人工智能之K-Means算法
AI优化生活前言:人工智能机器学习有关算法内容,人工智能之机器学习主要有三大类:1)分类;2)回归;3)聚类。今天我们重点探讨一下K-Means算法。
K-Means是十大经典数据挖掘算法之一。K-Means和KNN(K邻近)看上去都是K打头,但却是不同种类的算法。kNN是监督学习中的分类算法,而K-Means则是非监督学习中的聚类算法;二者相同之处是均利用近邻信息来标注类别。
提到“聚类”一词,使人不禁想到:“物以类聚,人以群分”。聚类是数据挖掘中一种非常重要的学习流派,指将未标注的样本数据中相似的分为同一类。

K-means算法是很典型的基于距离的聚类算法。于1982年由Lloyod提出。它是简单而又有效的统计聚类算法。一般采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标。
K-Means概念:
K-means算法是硬聚类算法,是典型的基于原型的目标函数聚类方法的代表,它是数据点到原型的某种距离作为优化的目标函数,利用函数求极值的方法得到迭代运算的调整规则。K-means算法以欧式距离作为相似度测度,它是求对应某一初始聚类中心向量V最优分类,使得评价指标J最小。算法采用误差平方和准则函数作为聚类准则函数。

K-Means核心思想:
由用户指定k个初始质心(initial centroids),作为聚类的类别(cluster),重复迭代直至算法收敛。即以空间中k个点为中心进行聚类,对最靠近他们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。
k个初始类聚类中心点的选取对聚类结果具有较大的。

K-Means算法描述:
假设要把样本集分为c个类别,算法描述如下:
1)适当选择c个类的初始中心;
2)在第k次迭代中,对任意一个样本,求其到c个中心的距离,将该样本归到距离最短的中心所在的类;
3)利用均值等方法更新该类的中心值;
4)对于所有的c个聚类中心,如果利用2)和3)的迭代法更新后,值保持不变,则迭代结束,否则继续迭代。
具体如下:
输入:k, data[n];
1)选择k个初始中心点,例如c[0]=data[0],…c[k-1]=data[k-1];
2)对于data[0]….data[n],分别与c[0]…c[k-1]比较,假定与c[i]差值最少,就标记为i;
3)对于所有标记为i点,重新计算c[i]={ 所有标记为i的data[j]之和}/标记为i的个数;
4)重复2)和3),直到所有c[i]值的变化小于给定阈值。
该算法的最大优势在于简洁和快速。算法的关键在于初始中心的选择和距离公式。
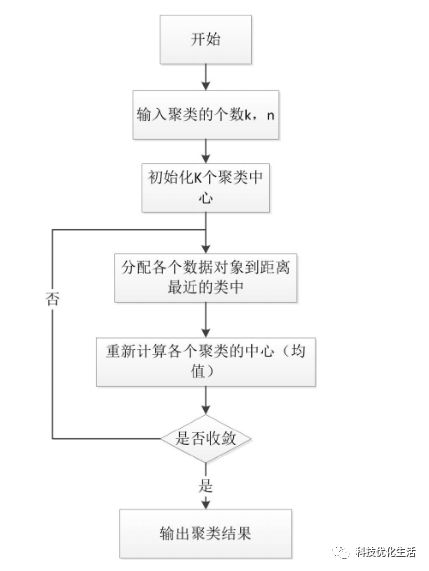
K-Means工作流程:
1)从 n个数据对象任意选择k个对象作为初始聚类中心;
2)根据每个聚类对象的均值(中心对象),计算每个对象与这些中心对象的距离;并根据最小距离重新对相应对象进行划分;
3)重新计算每个(有变化)聚类的均值(中心对象);
4)循环2)到3)直到每个聚类不再发生变化为止,即标准测度函数收敛为止。
注:一般采用均方差作为标准测度函数。
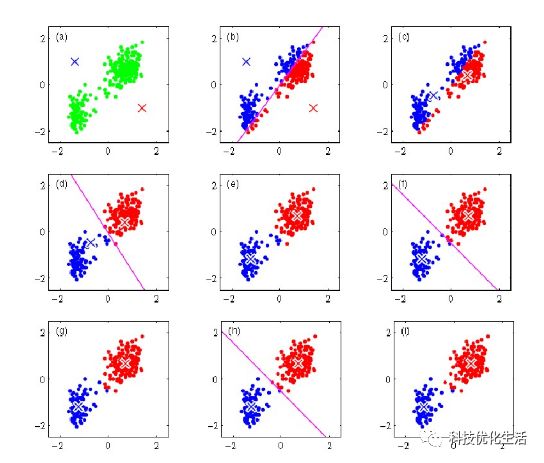
K-Means算法接受输入量k;然后将n个数据对象划分为k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。即,各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开。
聚类相似度是利用各聚类中对象的均值所获得一个“中心对象”(引力中心)来进行计算的。
1 2 下一页>
