大模型
大模型
2.1 不是模型参数大就叫大模型
关于大模型,有学者称之为“大规模预训练模型”(large pretrained language model),也有学者进一步提出”基础模型”(Foundation Models)的概念
2021年8月,李飞飞、Percy Liang等百来位学者联名发布了文章:On the Opportunities and Risks of Foundation Models[1],提出“基础模型”(Foundation Models)的概念:基于自监督学习的模型在学习过程中会体现出来各个不同方面的能力,这些能力为下游的应用提供了动力和理论基础,称这些大模型为“基础模型”。
“小模型”:针对特定应用场景需求进行训练,能完成特定任务,但是换到另外一个应用场景中可能并不适用,需要重新训练(我们现在用的大多数模型都是这样)。这些模型训练基本是“手工作坊式”,并且模型训练需要大规模的标注数据,如果某些应用场景的数据量少,训练出的模型精度就会不理想。
“大模型”:在大规模无标注数据上进行训练,学习出一种特征和规则。基于大模型进行应用开发时,将大模型进行微调(在下游小规模有标注数据进行二次训练)或者不进行微调,就可以完成多个应用场景的任务,实现通用的智能能力。
2.2 大模型赛道早已开始
多语言预训练大模型
- Facebook已发布了一个百种语言互译的模型M2M-100,该模型不依赖英文作为中介语言,可实现一百种语言之间的直接翻译,在机器翻译领域实现新突破。
- 谷歌宣布开源了多语言模型MT5,基于101种语言进行训练,采用750GB文本,最大含有130亿个参数, 目前已在大多数多语言自然语言处理任务基准测试中达到最优水平,包括机器翻译、阅读理解等。
多模态预训练大模型
OpenAI已研发DALL·E、CLIP等多模态模型,参数达120亿,在图像生成等任务上取得优秀表现。
多任务预训练大模型
谷歌在2022年的IO大会上公开了MUM(多任务统一模型 : Multitask Unified Model)的发展情况。据谷歌透露,MUM模型基于大量的网页数据进行预 训练,擅长理解和解答复杂的决策问题,能够理解75种语言,从跨语言多模态网页数据中寻找信息。
视觉预训练大模型
具备视觉通用能力的大模型,如ViTransformer等。视觉任务在日常生活和产业发展中占据很大的比重,视觉大模型有可能在自动驾驶等依赖视觉处理的领域加速应用。
2.3 深度学习范式即将改变
AI的研发和应用范式可能会发生极大的变化,各位大佬或许也是因为看到了深度学习2.0时代的到来,纷纷投身大模型赛道。
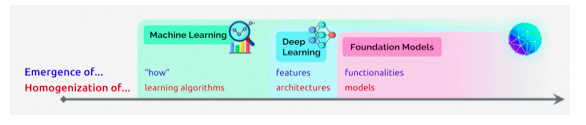
上图源自李飞飞、Percy Liang等百来位学者联名发布的文章[1]
machine learning homogenizes learning algorithms (e.g., logistic regression), deep learning homogenizes model architectures (e.g., Convolutional Neural Networks), and foundation models homogenizes the model itself (e.g., GPT-3)
如文中所说,机器学习同质化学习算法(例如逻辑回归)、深度学习同质化模型结构(例如CNN),基础模型则同质化模型本身(例如GPT-3)。

人工智能的发展已经从“大炼模型”逐步迈向了“炼大模型”的阶段。ChatGPT只是一个起点,其背后的Foundation Module的长期价值更值得被期待。


