人工智能之随机森林(RF)
AI优化生活通过上一篇文章《人工智能之决策树》,我们清楚地知道决策树(DT)是一类常见的机器学习方法。决策树(DT)在人工智能中所处的位置:人工智能-->机器学习-->监督学习-->决策树。决策树主要用来解决分类和回归问题,但是决策树(DT)会产生过拟合现象,导致泛化能力变弱。过拟合是建立决策树模型时面临的重要挑战之一。鉴于决策树容易过拟合的缺点,由美国贝尔实验室大牛们提出了采用随机森林(RF)投票机制来改善决策树。随机森林(RF)则是针对决策树(DT)的过拟合问题而提出的一种改进方法,而且随机森林(RF)是一个最近比较火的算法。因此有必要对随机森林(RF)作进一步探讨。^_^

随机森林(RF)在人工智能中所处的位置:人工智能-->机器学习-->监督学习-->决策树-->随机森林。
随机森林(RF)指的是利用多棵树对样本进行训练并预测的一种分类器。该分类器最早由Leo Breiman和Adele Cutler提出,并被注册成了商标。

那么什么是随机森林?
随机森林(RandomForests)是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。Leo Breiman和Adele Cutler发展并推论出随机森林的算法。随机森林(RF)这个术语是1995年由贝尔实验室的Tin Kam Ho所提出的随机决策森林(random decision forests)而来的。这个方法则是结合 Breimans 的 "Bootstrap aggregating" 想法和 Ho 的"random subspace method"以建造决策树的集合。
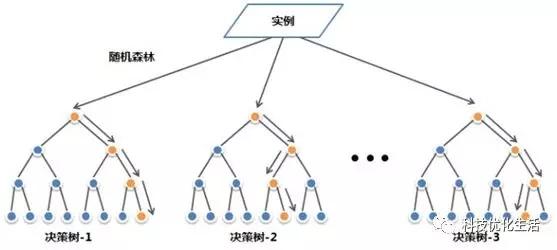
通过定义我们知道,随机森林(RF)要建立了多个决策树(DT),并将它们合并在一起以获得更准确和稳定的预测。随机森林的一大优势在于它既可用于分类,也可用于回归问题,这两类问题恰好构成了当前的大多数机器学习系统所需要面对的。
随机森林是集成学习的一个子类,它依靠于决策树的投票选择来决定最后的分类结果。集成学习通过建立几个模型组合的来解决单一预测问题。集成学习的简单原理是生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成单预测,因此优于任何一个单分类的做出预测。
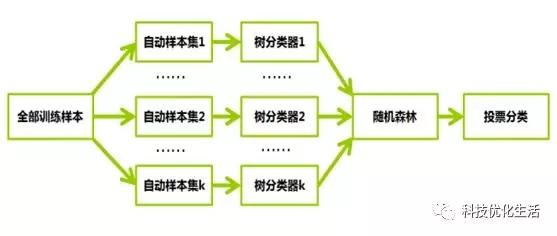
随机森林的构建过程:
假设N表示训练用例(样本)个数,M表示特征数目,随机森林的构建过程如下:
1) 输入特征数目m,用于确定决策树上一个节点的决策结果;其中m应远小于M。
2) 从N个训练用例(样本)中以有放回抽样的方式,取样N次,形成一个训练集,并用未抽到的用例(样本)作预测,评估其误差。
3) 对于每一个节点,随机选择m个特征,决策树上每个节点的决定都是基于这些特征确定的。根据m个特征,计算其最佳的分裂方式。
4) 每棵树都会完整成长而不会剪枝,这有可能在建完一棵正常树状分类器后会被采用。
5) 重复上述步骤,构建另外一棵棵决策树,直到达到预定数目的一群决策树为止,即构建好了随机森林。

其中,预选变量个数(m)和随机森林中树的个数是重要参数,对系统的调优非常关键。这些参数在调节随机森林模型的准确性方面也起着至关重要的作用。科学地使用这些指标,将能显著的提高随机森林模型工作效率。
1 2 下一页>
