一文了解如何使用内存池数据进行 UX 研究,改善 NFT 拍卖体验
Skypiea用户体验 (UX) 描述了人们在与系统或服务交互时的感受,包括多个因素,包括可用性、设计、营销、可访问性、性能、舒适度和实用性。唐诺曼曾经说过,
“万物皆有个性;一切都发出了情感信号。即使这不是设计师的本意,浏览网站的人也会推断出个性并体验情感。糟糕的网站具有可怕的个性,通常在不知不觉中向用户灌输可怕的情绪状态。我们需要设计东西——产品、网站、服务——来传达任何想要的个性和情感。”
以太坊的个性是一个极其高深莫测且容易被误解的人。更糟糕的是,大多数用户在使用您的界面或钱包时甚至不会将其视为与以太坊进行交互。如果你曾经在 Artblock 拍卖的实时聊天中,你会注意到拍卖一结束,至少有十几个人抱怨他们没有抢到份额是 Metamask 的错。我认为在过去的一年里,以太坊上许多 dapp 的用户体验在产品交互和交易的可解释性方面都有了很大的改进。在大多数情况下,dapps 不再只是在您签署交易后给您留下一个加载微调器。
即使 dapps 的设计总体上在改进,但我不确定 UX 研究的深度。当我看到对各种协议的数据分析或研究时,用户大多被视为同质的。根据我所看到的 Uniswap V3 流动性提供商和 Rabbithole Questers 的一些分析,这种情况有所改变,但即便如此,这些分析仍主要集中在刚刚确认的链上交易上。根据我自己的经验,大多数情绪诱发和行为怪癖发生在我提交、等待、加速或取消交易时。对于某些应用程序,用户可能会在提交交易后离开并去做其他事情。但是对于像 Artblock 的拍卖这样的产品,他们会一直待到确认发生为止,可能会检查所有可能的更新并增加焦虑。
我认为通过开始更多地利用内存池(mempool),我们可以更好地理解用户行为和摩擦。内存池是节点临时存储未确认交易的地方。这意味着如果您提交、加速或取消您的交易,那么这些操作将首先显示在内存池中。需要注意的是,来自内存池的数据并未存储在节点中,因此您无法像查询已确认交易那样查询历史数据。从这里,您可以看到他们提交了一些交易,将交易加速了很多次,但远未达到所需的 gas 价格,最终在 20 个区块后看到了确认。我相信这是用户体验和他们在整个过程中可能感受到的情绪的一个很好的代表。如果我们了解不同用户群体在这个循环中的行为,我们就可以弄清楚如何补充他们的决策或缓解他们的焦虑。据我所知,几乎只有以太坊基金会、所有核心开发人员和一些钱包团队出于用户体验的原因利用内存池数据。
用户体验研究论文:通过随着时间的推移通过拍卖查看用户的行为以及他们的钱包历史,我们可以开始为不同的用户群体提供行为身份。从这里,我们可以确定要尝试缓解的主要问题。为此,我们将使用 Blocknative 获取一个月的 Artblocks Auctions 数据,并使用 Dune 查询对这些地址的历史进行分层。
这篇文章将比我之前的一些文章更具技术性,因为我相信这项工作可以而且应该很容易推广。我想强调的是,我的背景不是用户体验研究,我纯粹是在尝试我认为加密原生用户体验研究的样子。
数据来源和预处理所有拍卖数据
如果你对技术位不感兴趣,请跳到下一节——关于特征工程
Blocknative 和 Mempool 数据流
使用 Blocknative 的 Mempool 浏览器,您可以过滤提交给特定合约或来自特定钱包的交易。就我而言,我想听听 Artblock 的 NFT 合约列入白名单的铸币合约。您可以在此处找到我使用的流,如果您想使用完全相同的设置,请将其保存下来。
您可以在其子图?中使用以下查询找到列入白名单的铸币地址:
{
contracts(first: 2) {
id
mintWhitelisted
}
}
获得所有购买的订阅过滤器需要三个步骤:
- 使用“创建新订阅”按钮添加新地址
- 单击地址旁边的“ABI”按钮添加 ABI。 就我而言,我只需要“购买”功能。
{
"inputs": [
{
"internalType": "uint256",
"name": "_projectId",
"type": "uint256"
}
],
"name": "purchase",
"outputs": [
{
"internalType": "uint256",
"name": "_tokenId",
"type": "uint256"
}
],
"stateMutability": "payable",
"type": "function"
}3. 为 methodName 匹配购买添加过滤器(确保您没有执行全局过滤器)
最后,您的设置应如下所示:
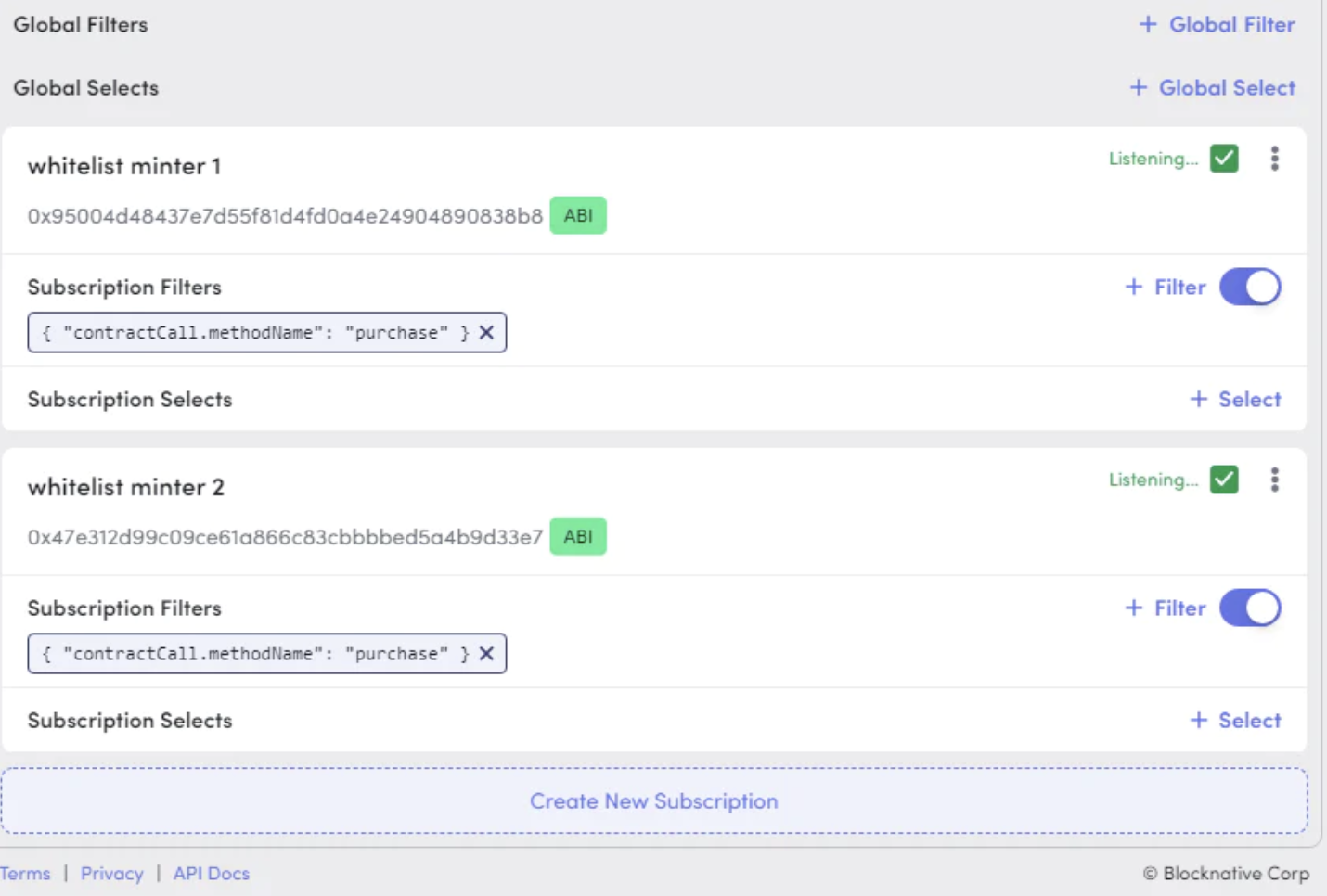
为了存储这些数据,我创建了一个 ngrok/express 端点来存储在本地运行的 SQLite 数据库中。我创建了一个 GitHub 模板?,其中包含复制此设置的步骤。可能这里要记住的最重要的一点是,在 Blocknative 帐户页面中将 POST 端点添加为 webhook 时,您需要将 POST 端点作为 ngrok URL 的一部分。
关键预处理函数
多个交易哈希
当您加速或取消交易时,原始交易哈希将替换为新交易。这意味着如果您想在其整个生命周期中跟踪用户的交易,您需要将新交易哈希与原始交易哈希进行协调。假设您将交易加速五次,您将拥有总共六个哈希值(原始哈希值 + 五个新哈希值)。我通过将 tx_hash 的字典映射到新的 replaceHash 来调和这一点,然后递归替换。
replaceHashKeys = dict(zip(auctions["replaceHash"],auctions["tx_hash"])) #assign tx_hash based on replacements, just to keep consistency.
replaceHashKeys.pop("none") #remove none key
def recursive_tx_search(key):
if key in replaceHashKeys:
return recursive_tx_search(replaceHashKeys[key])
else:
return key
auctions["tx_hash"] = auctions["tx_hash"].apply(lambda x: recursive_tx_search(x))区块编号问题
删除的交易的区块号为 0,所以为了解决这个问题,我按时间戳按升序对数据帧进行排序,然后进行向后填充,这样 0 就会被它放入的正确区块号替换。这是功能的重要修复工程。
auctions = auctions.sort_values(by="timestamp",ascending=True)
auctions["blocknumber"] = auctions["blocknumber"].replace(to_replace=0, method='bfill') #deal with dropped txs that show as blocknumber 0在主要拍卖期间处理铸造
对于大多数项目,艺术家会在拍卖向公众开放之前铸造一些作品。有些项目不会立即售罄,因此在拍卖开始几天后,您仍会收到铸造。我的分析集中在关键的拍卖时段,主要是前 30 分钟。为了摆脱上面的两个铸造案例,我删除了基于区块编号的异常值。
to_remove_indicies = []
for project in list(set(auctions["projectId"])):
auction_spec = auctions[auctions["projectId"]==project]
all_times = pd.Series(list(set(auction_spec.blocknumber)))
to_remove_blocktimes = all_times[(np.abs(stats.zscore(all_times)) > 2.5)]
if len(to_remove_blocktimes)==0:
break
to_remove_indicies.extend(auction_spec.index[auction_spec['blocknumber'].isin(to_remove_blocktimes)].tolist())
auctions.drop(index=to_remove_indicies, inplace=True)添加荷兰拍卖价格
对于数据集中除项目 118 之外的所有项目,均使用荷兰式拍卖价格格式。我使用dune查询获取薄荷价格数据,然后将其合并到数据集上。我不得不对有内存池操作但在拍卖期间没有确认的块使用向前和向后填充。
auction_prices = pd.read_csv(r'artblock_auctions_analytics/datasets/dune_auction_prices.csv', index_col=0)
auctions = pd.merge(auctions,auction_prices, how="left", left_on=["projectId","blocknumber"],right_on=["projectId","blocknumber"])
auctions.sort_values(by=["projectId","blocknumber"], ascending=True, inplace=True)
auctions["price_eth"].fillna(method="ffill", inplace=True)
auctions["price_eth"].fillna(method="bfill", inplace=True)每次拍卖的特征工程
如果您对技术部分不感兴趣,只需阅读粗体部分并跳过其余部分。
在数据科学中,特征是从更大的数据集计算出来的变量,用作某种模型或算法的输入。 所有特征都在 preprocess_auction 函数中计算,并且每次拍卖都会计算,而不是将所有拍卖组合成一个特征集。
第一组特性是交易状态的总数,是一个简单的 pivot_table 函数:
- number_submitted : 提交的交易总数
- cancel:以取消结束的交易计数
- failed:以失败结束的交易计数
- dropped:以丢弃结束的交易计数
- confirmed:以确认结束的交易计数
我之前提到过,由于各种问题,一些数据没有用于拍卖,这些交易从数据集中删除。
下一组特性包括它们的gas行为。这里的关键概念是捕捉他们的交易 gas 与每个区块的平均确认 gas 相差多远。然后,我们可以为整个拍卖的 gas 价格距离的平均值、中位数和标准差创建特征。有一堆转置和索引重置以按正确的顺序获取区块编号列,但重要的函数是 fill_pending_values_gas,它在捕获的操作之间向前填充 gas 价格。这意味着,如果我在区块编号 1000 处使用 0.05 ETH 的 gas 进行交易,而我的下一个操作是在区块编号 1005 之前我加速到 0.1 ETH 的 gas,那么此函数将用0.05ETH填充编号 1000-1005 之间的区块。
def fill_pending_values_gas(x):
first = x.first_valid_index()
last = x.last_valid_index()
x.loc[first:last] = x.loc[first:last].fillna(method="ffill")
return x第三组特性是计算拍卖中采取的行动的总数和频率。在这里,我们从每个块的总操作(加速)的支点开始,并进行一些特殊计算以获取每个事务的第一个待处理实例:
get_first_pending = df[df["status"]=="pending"] #first submitted
get_first_pending = get_first_pending.drop_duplicates(subset=["tx_hash","status"], keep="first")
auctions_time_data = pd.concat([get_first_pending,df[df["status"]=="speedup"]], axis=0)
time_action = auctions_time_data.pivot_table(index=["sender","tx_hash"], columns="blocknumber",values="status",aggfunc="count") \
.reindex(set(df["blocknumber"]), axis=1, fill_value=np.nan)从这里我们通过三个步骤到达 average_action_delay:
- 我们对每个区块采取动作action的数量(是的,有些人在同一个区块中多次加速交易)
- 我们在没有动作的情况下丢弃区块,然后计算剩余区块编号之间的差值。 我们为每个区块采取的每个额外动作添加一个 0。
- 对差异和给我们average_action_delay的添加的0取平均值,
def get_actions_diff(row):
row = row.dropna().reset_index()
actions_diff_nominal =list(row["blocknumber"].diff(1).fillna(0))
#take the blocks with muliple actions and subtract one, then sum up.
zeros_to_add = sum([ actions - 1 if actions > 1 else 0 for actions in row[row.columns[1]]])
actions_diff_nominal.extend(list(np.zeros(int(zeros_to_add))))
actions_diff = np.mean(actions_diff_nominal)
if (actions_diff==0) and (zeros_to_add==0):
return 2000 #meaning they never took another action
else:
return actions_difftotal_actions 简单得多,因为它只是整个枢轴的动作总和。
time_action["total_actions"] = time_action.iloc[:,:-1].sum(axis=1)最后一个依赖时间的特性是 block_entry,由于引入了荷兰式拍卖,这是一个重要的特性。本质上,这会跟踪自开始以来提交事务的区块。
get_first_pending["block_entry"] = get_first_pending["blocknumber"] - get_first_pending["blocknumber"].min()
entry_pivot = get_first_pending.pivot_table(index="sender",values="block_entry",aggfunc="min")price_eth 也被添加为一个特性,它与 block_entry 点相关联。
最后一组特性基于 Dune 查询,特别是自第一次交易以来的天数、交易中使用的总 gas 以及交易总数。为了以正确的格式获取地址数组,我在读入 SQL 数据后使用了以下代码行:
all_users = list(set(auctions["sender"].apply(lambda x: x.replace('0x','\\x'))))
all_users_string = "('" + "'),('".join(all_users) + "')"对此的Dune查询相当简单。我将地址字符串粘贴到 VALUES 下,并制作了一些 CTE 以获得我想要的功能。在最后的 SELECT 中,我也尝试添加每个地址的 ens。您可以在此处找到查询:https://dune.xyz/queries/96523
最后,我们只是合并了每个钱包的活跃天数、使用的总gas 和交易总数的数据。
auctions_all_df = pd.merge(auctions_all_df,wh,on="sender",how="left")
auctions_all_df.set_index(["sender","ens"],inplace=True)完成所有这些后,我们终于准备好运行一些有趣的无监督学习算法,并尝试验证我们对用户群的假设。
聚类和可视化用户组
在我开始这个项目之前,我预计会看到以下用户组从数据中弹出:
- 设置然后忘掉:这里应该有两个群体,那些设置了非常高的 gas 和平均/低 gas 的交易,然后在拍卖的剩余时间里不要碰它。
- 加速:这里也应该有两个群体,一类是经常加速并直接更新交易作为gas价格的因素,一类是经常加速交易但gas价格基本上没有变化的人。
我对验证这些群体非常感兴趣,看看每个群体有多大,看看是否有用户在多次拍卖过程中在群体之间移动。最简单的方法是使用无监督机器学习,根据所有特征的可变性来识别用户组群。从本质上讲,这就像查看一个州的收入分配,然后将其分成不同收入集中度、地理坐标和年龄的子分配。请注意,这不是分箱,其中分布被分成相等的范围 - 它是根据整个范围内的观察密度计算的。我们将采用的方法称为“无监督”,因为我们的数据集没有任何现有标签,而不是像回归分析这样的方法,其中预测的值可以被验证为正确或错误。
我决定使用的算法称为 k-means,其中 k 代表您希望识别的集群数量。 每个集群都有一个“质心”,就像一个圆的中心。 有多种方法可以确定最佳集群的数量,我使用的两种方法是肘点和轮廓分数。 这两种提问方式都很奇葩,
“每个额外的集群是否有助于增加集群的密度(计算为集群中点与质心的平均距离)并保持集群之间的足够分离(两个集群之间没有重叠)?”
我发现 3 个集群在大多数惯性改进方面是最佳的,同时保持高轮廓分数(大约 0.55)。
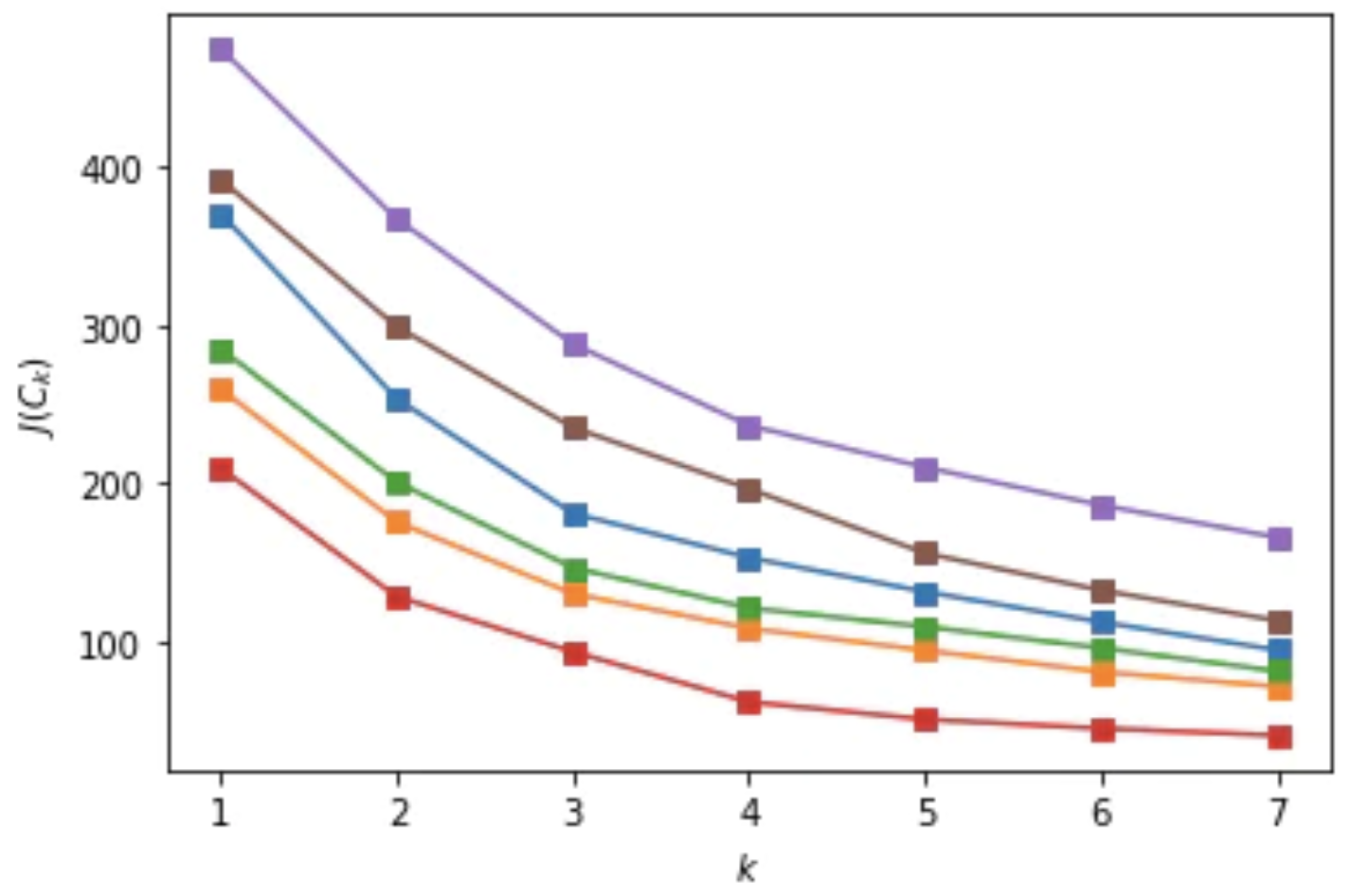
本次分析使用了 6 次拍卖
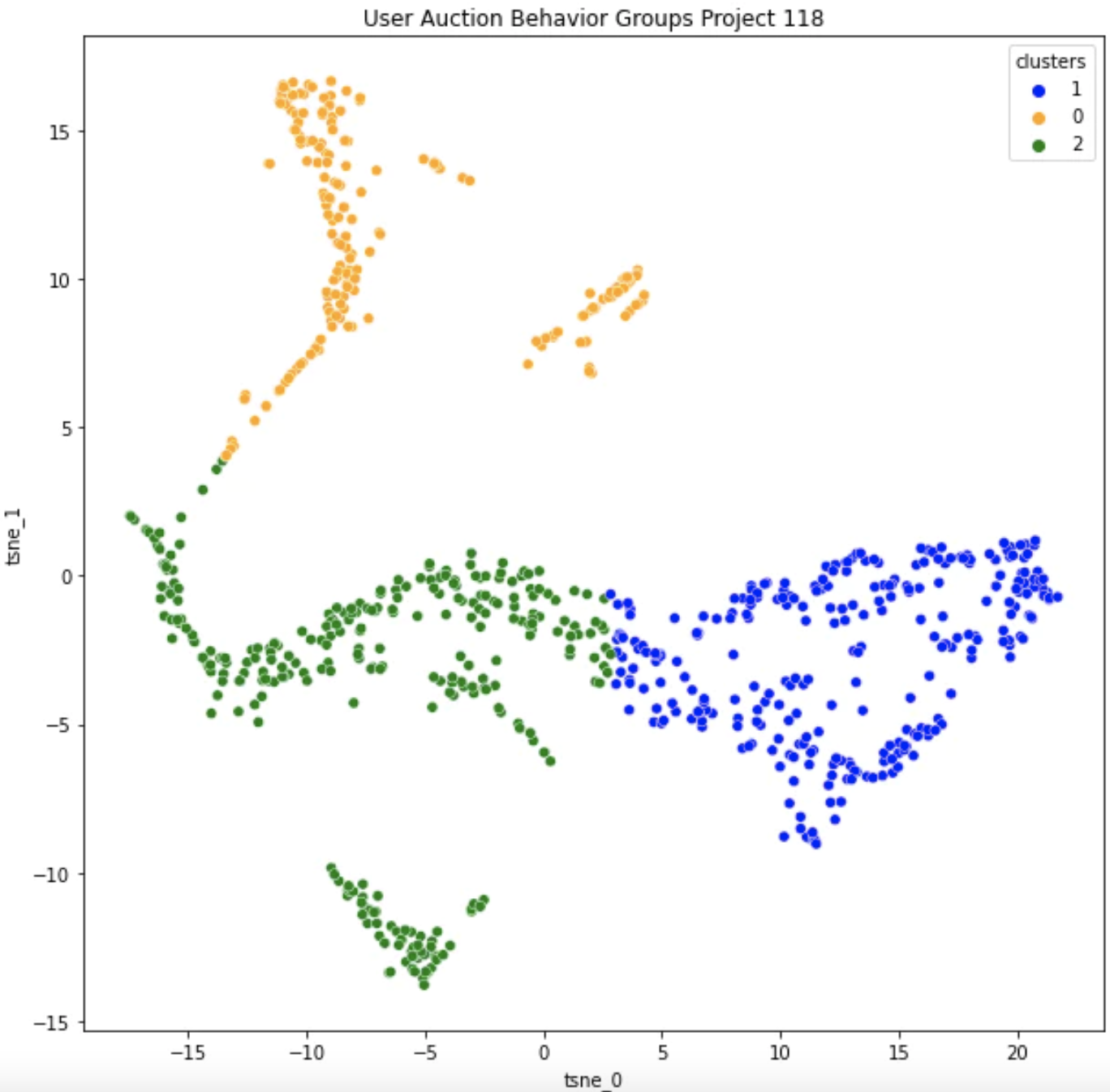
选择集群后,我们希望能够可视化并验证它们的存在。 这里有超过 15 个变量,因此我们需要减少维数以绘制它。 减少维数通常依赖于 PCA 或 t-SNE 算法,在我们的例子中我使用了 t-SNE。 不要太担心理解这部分,这些算法本质上捕获所有特征的方差,为我们提供 X 和 Y 分量,使点彼此的传播最大化。
让我们从8 月 4 日看看项目 118,LeWitt Generator Generator:
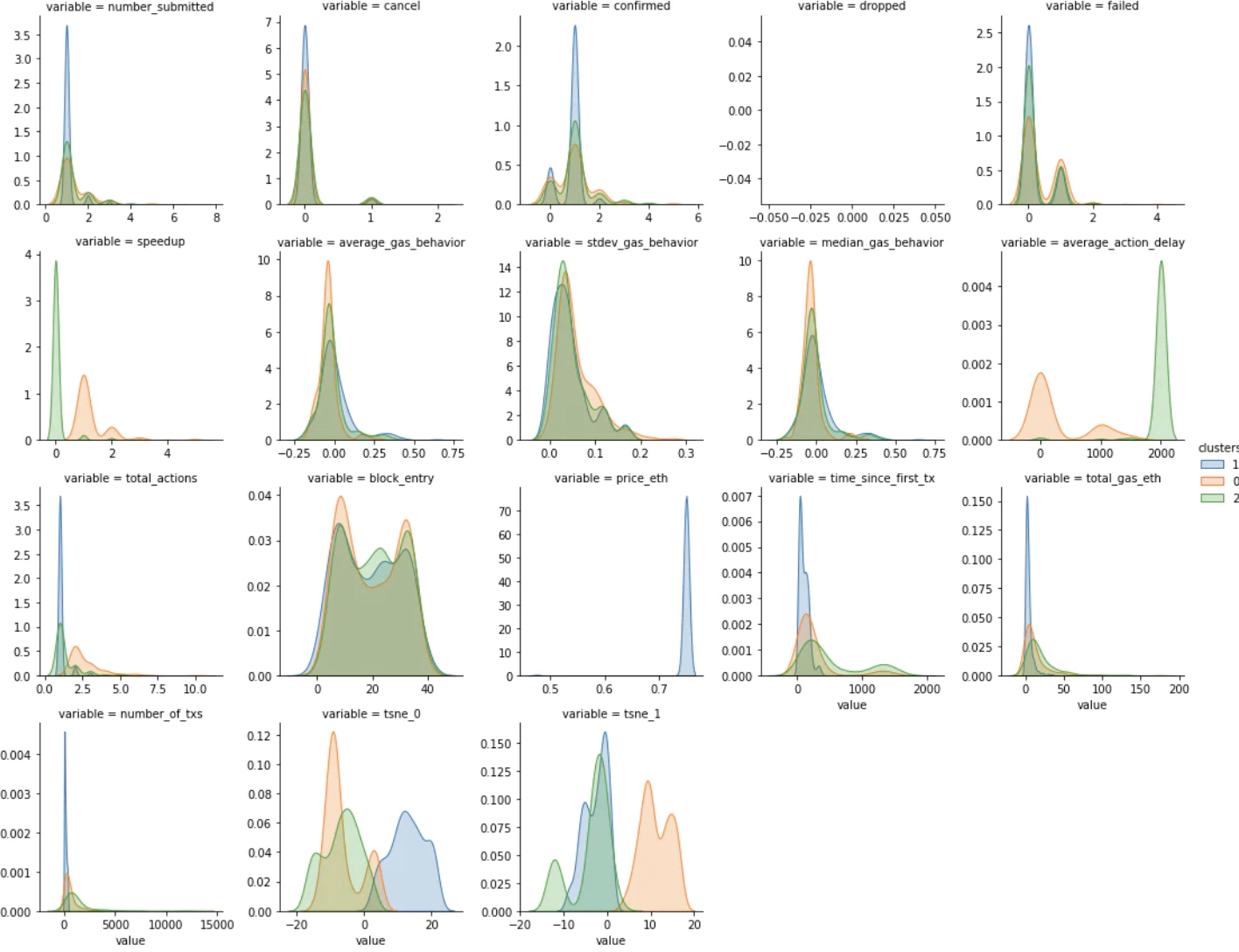
这些是使用 KDE 计算的按集群划分的每个变量的子分布。 颜色与上述集群中的颜色相匹配。
在查看了每个变量的子分布和一些数据示例后,我能够对集群进行分类。 Orange 集群是速度最快的组,同时平均提交的 gas 交易也略低。 Blue 和 Green 集群彼此表现出相似的行为,但 Blue 中的地址通常比 Green 集群中的地址具有更少的历史记录。
纵观全局,原来的“提速”和“高低设置”产生两组的假设似乎是错误的。相反,我们有一个“加速”群体(橙色)和一个“一劳永逸”群体(蓝色和绿色在行为上相同)。我认为“设置并忘掉”群体中的新钱包(蓝色)与旧钱包(绿色)可能在实际用户中有很多重叠,用户只是创建了新钱包来竞标更多的铸币。基于他们的不耐烦和低于平均水平的gas价格,“加速”群体在我看来要么经验不足,要么比其他用户更贪婪。在整个拍卖过程中,这群人似乎也相当焦虑。令我惊讶的是,加速群体占投标者总数的比例较小,因为我曾预计该群体占投标者的 60-70%,而不是 30%。
现在,这个用户行为研究真正有趣的地方在于将项目 118(0.75 ETH 的设定价格)与项目 140(荷兰拍卖,价格从 1.559 降到 0.159 ETH)。
这是 8 月 21 日开始的项目 140 Good Vibrations的集群聚集:
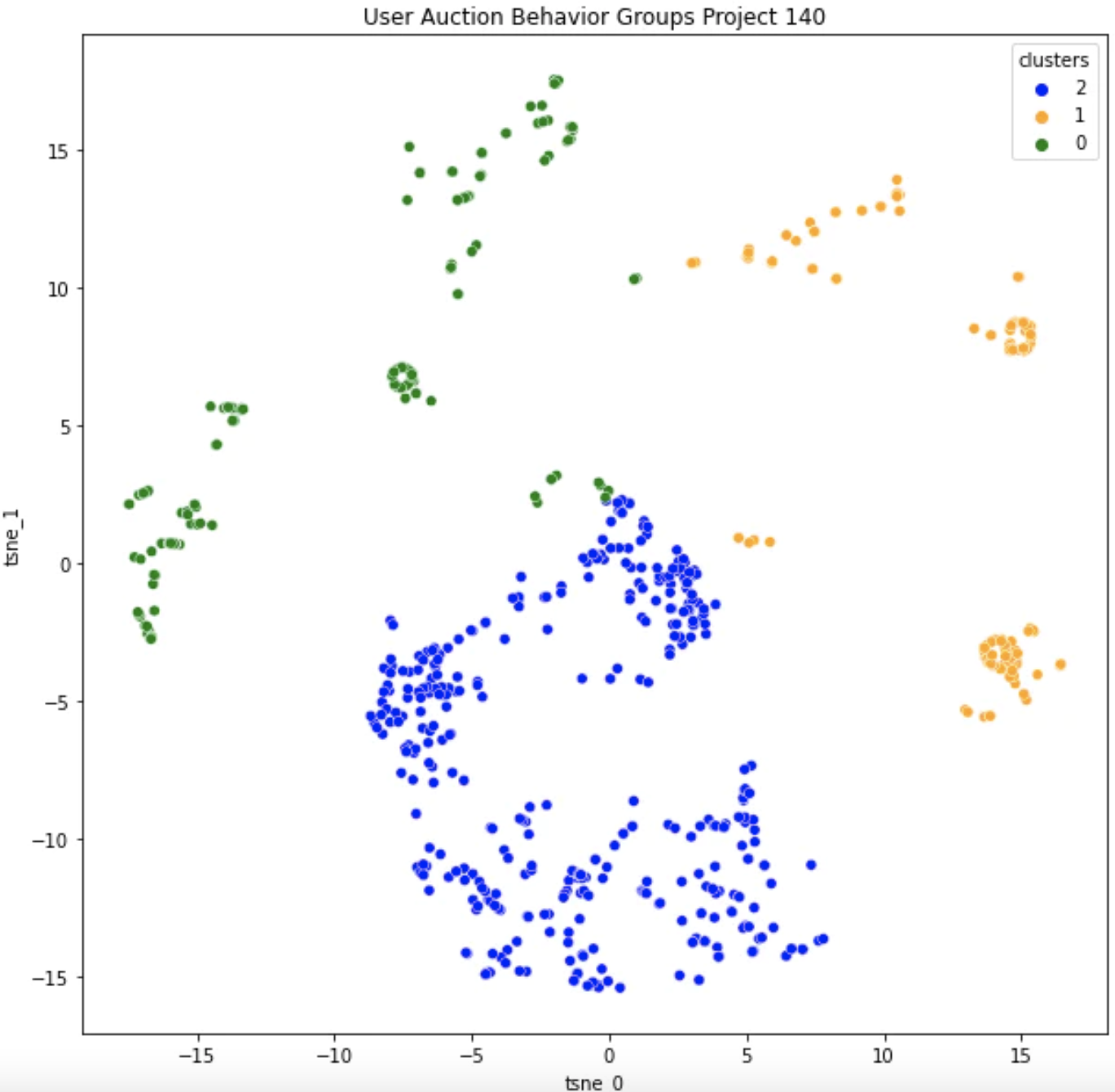
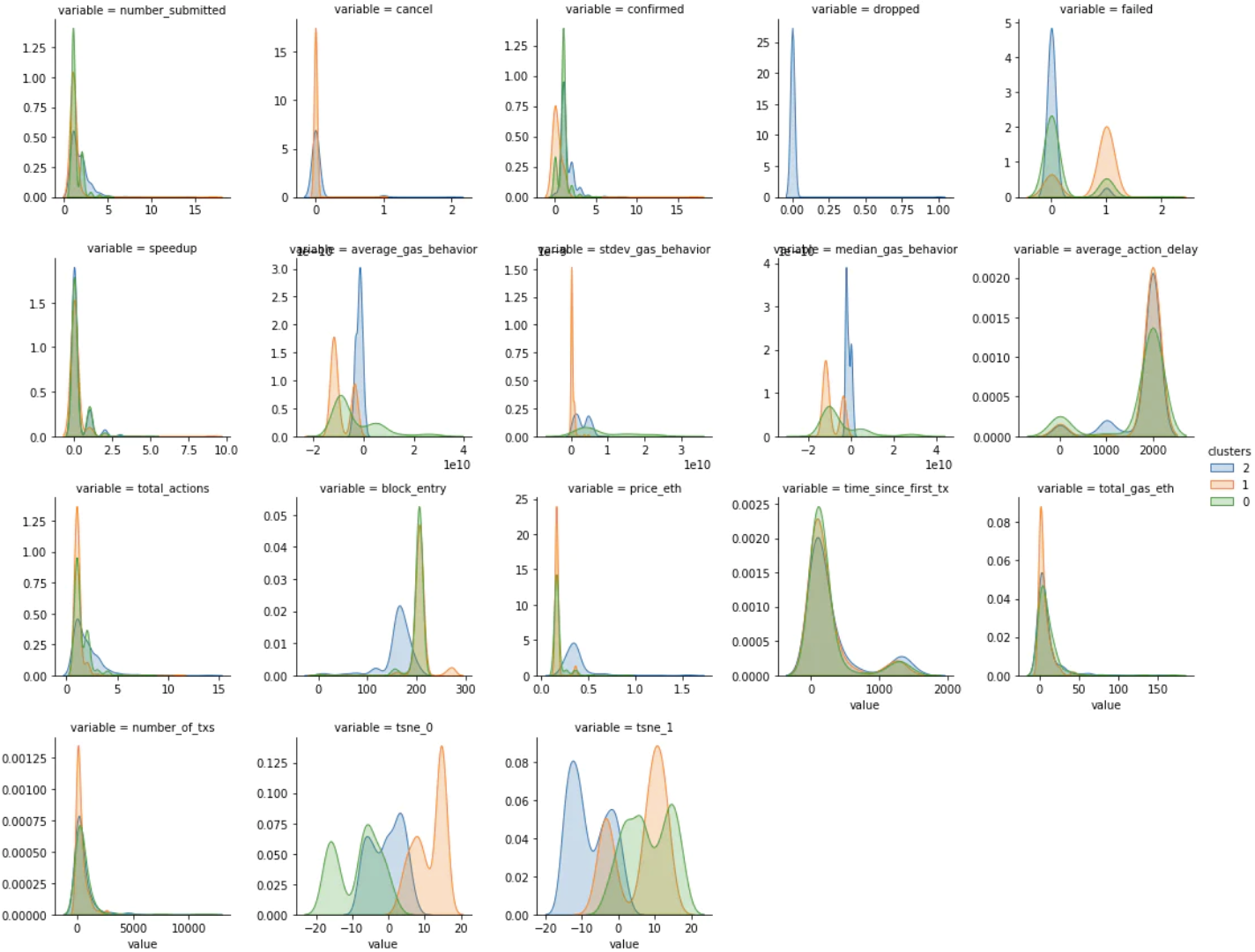
我们可以看到,现在大部分聚类变异性来自 block_entry、price_eth 和所有 gas_behavior 特征。这与项目 118 的主要变量大相径庭。在 118 中,设定价格意味着人们以相当均匀的分布(剩余数量似乎无关紧要)进入拍卖,而“加速”群体使行动相当无休止 - 可能非常焦虑。
在项目 140 中,我们在 average_action_delay 或 total_actions 中没有看到相同的动作差异,相反,我们可能看到相同的“加速”群体在非常晚的阶段进入并设置远低于平均水平的gas价格,如平均gas行为。绿色集群可能代表比橙色集群有更多经验的用户,但他们的行为仍在橙色和蓝色之间转换。如果我尝试将其映射到 118 中的集群,我相信“加速”群体现在已成为进入较晚并发出低gas量的“贪婪”群体(橙色)。 “设置并忘记”群体很好地映射到“早抢”群体(绿色和蓝色),因为他们都表现出很好的耐心和足够的gas投标安全性净值。
我称橙色群体为“贪婪”,不仅因为他们的行为,还因为他们的交易失败率。
对于项目 118,“加速”群体与“设置并忘掉”群体的失败率在 10-15% 之间。

percent_lost takes (cancel + dropped + failed) / number_submitted
对于项目 140,“贪婪”集群的失败率约为 69%,而“早期抢夺”群体的失败率约为 5-15%。

总的来说,我对此的理解是,该团体的坏习惯和情绪被放大了——我觉得我们在焦虑→贪婪之间做出了权衡。 这可能使拍卖的压力较小,但最终导致更多用户感到不安(由于失败的铸币)。
我确信可以进行更细粒度的分析,以根据工厂/策划/游乐场或艺术家本人对拍卖进行进一步细分。 随着社区的不断发展,这只会变得更加有趣和复杂,并且情绪在单次拍卖和未来拍卖中是否回归都会发挥更大的作用。
这项对多次拍卖的研究帮助我们验证了我们的假设,了解用户组的比例,并了解用户的好坏行为如何随时间(和其他参数)变化。 现在我们需要将其插入到产品周期流程的其余部分中。
我们从哪里开始:
我为此只选择 Artblocks 拍卖而不是混合平台的原因是因为我想寻找一个可以控制界面和项目类型可变性的地方。 这应该为我们提供了相当一致的用户和行为类型。
这只是 UX 研究周期的开始,因此理想情况下,我们可以继续以下步骤:
- 使用无监督机器学习算法来识别用户群体(集群)并查看有多少人在进入拍卖时犯了“错误”。这是我们今天介绍的步骤?。
- 创建一个新的用户界面,例如出价屏幕上的直方图视图,或显示大多数人通常何时进入/拥挤拍卖以及以什么价格参加的历史数据。任何可以为用户提供当前和历史背景的东西,尤其是来自速度集群的那些。
- 在每次拍卖中,通过创建的算法运行内存池/钱包数据,以查看用户群体是否发生了变化,以及特定用户是否“学会”以不同方式参与拍卖(即他们是否在用户群体之间移动)。我认为如果做得好,可以在这一步中找到最大的价值。使用 ENS 或其他标识符来帮助补充这个分组也会成倍地有用。
- 根据结果??,继续迭代用户界面和设计。您还可以运行更明智的 A/B 测试,因为您甚至可以通过基于用户的最后一个集群(或对新用户使用标签传播)进行有根据的猜测来确定要显示的屏幕。
荷兰式拍卖风格的变化也是第 2 步的一个例子,我们能够看到用户行为的明显转变。虽然通常这种 A/B 测试侧重于提高参与度或转化率,但我们在这里优化的是用户的学习和改进能力。如果在多平台背景中进行迭代,这可能会变得更加健壮,以便我们可以研究某人如何在生态系统级别进行学习(甚至可以补充 Rabbithole 数据和用户配置文件)。由于我的 Artblocks 用户研究全部基于公开来源的数据,因此可以被任何其他拍卖/销售平台复制和补充。加密可能是第一个拥有同步且透明的用户组和用户体验研究的行业,可应用于产品和学术界。 Nansen 钱包标签已经朝着这个方向迈出了一步,但是当来自不同产品的团队从不同的方面和方法构建它时,情况就不一样了。
我最终的设想是使用数据来构建以下用户角色(其中包含子组/级别):
- 我想购买一个 Fidenza,所以我可以通过私人销售购买一个,自己也可以在拍卖会上出价,在 prtyDAO 出价拍卖中出价,或者通过fractional.art 购买一小部分。
- 我一般喜欢 Fidenzas,所以我只会购买 NFTX Fidenza 指数代币或 fractional.art上的Artblocks NFT 篮子。
- 我已经是一个收藏家,所以我想使用我已经持有的一组精选的 NFT 和 ERC20(使用 genie-xyz 交换)交换或竞标 Fidenza。
- 我喜欢通过初始铸造与二级市场进行收购的热潮,并大量参与 Artblocks在线铸造之类的拍卖。
我希望你觉得这个项目有趣和/或有帮助,我玩得很开心。感谢 Blocknative 的人们为我提供帮助,感谢 Artblocks 的社区回答我的许多拍卖问题。与往常一样,如有任何问题或想法,请随时与我们联系!
您可以在此处找到包含所有数据和脚本的 GitHub 存储库。该脚本可能有点难以阅读,因为我仍在重构和清理它。当我分析 8 月最后几次拍卖的新模式时,这里的脚本和一些分析可能会更新。


