深度学习下的AI落地 计算机视觉是否一条好赛道
张康康计算机视觉是目前AI在中国落地最顺利的技术。从目前的落地进展来看,移动互联网、安防、零售、物流、医疗、文娱、无人驾驶的商业化有待成熟。以旷视科技Face++、商汤科技、极链科技Video++为代表的AI头部企业战略出现向平台企业或软硬一体化企业发展的分化趋势及零售等新领域快速崛起。
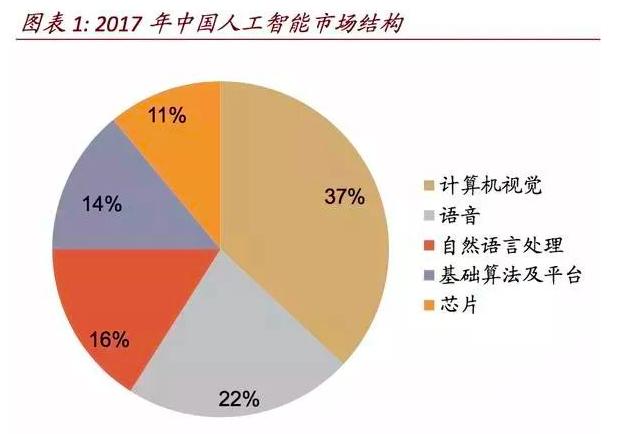
计算机视觉在中国AI市场组成部分占比巨大。根据中国信通院2018年2月发布的报告数据,2017年,中国人工智能市场中计算机视觉占比37%,以80亿元的行业收入排名第一。2018年信通院11月发布的《2018人工智能发展白皮书——技术篇》中以深度学习算法驱动的人工智能技术为主,数据显示,在全球人工智能产业蓬勃发展的今天,人工智能技术以机器学习,特别是深度学习为核心,在视觉、语音、自然语言等应用领域迅速发展,已经开始渗入到各个行业。BBC预测,2020年全球人工智能市场规模约183亿美元,年均增长20%。在人工智能产业应用上,从融资规模和市场结构来看,中国AI企业更集中于视觉和语音方向。
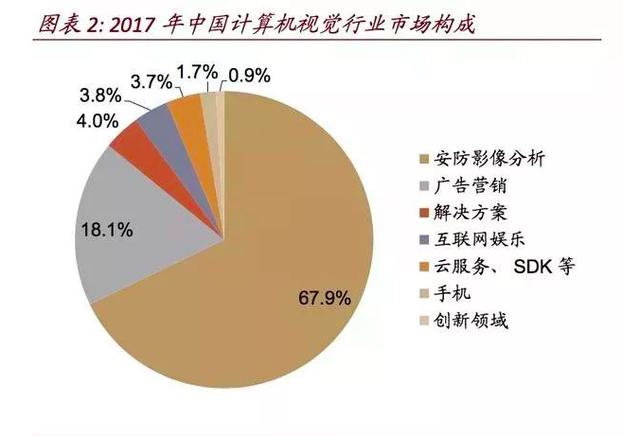
目前,深度学习几乎成了计算机视觉领域的标配,也是当下人工智能领域最热门的研究方向。计算机视觉的应用场景和深度学习背后的技术原理是什么呢?
深度学习背后的技术原理
机器学习
机器学习的本质其实是为了找到一个函数,让这个函数在不同的领域会发挥不同的作用。像语音识别领域,这个函数会把一段语音识别成一段文字;图像识别的领域,这个函数会把一个图像映射到一个分类;下围棋的时候根据棋局和规则进行博弈;对话,是根据当前的对话生成下一段对话。机器学习离不开学习两个字,根据不同的学习方式,可以分为监督学习和非监督学习两种方式。
监督学习中,算法和数据是模型的核心所在。在监督学习中最关键的一点是,我们对训练的每个数据都要打上标签,然后通过把这些训练数据输入到算法模型经过反复训练以后,每经过一次训练都会减少算法模型的预计输出和标签数据的差距。
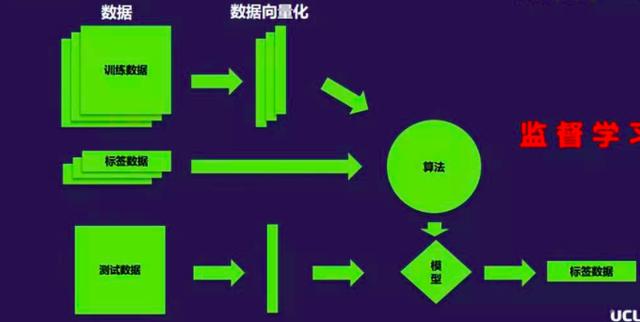
通过大量的训练,算法模型基本上稳定下来以后,我们就可以把这个模型在测试数据集上验证模型的准确性。这就是整个监督学习的过程,监督学习目前在图片分类上应用得比较多。
非监督学习里跟监督学习不同的地方是,非监督学习不需要为所有的训练数据都打上标签。非监督学习主要应用在两个大类,第一类是做聚类分析,聚类分析是把一组看似无序的数据进行分类分组,以达到能够更加更好理解的目的。
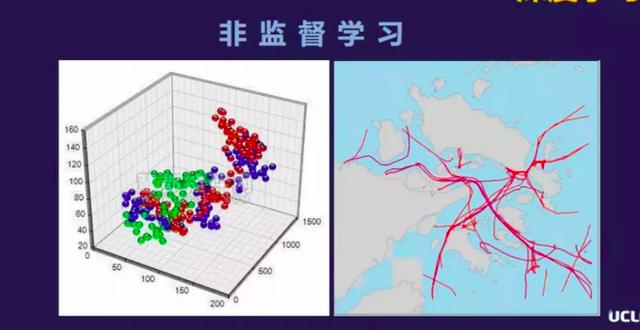
另外是做自动编码器,在数据分析的时候,原始数据量往往比较大,除了包含一些冗余的数据,还会包含一些对分析结果不重要的数据。自动编码器主要是对原始数据做降维操作,把冗余的数据去掉,提高后面数据分析的效率。
通过不同的学习方式获取到数据后,算法是接下来非常重要的一环。算法之于计算机就像大脑对于我们人类,选择一个好的算法也是特别重要的。
神经网络
神经网络是受人脑神经元结构的启发,研究者认为人脑所有的神经元都是分层的,可以通过不同的层次学习不一样的特征,由简单到复杂地模拟出各种特征。
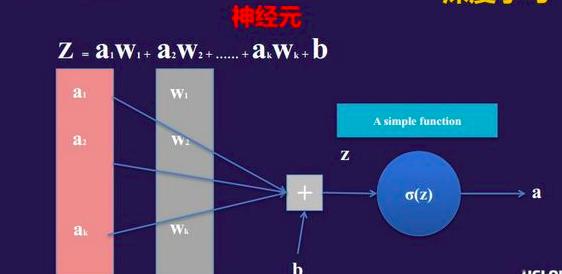
上图是计算机应用数学的方式来模拟人脑中神经元的示意图。a1到ak是信号的输入,神经元会对输入信号进行两次变换。第一部分是线性变换,因为神经元会对自己感兴趣的信号加一个权重;第二部分是非线性变换。
神经网络就是由许多的神经元级联而形成的,每一个神经元都经过线性变换和非线性变换,为什么会有非线性变换?从数学上看,没有非线性变换,不管你神经网络层次有多深都等价于一个神经元。如果没有非线性变换,神经网络深度的概念就没有什么意义了。
卷积神经网络
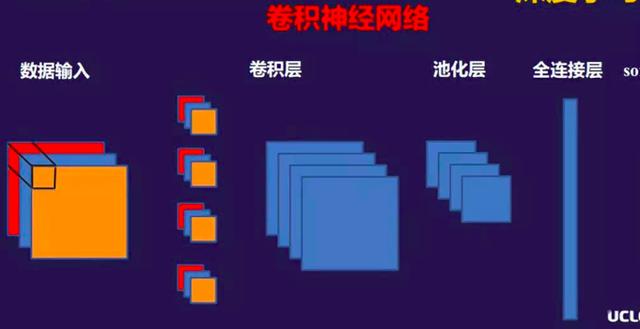
以上所讲的都是一般的全连接神经网络,接下来进入卷积神经网络。卷积神经网络是专门针对图片处理方面的神经网络。卷积神经网络首先会输入一张图片,这张图片有三个颜色通道的数据,这是输入层。下面是卷积层,有一个卷积核的概念,每一个卷积核提取图片的不同特征。
提取出来以后到池化层,就是把卷积层的数据规模缩小,减少数据的复杂度。卷积和池化连起来我们叫做一个隐层,一个卷积神经网络会包含很多个隐层,隐层之后是全连接层,全连接层的目的是把前面经过多个卷积池化层的特征把数据平铺开,形成特征向量,我们把特征向量输入到分类器,对图片进行分类。
简单来说,卷积神经网络更适合计算机视觉主要有两个原因,一是参数共享,另外一个是稀疏连接。
2015年基于深度学习的计算机视觉算法在ImageNet数据库上的识别准确率首次超过人类,同年Google在开源自己的深度学习算法。这些带动中美两国的科学家把计算机视觉算法运用到安防、金融、互联网、物流、零售、医疗、文娱、制造业等不同垂直行业。但在实际的运用当中,由于数据可得性、算法成熟度、服务的容错率等因素的影响,落地的速度开始出现分化。其中,移动互联网、安防、医疗、无人驾驶等发展较慢。
技术发展趋势:
提高预测精度,降低数据标注成本随着技术的不断发展,计算机视觉能够识别信息的种类从最初的文字信息,到人脸,人的体态识别,以及各种不同的物体。
能够识别的精度也从最初的人1:1比对,到用于门禁系统等1:N比对,以及用在黑名单监控等场景的M:N动态监控。除了提高算法精度以外,提高数据标注的效率也是计算机视觉公司重要的课题之一。
企业发展战略开始分化,商汤向左,旷视向右计算机视觉技术在中国的快速落地,吸引了以旷视科技Face++、商汤科技、极链科技Video++为代表的以算法为核心竞争力的AI初创公司,拥有强大数据采集及软件开发能力的互联网公司,以及华为这样的科技巨头。经过一年多的发展,各个公司都已经根据自己资源的不同,战略出现了分化。
各类公司初始时在产业环节中各有偏好,初创企业在算法与模型训练上占优,互联网企业则拥有天然的数据优势,安防企业则凭借极强的工程能力加速安防项目落地。AI头部初创企业近年来融资动作频繁,受到资本市场的青睐,在资金方面暂无瓶颈,然而面临互联网巨头的挑战,各大初创企业应依托已有的独立设计算法的能力,构建平台型解决方案,在研发能力与方案落地速度上取胜。
