OpenAI内斗这几天,竞争对手一刻也没闲着
雷科技
过去几天,作为新一轮 AI 浪潮的领头羊,OpenAI 面临一次的分崩离析的重大危机,从董事会宣布辞退创始人兼 CEO Sam Altman,到回归又被否,期间还经历了多次反转,包括 Altman 加入微软、员工逼宫、与 Anthropic(Claude)合并等。
到了北京时间 11 月 22 日下午,OpenAI 又表示原则上同意 Altman 重返 OpenAI 担任 CEO,并组建新一届董事会,具体细节还在敲定中。
在事情还没有正式敲定前就公开披露,可见现任董事会也明白 OpenAI 急需「稳定军心」,否则竞争对手还会继续「掏空」OpenAI。紧随官方之后,Sam Altman 以及之前刚辞任的总裁 Greg Brockman 也都发布了一条暗示回归 OpenAI 的推文,不管初衷如何,实质上也确实起到了「稳定军心」的作用。
OpenAI 总裁 Greg Brockman,图/ X
根据此前公开报道,包括 X(Twitter)、微软、谷歌、Anthropic 以及一大批有志于这一轮 AI 浪潮的公司都在重金挖角 OpenAI 员工,而很多 OpenAI 员工也在考虑跳槽事宜,这显然也会严重影响到 OpenAI 原定的一系列计划。
与此同时,竞争对手们也不只是「围观看戏」,还希望抓住 OpenAI 犯错的机会,加快推陈出新的节奏,加速赶超 OpenAI。
Token翻倍、「幻觉」减弱,Claude 2.1终于来了
就在同一天,从 OpenAI 分化出来又背靠谷歌的 Anthropic 发布了新的聊天机器人——Claude 2.1。
作为 ChatGPT 最有力的竞争者之一,Claude 2 原本就在上下文长度和语言理解上有一定的优势,同时还较早支持了链接和文档读取能力。在 Claude 2.1 上,更是将最大支持 Token 数量从 10 万个增加到了 20 万个,远高于 ChatGPT 的最大 3.2 万个 Token。
Token 相当于机器视角的「字数」。
经常使用 ChatGPT 或者类似聊天机器人的读者应该都知道,如果在上下文窗口内,一旦对话长度超过了 Token 限制,上下文窗口就会发生变化,聊天机器人会丢失早期对话的内容,等于忘记了之前的对话背景,会直接影响到后面的回答。
甚至不需要超出 Token 限制,只要对话长度到一定阶段,机器就会开始遗忘早先的一些背景和要求,需要重复提醒。

图/ Anthropic
而 20 万个 Token 的长度,意味着将近 270 页文档的上下文和更强的「记忆容量」。换言之,Claude 2.1 用户现在可以上传整个代码库等技术文档、S-1 等财务报表,甚至是《伊利亚特》或《奥德赛》等长篇文学作品。
通过能够与大量内容或数据进行交互,理论上 Claude 2.1 可以更好地进行总结、执行问答、预测趋势以及对比多个文档等。AI 创业者兼开发者 Greg Kamradt 在测试中,确实发现了 Claude 2.1 在性能上的进步。
此外,Claude 2.1 在对抗大模型「幻觉」方面也取得了一定进步。与之前的 Claude 2.0 模型相比,Claude 2.1 虚假陈述的概率降低了 2 倍。
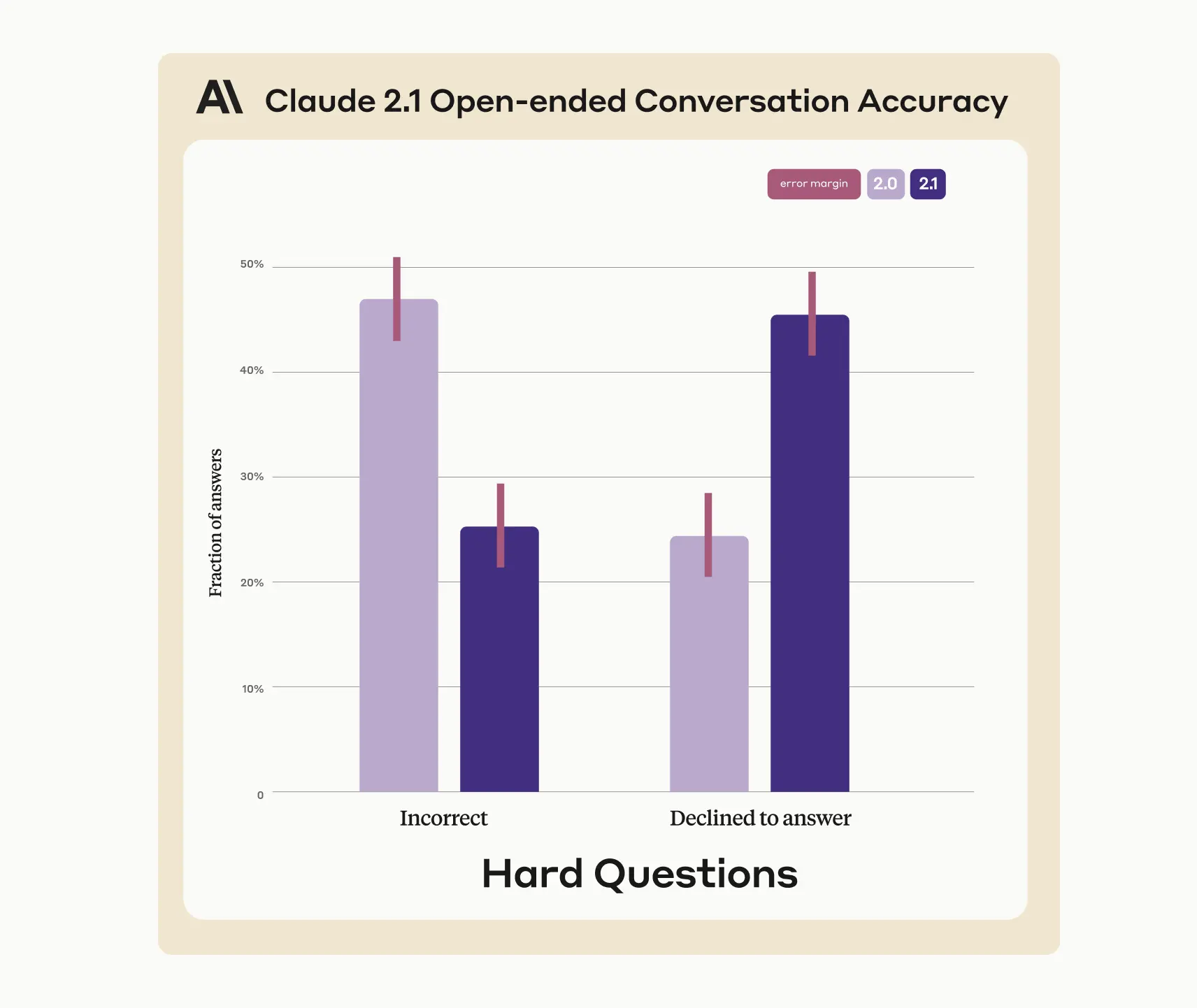
图/ Anthropic
根据 Anthropic 的说法,他们设置了大量复杂的事实问题进行测试,测试显示 Claude 2.1 在面对错误信息以及不确定信息时更可能提出异议,而不是提供不正确的信息。比如反驳用户给出的「玻利维亚人口第五多的城市是蒙特(错误信息)」,或是承认「我不确定玻利维亚人口第五多的城市是什么」。
这使企业能够构建高性能的人工智能应用程序,解决具体的业务问题,并以更高的信任度和可靠性在其运营中部署人工智能。
视频版Stable Diffusion发布即开源,再一次改变视频生成?
文本生成领域有 ChatGPT 和 Claude,图像生成领域有 Midjourney 和 Stable Diffusion,但在视频生成领域始终没有一个模型可以跑出。

AI 生成视频(动图经过压缩),图/ Meta
这不是说没有公司尝试,谷歌、Meta 很早就有公布 AI 生成视频的 Demo,还有大量初创团队都在「掘金」视频生成领域,比如 Runway 就接连发布了 Gen-1、Gen-2 两代,实现了真正的从零开始生成视频。当然,Gen-2 仍然存在细节模糊、形态扭曲等等品质问题,所以始终没能破圈。
Stable Video Diffusion 会改变一切吗?
还是北京时间 11 月 22 日,Stable Diffusion 背后的公司 Stability AI 发布了旗下首个视频生成模型——Stable Video Diffusion。
在很多人的意料之中,Stable Video Diffusion 基于图片生成模型 Stable Diffusion 进行开发而成,Stability AI 已经在 Github 上开源了全部代码,同时也上线了 Hugging Face 社区。
图/ Github
要指出的是,目前 Stable Video Diffusion 有两种输出形式,能以每秒 3 到 30 帧的可定制帧速生成 14 和 25 帧。换句话说,Stable Video Diffusion 目前最多也只能生成 8 秒左右的低帧率视频。

图/ AssemblyAI
但不要低估开源迭代的力量。Stable Diffusion 模型 2022 年最开始发布的时候,图片生成质量也比不上 OpenAI 的 DALL·E-2。然而由于开源的策略,Stable Diffusion 被各路初创公司、开发者、玩家频繁应用与改进,最终让 AI 生成图片彻底火出圈外,引发了一系列的变化。
同时在开源力量的帮助下,不到半年内 Stable Diffusion 模型就迭代到了 2.1 版本。
诚然,Stable Diffusion 的成功未必能够复刻,但可以肯定的是,不同于 Gen-2 这类私有模型,Stable Video Diffusion 可以聚集开源社区更多的开发力量,加速视频生成模型的迭代改进。
生成式 AI,从来不只是 OpenAI
11 月 15 日,Sam Altman 在还没有被董事会辞退之前就在 X(Twitter)上表示,OpenAI 将暂停新的 ChatGPT Plus(付费)用户注册,原因是使用量的激增已经超出了自身的承受能力。直到 11 月 22 日,OpenAI 依然还没有开放 Plus 用户注册。
但与此同时,AI 时代的浪潮还在滚滚向前,Claude 2.1 和 Stable Video Diffusion 的发布之外:
- 谷歌 DeepMind 在最新发布的音乐生成模型中采用了人耳听不见的「水印」;
- 微软发布仅 130 亿参数规模的「大」模型,官方宣称其性能比起 700 亿参数的 Meta Llama-2 Chat 还要好;
- 在下个月举行的 re:Invent 大会上,亚马逊云(AWS)预计也会重点介绍旗下 Olympus 大模型的能力。

图/谷歌
今年还有一个可能是最值得期待的大模型——谷歌 Gemini。根据此前半导体研究机构 SemiAnalysis 的报道,谷歌下一代大模型 Gemini 的算力高达 GPT-4 的 5 倍,同时谷歌手握自研 TPUv5 的数量比 OpenAI、Meta、Coreweave、甲骨文以及亚马逊拥有的 GPU 加起来还多。
在此基础上,Gemini 还整合使用了强化学习和树搜索的 AlphaGO,以及机器人、神经科学等领域的技术,拥有语言和视觉两大能力。OpenAI 的首席科学家 Ilya Sutskever 在 2020 年就表示,仅文字就可以表达关于世界的大量信息,但它是不完整的,因为我们也生活在视觉世界中。
说到底,生成式 AI 从来不只是 OpenAI 一家公司,不论围绕 OpenAI 的「大戏」结局会走向何处,都挡不住 AI 大潮的来势汹汹。
来源:雷科技
