构建一个计算机视觉项目
磐创AI你想创建一个应用程序来检测一些东西吗?猫和狗,检测水果的成熟程度,在图片中找到品牌?
如果你的答案是需要,那么这篇文章就是为你准备的!
将向你展示如何为你的探测器创建一个应用程序,并把它放到互联网上,让每个人都能看到。
你将能够上传一个测试图像,模型将返回预测框和标签。
免责声明:你需要在你的电脑中安装git才能将文件上传到HuggingFace Spaces。如果你没有,不要担心!安装起来很容易。
这将是项目的工作流程:

首先,你必须为你的项目收集图像。你想从长颈鹿中发现斑马吗?首先需要获取这两种动物的图像。无论你想检测什么,你都需要它的图像。这个点在工作流程中是白色的,这意味着你必须在你的计算机中完成工作。
标签图像在工作流中显示为蓝色,这是因为你将使用Datature的标签工具。Datature是一家专门为数据标签和模型训练构建用户友好工具的公司。
你还将使用Datature来训练模型。
一旦模型训练好了,你就把它下载到你的电脑上,把所有的文件放在一起(这些文件我会提供给你)
当所有文件放在一起时,你将把它们上传到HuggingFace Spaces,你的模型就可以使用了!
1.找到图片
在计算机视觉项目中,我们需要做的第一件事是收集图像。如果我们想要训练一个深度神经网络,我们需要成千上万张图像。
幸运的是,Datature使用非常先进的模型,而且可能是预训练的,这意味着如果我们从头开始训练模型,我们只需要需要的一小部分图像。
每个类大约有100个图像就足够了。例如,如果你想要检测t恤和裤子,你将需要100个t恤和100个裤子的图像。当然,这个例子也适用于其他情况。例如,你可以有100张猫和狗的图片,所以你可以有100张猫的例子,也可以有100张狗的例子。
如果有类不平衡是可以的,例如如果你的项目检测晴天和阴天,你可以有120张晴天的图片和100张阴天的图片。大约100张就足够了。
收集所有的图像并存储在你的计算机的一个文件夹中。
2.标记图像
在Datature中创建一个帐户,并为你的用例创建一个项目。
这篇博文详细介绍了如何:
创建Datature Nexus账户(免费试用)
创建一个项目
上传图片
创建类
注释图片
在图像中创建矩形框
为每个框分配一个类
对于每个图像,你将注释一个框(对象在哪里?)和一个类(对象是什么?)
只阅读标签部分,之后,在项目概述中,你应该看到你的图像统计,标签分布等。例如,项目概述应该是这样的:
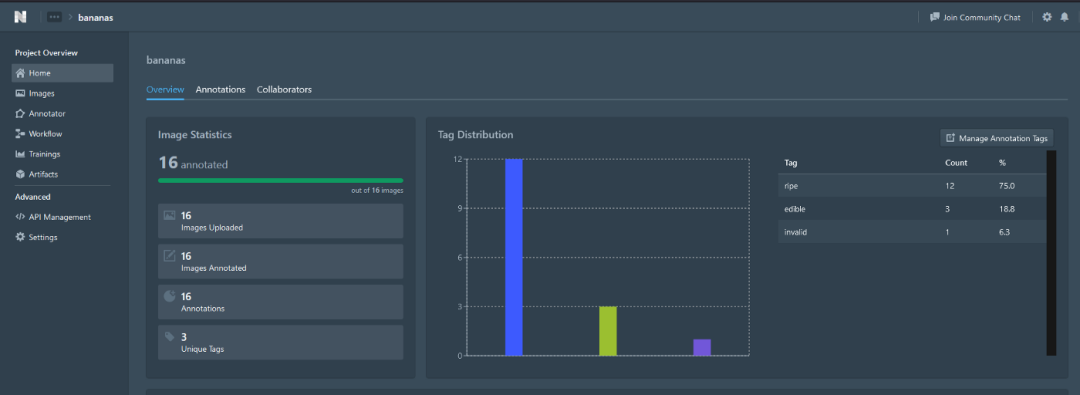
在这个例子中,我有一个名为香蕉的项目,我标记了16张图片,我有3类:成熟的、可食用的和无效的。这只是一个示例,所以请确保每个类至少有100个示例!
3.训练模型
一旦我们有了图像,我们就可以训练我们的模型了!我们将不得不在Nexus中创建一个“工作流”。
构建训练工作流程:选择训练-测试分割比,选择增强,选择模型设置
训练模型
监控模型:损失、精度、召回
导出模型
模型将需要大约1小时来训练,之后你应该看到这个

进入Artifacts并下载TensorFlow模型
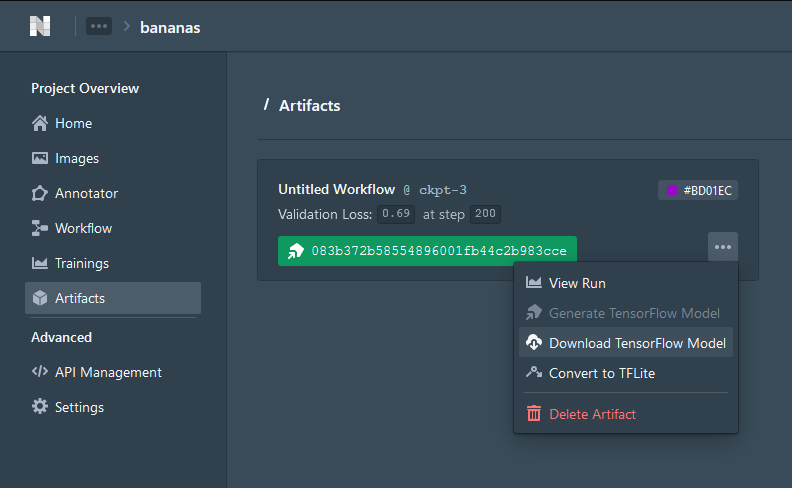
当计算机中导出了一个.zip文件时,这一部分就完成了。
4.创建一个HuggingFace帐户
模型是经过训练的,我们把它以.zip的形式下载到我们的电脑上。但我们如何与它交互呢?
我们可以通过上传照片到HuggingFace Spaces与它交互。我们还需要一些网站前端的代码。
Huggingface Spaces是Huggingface旗下的一个网站,人们可以在这里展示自己的模型,并与他们交互。
这些是创建步骤
1.创建Huggingface帐户
2.创建一个Space
3.为Space写一个名字。记住,这个网站将是公开的,所以选择一个与应用程序相匹配的名字!例如:香蕉分析或类似的东西
4.选择Streamlit作为空间SDK
5.选择public
6.Space使用完成后,将存储库克隆到本地计算机中的一个文件夹中
7.可选的README.md
5.收集所有文件并上传至HuggingFace空间
现在,我们的计算机中有了属于Space的文件夹。我们必须复制所有文件,并使用git将所有文件上传到Space。
首先,复制模型文件(saved_model/ folder, label_map.pbtxt)到文件夹
然后,在这个https://gist.github.com/anebz/2f62caeab1f24aabb9f5d1a60a4c2d25文件夹中创建3个文件
app.py
此文件包含用于上传图像、加载模型、进行预处理和从模型获得预测的代码。
注意那些带有#TODO的行,你必须修改它们!
特别是color_map,它们是每个类的方框的颜色。打开文件label_map.pbtxt查看给每个类分配了什么label_id,并使用这个label_id为颜色分配RGB值。
在这个例子中,我只有2个类,因此只有2种颜色。如果你有更多的类,按照示例的格式添加更多行:
1: [255, 0, 0],
记住,除了最后一行以外,每一行的末尾都应该有一个逗号!
import cv2
import numpy as np
from PIL import Image
import streamlit as st
import tensorflow as tf
from tensorflow.keras.models import load_model
# most of this code has been obtained from Datature's prediction script
# https://github.com/datature/resources/blob/main/scripts/bounding_box/prediction.py
st.set_option('deprecation.showfileUploaderEncoding', False)
@st.cache(allow_output_mutation=True)
def load_model():
return tf.saved_model.load('./saved_model')
def load_label_map(label_map_path):
"""
Reads label map in the format of .pbtxt and parse into dictionary
Args:
label_map_path: the file path to the label_map
Returns:
dictionary with the format of {label_index: {'id': label_index, 'name': label_name}}
"""
label_map = {}
with open(label_map_path, "r") as label_file:
for line in label_file:
if "id" in line:
label_index = int(line.split(":")[-1])
label_name = next(label_file).split(":")[-1].strip().strip('"')
label_map[label_index] = {"id": label_index, "name": label_name}
return label_map
def predict_class(image, model):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, [150, 150])
image = np.expand_dims(image, axis = 0)
return model.predict(image)
def plot_boxes_on_img(color_map, classes, bboxes, image_origi, origi_shape):
for idx, each_bbox in enumerate(bboxes):
color = color_map[classes[idx]]
## Draw bounding box
cv2.rectangle(
image_origi,
(int(each_bbox[1] * origi_shape[1]),
int(each_bbox[0] * origi_shape[0]),),
(int(each_bbox[3] * origi_shape[1]),
int(each_bbox[2] * origi_shape[0]),),
color,
2,
)
## Draw label background
cv2.rectangle(
image_origi,
(int(each_bbox[1] * origi_shape[1]),
int(each_bbox[2] * origi_shape[0]),),
(int(each_bbox[3] * origi_shape[1]),
int(each_bbox[2] * origi_shape[0] + 15),),
color,
-1,
)
## Insert label class & score
cv2.putText(
image_origi,
"Class: {}, Score: {}".format(
str(category_index[classes[idx]]["name"]),
str(round(scores[idx], 2)),
),
(int(each_bbox[1] * origi_shape[1]),
int(each_bbox[2] * origi_shape[0] + 10),),
cv2.FONT_HERSHEY_SIMPLEX,
0.3,
(0, 0, 0),
1,
cv2.LINE_AA,
)
return image_origi
# Webpage code starts here
#TODO change this
st.title('YOUR PROJECT NAME')
st.text('made by XXX')
st.markdown('## Description about your project')
with st.spinner('Model is being loaded...'):
model = load_model()
# ask user to upload an image
file = st.file_uploader("Upload image", type=["jpg", "png"])
if file is None:
st.text('Waiting for upload...')
else:
st.text('Running inference...')
# open image
test_image = Image.open(file).convert("RGB")
origi_shape = np.asarray(test_image).shape
# resize image to default shape
default_shape = 320
image_resized = np.array(test_image.resize((default_shape, default_shape)))
## Load color map
category_index = load_label_map("./label_map.pbtxt")
# TODO Add more colors if there are more classes
# color of each label. check label_map.pbtxt to check the index for each class
color_map = {
1: [255, 0, 0], # bad -> red
2: [0, 255, 0] # good -> green
}
## The model input needs to be a tensor
input_tensor = tf.convert_to_tensor(image_resized)
## The model expects a batch of images, so add an axis with `tf.newaxis`.
input_tensor = input_tensor[tf.newaxis, ...]
## Feed image into model and obtain output
detections_output = model(input_tensor)
num_detections = int(detections_output.pop("num_detections"))
detections = {key: value[0, :num_detections].numpy() for key, value in detections_output.items()}
detections["num_detections"] = num_detections
## Filter out predictions below threshold
# if threshold is higher, there will be fewer predictions
# TODO change this number to see how the predictions change
confidence_threshold = 0.8
indexes = np.where(detections["detection_scores"] > confidence_threshold)
## Extract predicted bounding boxes
bboxes = detections["detection_boxes"][indexes]
# there are no predicted boxes
if len(bboxes) == 0:
st.error('No boxes predicted')
# there are predicted boxes
else:
st.success('Boxes predicted')
classes = detections["detection_classes"][indexes].astype(np.int64)
scores = detections["detection_scores"][indexes]
# plot boxes and labels on image
image_origi = np.array(Image.fromarray(image_resized).resize((origi_shape[1], origi_shape[0])))
image_origi = plot_boxes_on_img(color_map, classes, bboxes, image_origi, origi_shape)
# show image in web page
st.image(Image.fromarray(image_origi), caption="Image with predictions", width=400)
st.markdown("### Predicted boxes")
for idx in range(len((bboxes))):
st.markdown(f"* Class: {str(category_index[classes[idx]]['name'])}, confidence score: {str(round(scores[idx], 2))}")
packages.txt:
ffmpeg
libsm6
libxext6
requirements.txt:
numpy==1.18.5
opencv-python-headless
Pillow==7.2.0
streamlit
tensorflow==2.3.0
packages.txt和requirements.txt是将安装在Space中的库。这些文件非常重要,没有它们,代码将无法运行。
最后,文件夹应该像这样
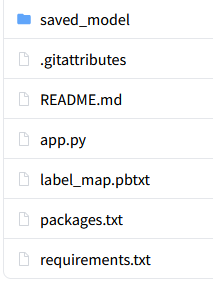
saved_model/是你先前从Datature下载的.zip文件中的文件夹
label_map.pbtxt存在于.zip文件
.gitattributes
README.md
app.py是用我在本文前面编写的代码创建的文件
requirements.txt在前面的代码中提供
packages.txt在前面的代码中提供
一旦我们需要的所有文件都在文件夹中,我们可以将其推送到Space。打开Git Bash,依次粘贴以下命令:
git add .
git commit -m “Added files”
git push
app上传文件需要一些时间,尤其是模型文件。git推送完成后,Space将花费几分钟来构建应用程序,并在Space中显示我们的应用程序。
最后,你的应用会显示如下:https://huggingface.co/spaces/anebz/test
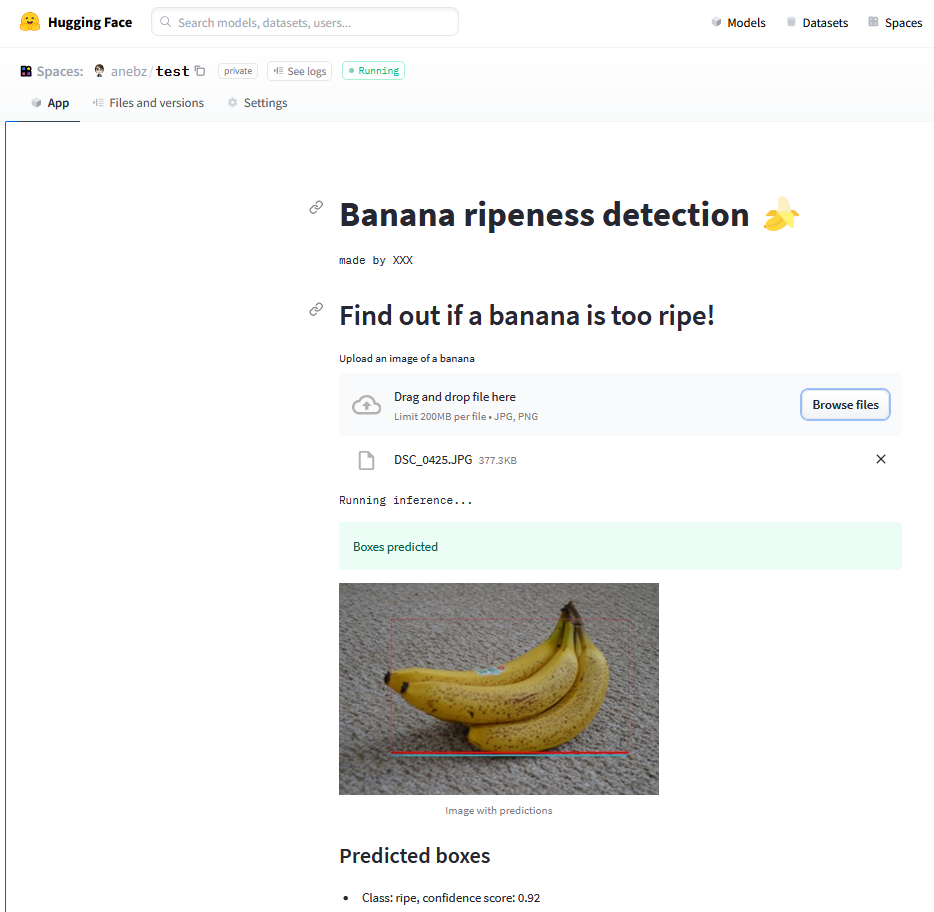
你可以上传一张图片,模型需要几秒钟来加载,然后你就可以看到预测结果了。项目完成了!
结论
你的项目完成了,祝贺你!!你可以从零开始快速创建一个应用程序。你只需要在你的电脑上安装Git,不需要Python或者不需要编写任何代码。
