丢失,我们设计了交易缓存池缓存客户端交易。共识模块主动拉取交易进行打包。交易池也可以减轻共识工作量,进行交易去重,我们通过交易内容hash标识交易,将已经执行的交易写入布隆过滤器,防止双花攻击,提升共识算法的稳定性。
快速恢复机制
不稳定的网络环境可能使共识节点丢失共识消息,导致节点落后。在HotStuff原论文中,作者将此部分具体实现留给了开发者。我们实现了工程可用的同步算法,让落后共识节点恢复定序功能,分为两步:
1)节点落后较多,直接向其他节点拉取区块执行恢复到最新检查点。
2)检查点之后的共识进度落后,向其他节点拉取最新的CommitQC快速恢复共识进度。
为提高效率,我们采取并行向不同节点拉取区块的机制,可以灵活配置并行度。并行拉取的区块先进行持久化再有序执行,同时记录各个节点拉取效率的分数,以便下次高效选取目标节点进行同步。整个过程可以以最快的速度拉取所有丢失的交易,减少整个过程的等待时间。
聚合签名
NoxBFT中实现并改进了Ed25519聚合签名算法。一方面通过编译预先计算的数据加速;另一方面,我们实现了大数类型专用的加速Ed25519的计算过程,压缩大数的存储。最终Ed25519算法要比官方快2.5倍,签名算法也实现了更高的性能。
总结
在BFT类的共识研究中,安全性的要求需要在视图切换时,主节点确保自己是基于最新的系统状态工作的,视图切换与系统状态的共识产生了o(n^3)的通信复杂度。而HotStuff通过增加一轮共识来解决,再结合门限签名降低了通信复杂度。不仅如此,流水线的工作方式,让算法变得足够简洁优雅,这与raft的工作方式相似,采取了先上链再共识,通过三轮共识之后再执行。这种链式的结构,不再区分每个阶段通信的意义(PBFT中prepare、commit),灵活的主节点更换的机制,在节点更换时不需要通信来确定最新共识的状态,对安全性与活性进行隔离,投票保证了安全性,pacemaker保证了其在网络异步时的活性。
作者简介
程泰宁 趣链科技基础平台部共识算法研究小组
参考文献
[1] Schneider F B . The state machine approach: A tutorial[J]. Springer New York, 1990.
[2] Lamport L , ?Shostak R , ?Pease M . The Byzantine Generals Problem[J]. ACM Transactions on Programming Languages and Systems, 1982, 4(3).
[3] Castro M, Liskov B. Practical Byzantine fault tolerance[C]. OSDI.1999, 99(1999): 173-186.
[4] Yin M , ?Malkhi D , ?Reiter M K , et al. HotStuff: BFT Consensus in the Lens of Blockchain[J]. ?2018.
[5] Shoup V . Practical Threshold Signatures[C]// International Conference on Theory & Application of Cryptographic Techniques. Springer-Verlag, 2000.


