GPT-1
- GPT-1
主要解决的问题:怎么在无标号数据上面预训练大模型?
GPT使用语言模型来进行预训练,并使用了n-gram方法对当前单词进行预测。通俗的说,也就是根据前k个单词来预测下一个单词谁什么,大量高质量文本语料就意味着自动获得了海量的标注数据。最关键的是如何优化目标函数,因为不同的任务目标函数设定是不一样的。GPT使用对数最大似然函数来计算loss,使用transformer的解码器(因为有掩码不能看到完整的句子信息),并且其中使用了position embedding引入了位置信息。
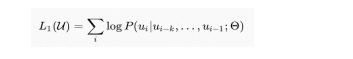
怎么做模型微调?
微调时使用的是带有标号的数据集,每次输入长度为m的一条序列x,这条序列有一个标号y。模型根据输入的序列x预测其标号y(标准分类任务)。要考虑的是如何将nlp下游的子任务表示成我们想要的形式,即一些序列和其相应的标号。
怎么根据任务的不同改变下游输入?
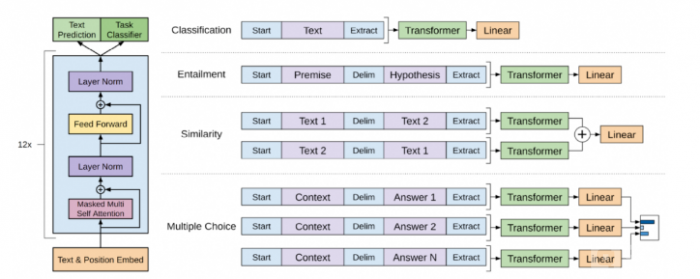
如下图所示,其中start(起始)、delim(分割)和 extract(终止)是特殊字符,文本中不会出现的字符。
- 分类任务(classification):输出是分类类别。
- 蕴含任务(entailment):输出是是与否,是否蕴含这个关系。
- 相似性任务:相似是一个对称关系,但是语言模型是有顺序的,所以做了两种拼接,最后输出是二分类,相似或不相似。
- 多选题:问一个问题给出几个答案选出认为正确的问题,输出的是每个答案对于这个问题是正确答案的置信度。