玩疯了的ChatGPT不止AIGC,Maas或成为下一个增长大爆发?
算力智库ChatGPT被玩疯了!
12月1日,OpenAI发布了一个NLP(自然语言识别)的新模型ChatGPT,该模型是OpenAI在2020年推出的NLP预训练模型——GPT-3的衍生产品,不仅可以完成对答、写剧本、写代码等各项功能,还可以创作诗歌和笑话,就连马斯克也在感叹“很多人疯狂地陷入了ChatGPT循环中”,“ChatGPT 好得可怕,我们离强大到危险的人工智能不远了”。

TED负责人Chris更是对纽约时报没有报道ChatGPT表示震惊,ChatGPT在引起全网热情“调戏”的同时,也被业内公认为是NLP及人工智能领域具有重要意义的一款模型。
小编也上手把玩了一下,没想到ChatGPT写起小说来也相当强悍,其生成故事的流畅度和逻辑性堪比人类。

ChatGPT爆火的背后除了是AIGC(AI Generated Content)的故事,但不可忽视的一个更重要的推手是以Generative Pre-trained Transformer3(GPT-3)为代表的AI大模型的崛起,大模型的力量让工业级AI的“奇点”越来越逼近。
大模型的魅力:工具的复利???????
就像熟食的出现,让厨艺不精的人,解决了做菜的难题,只要回家再二次烹饪一下,便可成为一顿美味佳肴,谁又在乎前面98%的步骤都是在餐厅完成的呢?
工具或产品的本质目的,是面向生产力的解放和升级,衡量一个工具生命力的重要指标是其能否产生复利效应,只有具备遍及性、普惠性、规模化、通用能力的工具才能得以流行,开启一个产业级生态甚至是一个时代。
AI大模型的走热,是工具爆发周期规律的使然。
曾投资过Uber、Robinhood的著名天使投资人Jason,这个月在他的播客问答中,谈到工具爆发的周期,他总结到:阶段一是爱好者的工具,比如说以前图片爱好者用Photoshop处理图片,但是大部分人是不会用PS的,因为学起来非常困难;阶段二是从爱好者的工具到普通人的工具,比如说从PS到美图秀秀,这个阶段工具的使用难度大大降低;阶段三是从普通人的工具到平台,这个是真正突破性的,是最需要商业想象力和商业直觉的,比如说从美图秀秀,到Instagram,现在你可以直接在社交平台P完图分享到你的社交网络;最后是从平台成为行业。
而AI也正在经历类似的历程。
不可否认,到了2022年,依然可以看到大部分云计算和AI供应商无暇去高权重的投入AI的应用场景和应用可行性,而是专注于另一个关键词:成本。
一如商汤科技联合创始人扬帆曾表示:AI替代人工,表面上是个需求问题,但实际上是个成本问题。
虽然人人都知道手磨咖啡好喝,但让每个人都去磨咖啡显然不现实。
回到云计算和AI服务提供商这边,虽然面向企业卖AI理论上潜力巨大,但每家客户都有大量需要定制解决的需求,往往要投入众多行业专家、算法架构师、软硬件工程师来解决一些小问题。这样做出来的成果虽然可观,但其实只具备案例性质,缺乏推广可能。
另一方面,中国与欧美截然不同的生存土壤和To B环境,让中国式AI走向高度工业化的愿景和需求更为强烈,一个显见的区别就是欧美的AI to B市场净值较高,客户数字化能力较强,他们的AI面对的客群,更多是大规模、分散式的企业软件市场,而中国的AI目标用户则更多是政企、实体经济企业,数字化能力参差不齐,需要一对一的AI能力和通用化的AI解决方案,可以说,低成本的AI工业化,已成为目前中国AI产业的主线任务。
而AI大模型的出现,或成为AI工业化的最佳解,其可重复利用的通用能力,正踩在了工具爆发周期的前站,开启了从作坊式的人工智能迈向通用智能的里程碑。
那么AI大模型是什么?
AI大模型就是Foundation Model(基础模型),指通过在大规模宽泛的数据上进行训练后能适应一系列下游任务的模型。即以“预训练大模型+下游任务微调”的方案,直接在海量通用的、无标注的数据上自监督训练,捕获知识,通过将知识存储到大量的参数中并对特定任务进行微调,从而提高模型的泛化能力和通用问题求解能力。
简而言之,大模型就相当于“熟制品”,企业买回去,进行二次加工,从而可以生成自己想要的AI能力,其在大数据集训练的预训练模型上再完成小数据的迁移,最终在企业用户时间、人力成本的平衡的基础上,保证了模型的精度和使用效果,这种大模型预训练的逻辑成为了工业级AI的核心思路之一,让AI变得像齿轮、轴承、钢筋一样,成为标准化、规模化、流程化、低成本的产物。
就像速泡茶包和传统烹茶一般,传统烹茶满足了精致主义者和钟爱品茶人士的味蕾,但只有看似不够高端、廉价的速泡茶包才能飞入寻常百姓家,同样也凝聚了制茶工艺的精髓,而中国AI要做的,就是炮制出这样方便快捷、标准化的速泡茶包。
AI大模型“先富带后富”
三类厂商成受益者??????????
在未来,人工智能所期盼的终极图景,就是像供水供电一样流向终端,流向用户、流向企业,谁能先做到这点,谁就会在AI 产业布局中获得先发优势。
在发力大模型这一选择上,巨头们便是抱着这一信念,赌一次,赌对了,就值了。
于是,AI大模型军备竞赛开始打响,国外有谷歌、微软、Meta,国内有华为、阿里、百度、浪潮等企业均下场参战,模型平均参数上百亿。
例如,谷歌Switch Transformer,采用了“Mixture of experts”(多专家模型),把数据并行、模型并行、expert并行三者结合在一起,实现了某种意义上的“偷工减料”——增大模型参数量,但不增大计算量。
再例如,浪潮发布的“源1.0”,参数规模2457亿,采用了5000GB中文数据集,是一个创作能力、学习能力兼优的中文AI大模型。据开发者介绍,由于中文特殊的语言特点,会为开发者带来英文训练中不会遇到的困难。这意味着,想要做出和GPT-3同样效果的中文语言模型,无论是大模型本身,还是开发者,都需要付出更大的力气。
而且巨头们大多不止一个基础模型,从自然语言模型,到视觉模型,再到多模态模型,AI大模型的天花板越来越高。
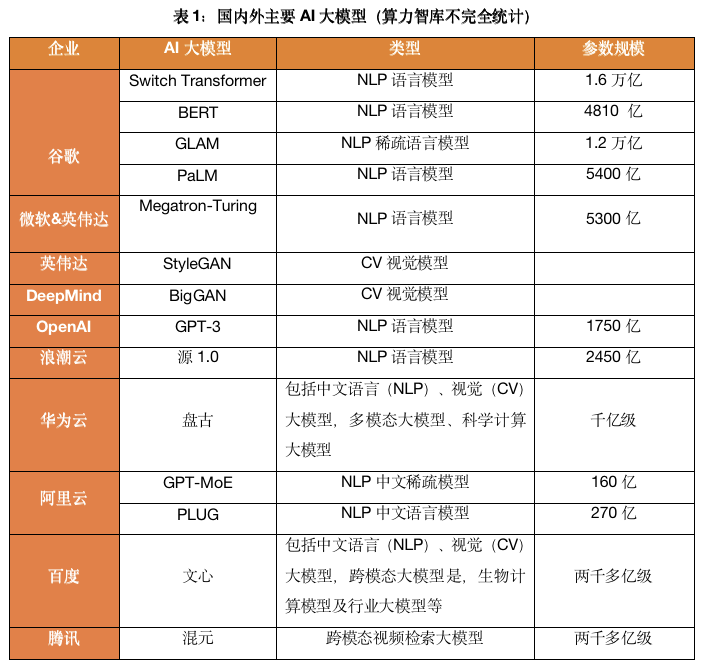
不难发现,涉及万亿级参数、拥有“巨量数据、巨量算法、 巨量算力”三大特征的AI大模型是一项门槛很高的技术竞赛,只有科技巨头才有实力研发工业级别的AI大模型,然后科技巨头再开放给各行各业的开发者,这种“先富带后富”的路子正是AI大模型的落地方式,在落地的前半段赛程,科技巨头们成为“饮头啖汤”者。
云计算厂商、AI芯片巨头和数据密集型巨头将会这一波AI大模型化浪潮的核心受益者,大模型带来 AI 底层基础技术架构的统一,以及对算力的庞大需求等特征,天然有利于云计算公司在此过程中发挥基础性角色,云计算具有全球分布最为广泛、最为强大的硬件算力设施,同时 AI 框架、通用算法最为一种典型 PaaS 能力,亦倾向于被整合到云厂商的平台能力当中。因此从技术通用性、实际商业需求等维度,在大模型的推动下,云计算巨头有望逐步成为算力设施+基础算法框架环节能力的主要提供商。
而AI芯片巨头的算力能力是天然护城河,既可以支持自研模型,也可以成为大模型厂商的供应商,卖算力,两边通吃,而坐拥独特专用数据的数据密集型巨头,如微信掌握的社交数据,腾讯视频的视频数据,阿里淘宝掌握的购物数据,在行业大模型的训练上,具有得天独厚的优势。
Maas或成为下一个增长大爆发
目前来看,巨头们狂练AI大模型,一部分是为了卖,另一部分主要是基于反哺自身的产品和业务线,比如腾讯的混元模型,是为了优化营销全链路,帮助广告主促成交易达成,为其带来更高效的投放转化效果,微软的大模型是用在Office套件上,谷歌的BERT模型也是为了优化搜索引擎的搜索准确性。
尽管,在现有AI大模型的商业结构中,“卖”的比重并不高,但或许可以期待下,在AI工业化推广的刚需下,在AI能力成为企业IT基础设施标配的趋势下,Maas模式(Model as a service,模型即服务)作为新兴商业模式的爆发可能性,除了开源,Maas将是AI走向普惠的最有可行性和网络效应的第二条路,国外有“huggingface”,而中国的“huggingface”或许要从Maas的探索中诞生,无论是结合Paas模式,整合为大平台,还是以产品形式单点输出,复制Saas的企服路线,中国企业、研发人员们为AI模型的付费能力是不容小觑的。
