或许,更多的机会在于中国的大语言模型生态
躺平指数相信这两天,很多人都注意到了这样一条新闻:
苹果公司上周阻止了一款使用ChatGPT功能的电邮应用的更新,因为担心其可能生成不适合青少年儿童的内容。
除了苹果之外,还有许多美国科技圈大佬表达了对ChatGPT生成内容的担忧。
这也表明,就算是在对内容相对宽松的美国,依旧会对生成式AI顾虑重重,即便ChatGPT克服重重困难最终进入中国,也必然面临不同文化不同语境之下“水土不服”的问题。
因此,中国必须有自己的ChatGPT——“大语言模型”。
进而,也必然会基于大语言模型产生自己的生态。不过,需要强调的是,虽然在ChatGPT爆火之后,出现了太多创业公司入局的消息,但从本质上,ChatGPT考验的是资金、数据和人才等硬性资源。不说后两者,训练一次的成本就在200万至1200万美元之间,没有雄厚的资金和技术积累,创业公司根本玩不转。
即便是对像百度(NASDAQ:BIDU)这样的巨头来说,对于即将在3月16号发布的文心一言,如果使用体验能与去年11月份刚上市的ChatGPT刚上市相当,就已经足够了。更重要的是,只要产品发布了,数据、query闭环起来后就能够快速迭代。
但凡能够做到有一个月甚至两个月的领先,文心一言就能把先发优势转化成规模优势,进而快速具备商业化的潜力和前景。
之前,我们在文章里有提到过供给驱动的产业模式和需求驱动的产业模式。
这两者在任意其一做到优秀,都可行,只不过前者赚钱的hard程度更低。因为,经济增长短期靠需求,长期靠供给,供给在每一个行业都起到最终大boss的作用。
很明显,以百度文心一言为代表的大语言模型将引领以供给驱动模式的产业发展。
更重要的是,围绕文心一言产生的应用场景,能够把过去一段时间死气沉沉的互联网模式创新企业再度激发出来,这是移动互联网时代已经被成功验证的创业路径,将会在如文心一言等模型发布之后,再度搅动资本市场。
“玩不转”大模型的创业公司,大可不必玩,因为真正的商业蓝海,在生成式AI后续的应用开发,这是中国公司最擅长的,也是中国市场最大的优势所在:中国拥有从一线城市到十八线乡村,市场纵深广阔;14亿人口对应的就是庞大的数据量,丝毫不会弱于英文语言区域,对AI的帮助巨大;在巨大的人口基数之上,中国应该是全球基础教育普及程度最高的国家,没有之一。
这三大因素决定了,即便是在技术上产生微小的创新,只要能够在商业应用方面进行模式创新,就可以迅速产生经济价值,并有相当广阔的市场空间和用户基础进行迭代。
重资金重技术的大模型,交给实力雄厚的大厂们就好;相比立志自己去做大模型的创业公司来说,真正的机遇将会在应用侧。
中国生成式AI目前能够覆盖的应用场景包括:文本、音频、图片和视频等领域。文本作为NLP 模型的核心,应用范围最广自然不必多提。
仅以图片为例,AI生成的图片可以大面积满足B端和C端的需求,替代需要人工制作或是购买版权的图片,以中国目前庞大的商业生态来说,这意味着一个非常广阔的市场。
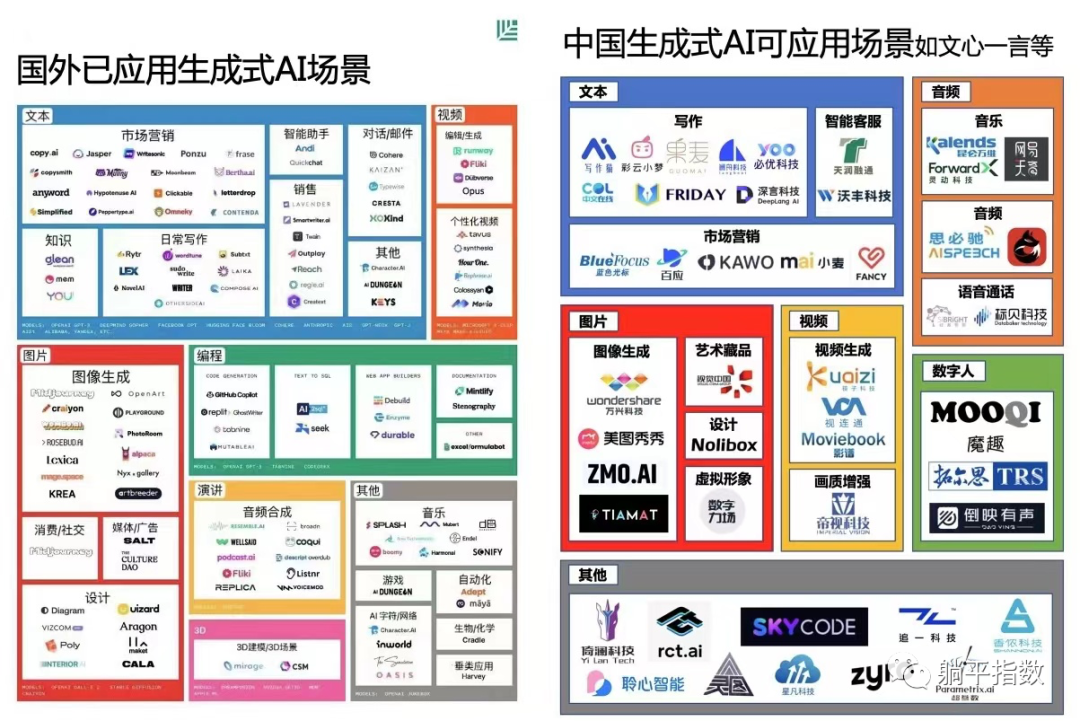
当然,庞大的应用生态又会反哺像文心一言这样的大模型。只有扎根在一个创新活跃、市场广阔的生态中,才会获得良好的市场汇报,进而支撑巨大的训练和线上运营成本。目前,百度已宣布将开放文心一言大模型,支持更多企业构建自己的模型和应用。
这也意味着,更多企业能够以更低的门槛将大语言模型技术引入实际业务中去,换一种方式吃到这波技术红利。再加上百度自身拥有的生态体系,文心一言具备的潜力可想而知。
声明:本文仅用于学习和交流,不构成投资建议。
