自动驾驶深度学习计算框架有了新选择,华为发布全场景AI计算框架MindSpore
智车科技IV
自动驾驶汽车依靠AI算法来完成感知识别、决策、规划等动作,在算法搭建前往往要选择合适的计算框架。
过去,工程师们往往会在“适合入门又编码繁琐”的TensorFlow、“强调极简主义”的Keras、“传统老牌但缺乏灵活性”的Caffe、“低门槛”的PaddlePaddle 等框架中做选择,而在今天,华为发布了全场景AI计算框架 MindSpore,直接对标业界主流框架谷歌的Tensor Flow。

在2018华为全联接大会上,华为提出,AI框架应该是开发态友好(例如显著减少训练时间和成本)和运行态高效(例如最少资源和最高能效比),更重要的是,要能适应每个场景包括端、边缘和云。
经过近一年的努力,全场景AI计算框架MindSpore在这三个方面都取得了显著进展。
全场景支持,是在隐私保护日渐重要的背景下,实现AI无所不在越来越基础的需求,也是MindSpore的重要特色。
针对不同的运行环境,MindSpore框架架构上支持可大可小,适应全场景独立部署。MindSpore框架通过协同经过处理后的、不带有隐私信息的梯度、模型信息,而不是数据本身,以此实现在保证用户隐私数据保护的前提下跨场景协同。除了隐私保护,MindSpore还将模型保护Built-in到AI框架中,实现模型的安全可信。
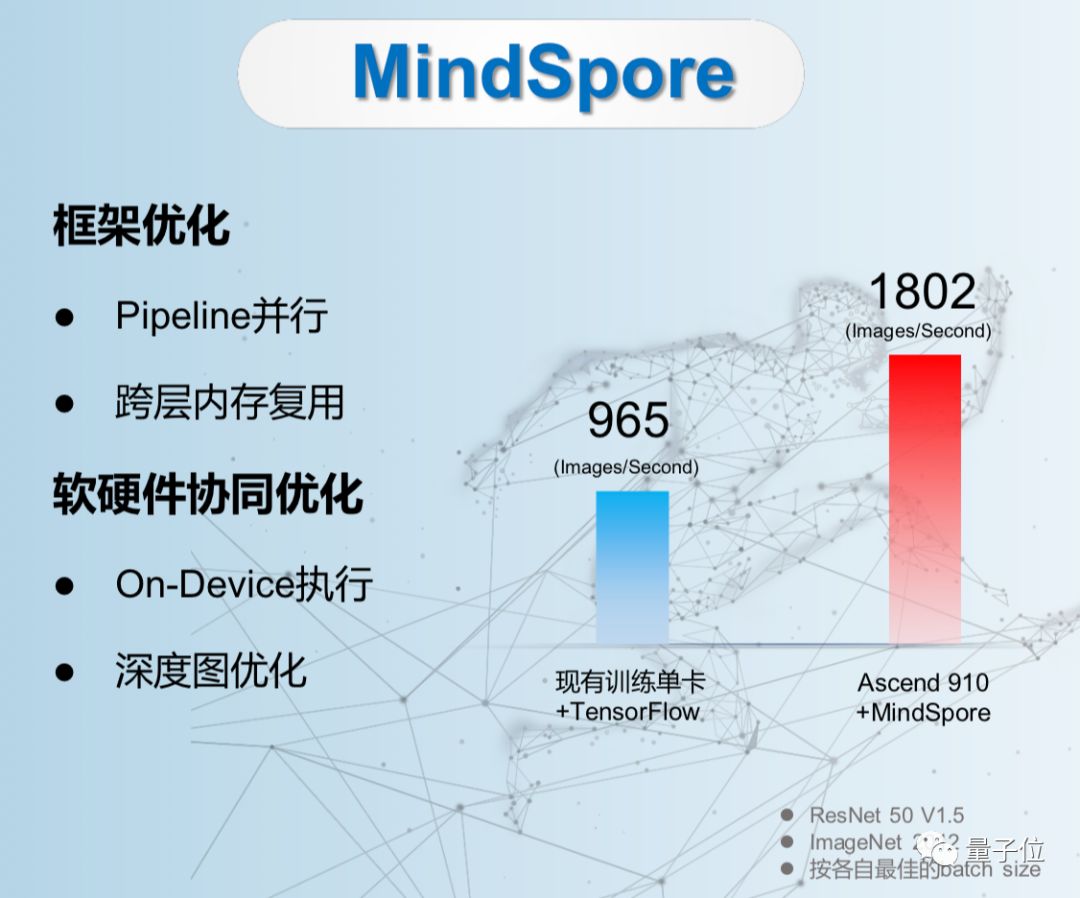
在原生适应每个场景包括端、边缘和云,并能够按需协同的基础上,通过实现AI算法即代码,使开发态变得更加友好,显著减少模型开发时间。以一个NLP(自然语言处理)典型网络为例,相比其他框架,用MindSpore可降低核心代码量20%,开发门槛大大降低,效率整体提升50%以上。
通过MindSpore框架自身的技术创新及其与昇腾处理器协同优化,有效克服AI计算的复杂性和算力的多样性挑战,实现了运行态的高效,大大提高了计算性能。除了昇腾处理器,MindSpore同时也支持GPU、CPU等其它处理器。
值得一提的是,华为已经用基于Ascend 310芯片的MindSpore DDK做一些车辆识别的项目。
华为轮值董事长徐直军认为“大家目前最缺少的还是算力,谁的算力强,谁发论文就快。论文增长最快的是谷歌,因为它有最强的算力。AI本来就是一个暴力计算,没有暴力,哪来成果?华为云面向全球,启动暴力。”
昇腾910,号称算力最强AI处理器

今天的发布会上,华为正式发布算力最强的AI处理器Ascend 910(昇腾910)。
经过一年多的测试,在算力方面,昇腾910完全达到了设计规格,即:半精度(FP16)算力达到256 Tera-FLOPS,整数精度(INT8)算力达到512 Tera-OPS;重要的是,达到规格算力所需功耗仅310W,明显低于设计规格的350W。
徐直军表示:昇腾910总体技术表现超出预期,作为算力最强AI处理器,当之无愧。当昇腾910用于实际AI训练任务,比如,在典型的ResNet50网络的训练中,昇腾910与MindSpore配合,与现有主流训练单卡配合TensorFlow相比,显示出接近2倍的性能提升。
面向未来,针对不同的场景,包括边缘计算、自动驾驶车载计算、训练等场景,华为将持续投资,推出更多的AI处理器,面向全场景持续提供更充裕、更经济、更适配的AI算力。
全栈全场景AI解决方案,让AI无处不在
徐直军在发布以上两款产品之前,首先重申了华为公司的AI战略:
投资AI基础研究:在计算视觉、自然语言处理、决策推理等领域构筑数据高效(更少的数据需求) 、能耗高效(更低的算力和能耗),安全可信、自动自治的机器学习基础能力;
打造全栈全场景解决方案:提供充裕的、经济的算力资源,简单易用、高效率、全流程的AI平台;
投资开放生态和人才培养:面向全球,持续与学术界、产业界和行业伙伴广泛合作;
把AI思维和技术引入现有产品和服务,实现更大价值、更强竞争力;
应用AI优化内部管理,对准海量作业场景,大幅度提升内部运营效率和质量。
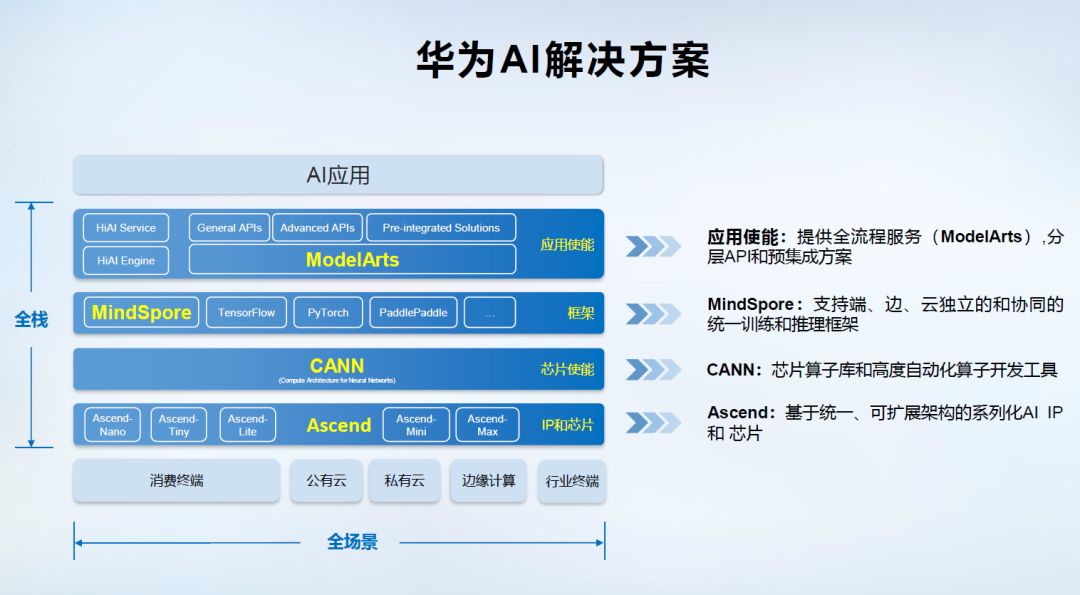
华为AI解决方案(Portfolio)的全场景,是指包括公有云、私有云、各种边缘计算、物联网行业终端以及消费类终端等部署环境;而全栈是技术功能视角,是指包括Ascend昇腾系列IP和芯片、芯片使能CANN、训练和推理框架MindSpore和应用使能ModelArts在内的全堆栈方案。
华为认为AI的应用总体还处于发展初期,AI技术和能力相比于长远期望还有很大差距。减小甚至消除这些差距,加速AI的应用。具体包括致力于促成以下10个方面的改变:

通过全栈全场景技术手段,结合投资开放的生态和人才培养,让AI人才不再短缺。
