商汤科技57篇论文入选ICCV 2019,13项竞赛夺冠
两年一届的ICCV 2019(International Conference on Computer Vision)于10月27日-11月2日在韩国首尔召开!今年的ICCV,商汤科技继续在入选论文数量、质量以及诸多竞赛项目中刷新纪录,彰显中国原创技术的领先性及深厚学术底蕴,引领计算机视觉学术发展。
商汤科技及联合实验室共有57篇论文入选ICCV 2019(包含11篇Oral),同时在Open Images、COCO、LVIS等13项重要竞赛中夺冠!特别是Open Images,它是目前通用物体检测和实例分割两个领域中数据量最大、数据分布最复杂、最有挑战性的竞赛,比COCO数据大一个量级,标注更不规则,场景更复杂。

除了成绩,商汤科技在开放学术交流、生态发展方面也为全球学术领域做出积极贡献,由商汤及联合实验室研究团队去年发布的开源物体检测框架MMDetection,在今年各大比赛中被众多参赛队伍广泛使用,Open Images,COCO,LVIS,Mapillary等比赛中的多支获奖队伍都使用MMDetection作为基准代码库,团队去年提出的HTC、Guided Anchoring等方法成为了今年诸多队伍的关键助力。
ICCV 2019期间,商汤科技还组织或参与主办了多场Challenge和Workshop,香港中文大学-商汤联合实验室的周博磊教授参与组织了上千人的Tutorial——Interpretable Machine Learning for Computer Vision。此外,商汤科技创始人、香港中文大学教授汤晓鸥受邀担任ICCV 2019大会主席。

商汤科技创始人、香港中文大学教授汤晓鸥
受邀担任ICCV 2019大会主席
57篇论文入选ICCV 2019,13个项目夺冠
著名科幻小说家阿西莫夫说,“创新是科学房屋的生命力”。拥有深厚学术底蕴的商汤科技,自成立以来始终以“坚持原创,让AI引领人类进步”为使命,在人工智能技术研究上不断寻求自我突破和创新。此次,商汤科技及联合实验室共有57篇论文入选ICCV 2019,其中口头报告(Oral)论文就有11篇!ICCV论文录用率非常低,今年Oral录用比例仅为4.62%。
商汤科技被ICCV 2019录取的论文在多个领域实现突破,包括:面向目标检测的深度网络基础算子、基于插值卷积的点云处理主干网络、面向AR/VR场景的人体感知与生成、面向全场景理解的多模态分析等。这些突破性的计算机视觉算法有着丰富的应用场景,将为推动AI行业发展做出贡献。
同时,商汤科技不仅在论文录取数上展现出了惊人实力,在ICCV的诸多竞赛项目上也屡屡夺冠,一举斩获13项世界冠军。

在Google AI主办的ICCV 2019 Open Images比赛中,来自香港中文大学和商汤研究院的联合团队夺得了物体检测和实例分割两个主要赛道的冠军。此次主办方提供了千万级别的实例框,涵盖了500类结构性类别,其中包含大量漏标、类别混淆和长尾分布等问题。竞赛中,得益于团队提出的两个全新技术:头部空间解耦检测器(Spatial Decoupling Head)和模型自动融合技术(Auto Ensemble)。前者可以令任意单模型在COCO和Open Images上提升3~4个点的mAP,后者相对于朴素模型融合能提升0.9mAP。最终,在提交次数显著小于其他高名次队伍下获得了双项冠军的好成绩。
在ICCV 2019 COCO比赛中,来自香港中文大学-商汤科技联合实验室和南洋理工大学-商汤科技联合实验室的MMDet团队获得目标检测(Object Detection)冠军(不使用外部数据集),这也是商汤连续两届在COCO Detection项目中夺冠。同时,商汤科技新加坡研究团队也获得COCO全景分割(Panoptic)冠军(不使用外部数据集)。
COCO比赛中,MMDet团队提出了两种新的方法来提升算法性能。针对于当前目标框定位不够精确的缺陷,MMDet团队提出了一种解耦的边缘感知的目标框定位算法(Decoupled Boundary-Aware Localization <DBAL>),该方法专注于物体边缘的信息而非物体全局的信息,使用一种从粗略估计到精确定位的定位流程,在主流的物体检测方法上取得了显著的提升。
而商汤科技新加坡研究团队深入探索了全景分割任务的独特性质,并提出了多项创新算法。由于全景分割任务既涵盖目标检测又包含语义分割,往届比赛队伍大多分别提升目标检测算法与语义分割算法。商汤新加坡研究团队打破惯例,探索了这两项任务的互补性,提出了一种简单高效的联合训练模型Panoptic-HTC。该模型分别借助Panoptic-FPN共享权重的特点与Hybrid Task Cascade联合训练的优势,在特征层面完成了两项视觉任务的统一,从而同时在两项任务上获得显著提升。
在Facebook AI Research主办的第一届LVIS Challenge 2019大规模实例分割比赛中,商汤科技研究院团队获得了冠军,同时获得该项目最佳论文奖。相比于以往的实例分割数据集,LVIS最大的特点在于超过1000多类的类别和更加接近于自然存在的数据长尾分布。这些特点对现有的实例分割算法提出了非常大的挑战。商汤研究团队从原有模型训练的监督方式进行分析,针对长尾问题提出了一种新的损失函数,能够有效的缓解频率高的类别对小样本类别的影响,从而大大提升了处于长尾分布中小样本的性能。另外还通过对额外的检测数据进行有效的利用,减少了因为LVIS数据集构建方式中带来的标注不完全问题,从而进一步提升了性能。
此外,在Facebook AI Research主办的ICCV 2019 自监督学习比赛中,香港中文大学-商汤科技联合实验室和南洋理工大学-商汤科技联合实验室团队一举获得了全部四个赛道冠军;在MIT主办的ICCV 2019 Multi-Moments In Time Challenge比赛中,来自香港中文大学和商汤研究院的联合团队夺得了多标签视频分类赛道的冠军;在Insight Face主办的ICCV 2019 Lightweight Face Recognition Challenge比赛中,来自香港中文大学和商汤研究院的联合团队夺得了大模型-视频人脸识别的冠军;在ETH举办的ICCV AIM 2019 Video Temporal Super-Resolution Challenge比赛中,商汤科技团队获得了冠军;在视觉目标跟踪领域国际权威比赛VOT2019 Challenge比赛中,商汤科技团队获得VOT-RT 2019实时目标跟踪挑战赛冠军。
OpenMMLab成果丰硕,商汤以原创之心会四方学者
为了提高学术界算法的可复现能力以及推动行业学术交流,从2018年年中开始,香港中文大学-商汤科技联合实验室启动OpenMMLab计划,并首先开源了重磅物体检测代码库MMDetection。相比于其它开源检测库,MMDetection有多项重要优点,包括高度模块化设计、多种算法框架支持、显著提高训练效率和密切同步最新算法支持等。
MMDetection和MMAction作为视觉领域的重要任务,在商汤及联合实验室的研究人员共同努力下取得了丰硕成果。今年六月,OpenMMLab第二期发布,多个重要更新吸引了业界目光:MMDetection(目标检测库)升级到1.0,提供了一大批新的算法实现,同时MMAction(动作识别和检测库),MMSkeleton(基于骨骼关键点的动作识别库),MMSR(超分辨率算法库)全新发布。
今年ICCV 大会期间,MMDetection被业界广泛应用,目前在GitHub上已收获近7000 Stars,有效促进目标检测领域的应用和新方法研究发展。
“科学不是一个人的事业”,近代实验科学奠基人伽利略在十六世纪就强调科学研究的交流合作的重要性。海纳百川,取则行远,为推动人工智能行业学术交流和发展,商汤科技在ICCV 2019期间还组织或参与主办了多个Challenge及Workshop。
香港中文大学-商汤联合实验室的周博磊教授参与组织了上千人的Tutorial,该Tutorial主要探讨可解释机器学习的原因、典型方法、未来趋势以及由此产生的可解释机器学习的潜在工业应用。
由商汤科技参与举办的第一届深度统计学习研讨会(The First Workshop on Statistical Deep Learning in Computer Vision)和第二届计算机视觉中的服装艺术与设计研讨会(Second Workshop on Computer Vision for Fashion, Art and Design),都邀请了来自MIT、Berkeley、UCLA、Stony Brook、Johns Hopkins University等多位知名教授在会上做主题报告和分享。
在ICCV展示区(Booth:A-1),商汤科技诸多创新AI产品也亮相世界舞台,包括自动驾驶、SenseAR特效引擎Avatar 、SenseMatrix 物体3D重建 、SenseMatrix 人脸3D重建等11个产品为大会带来丰富的体验和创新灵感。
同时,在10月31日晚,商汤科技还将举办SenseTime PartyTime活动,邀请了来自CV界顶尖学者和科学家,与参会同学代表面对面交流、共话AI学术新动向,培养AI发展的未来生力军。商汤愿以原创之心,会四方学者。
商汤及联合实验室ICCV 2019论文精选
下面,列举几篇商汤及商汤联合实验室入选ICCV 2019的代表性论文,从四大方向阐释计算机视觉和深度学习技术最新突破。
面向目标检测的深度网络基础算子
代表性论文:《CARAFE: 基于内容感知的特征重组》
特征上采样是深度神经网络结构中的一种基本的操作,例如:特征金字塔。它的设计对于需要进行密集预测的任务,例如物体检测、语义分割、实例分割,有着关键的影响。本工作中,我们提出了基于内容感知的特征重组(CARAFE),它是一种通用的,轻量的,效果显著的特征上采样操作。
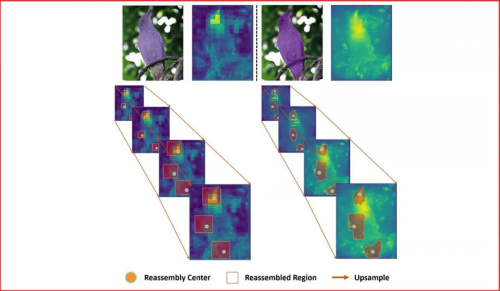
CARAFE有这样一些引人注目的特性:1.大视野。不同于之前的上采样方法(如:双线性插值),仅使用亚像素的临近位置。CARAFE可以聚合来自大感受野的环境特征信息。2.基于特征感知的处理。不同于之前方法对于所有样本使用固定的核(如:反卷积),CARAFE可以对不同的位置进行内容感知,用生成的动态的核进行处理。3.轻量和快速计算。CARAFE仅带来很小的额外开销,可以容易地集成到现有网络结构中。我们对CARAFE在目标检测,实例分割,语义分割和图像修复的主流方法上进行广泛的测试,CARAFE在全部4种任务上都取得了一致的明显提升。CARAFE具有成为未来深度学习研究中一个有效的基础模块的潜力。
面向三维视觉的点云处理基础网络
代表性论文:《基于插值卷积的点云处理主干网络》
点云是一种重要的三维数据类型,被广泛地运用于自动驾驶等场景中。传统方法依赖光栅化或者多视角投影,将点云转化成图像、体素其他数据类型进行处理。近年来池化和图神经元网络在点云处理中展现出良好的性能,但仍然受限于计算效率,并且算法易受物体尺度、点云密度等因素影响。
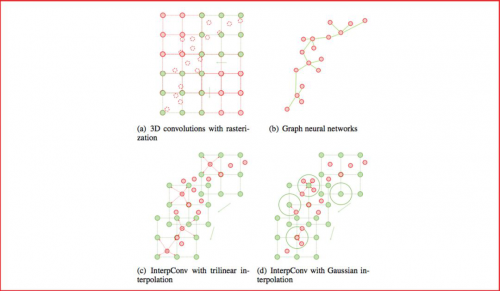
本文提出了一种全新的卷积方式,即插值卷积,能够从点云中高效地学习特征。插值卷积从标准图像卷积和图像插值中获取灵感,卷积核被划分成一组空间中离散的向量,每个向量拥有各自的三维坐标,当点云中的某点落在卷积向量的邻域时,参考图像插值的过程,我们将该点对应的特征向量插值到卷积向量对应的位置上,然后进行标准的卷积运算,最后通过正则化消除点云局部分布不均的影响。
面向不同的任务,我们提出了基于插值卷积的点云分类和分割网络。分类网络采用多路径设计,每一条路径的插值卷积核具有不同的大小,从而网络能够同时捕获全局和细节特征。分割网络参考图像语义分割的网络设计,利用插值卷积做降采样。在三维物体识别,分割以及室内场景分割的数据集上,我们均取得了领先于其他方法的性能。
面向AR/VR场景的人体感知与生成
代表性论文:《深入研究用于无限制图片3D人体重建中的混合标注》
虽然计算机视觉研究者在单目3D人体重建方面已经取得长足进步,但对无限制图片进行3D人体重建依然是一个挑战。主要原因是在无限制图片上很难取得高质量的3D标注。为解决这个问题,之前的方法往往采用一种混合训练的策略来利用多种不同的标注,其中既包括3D标注,也包括2D标注。虽然这些方法取得了不错的效果,但是他们并没有研究不同标注对于这个任务的有效程度。
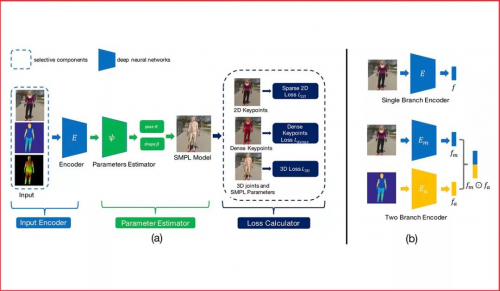
本篇论文的目标就是详细地研究不同种类标注的投入产出比。特别的,我们把目标定为重建给定无限制图片的3D人体。通过大量的实验,我们得到以下结论:1.3D标注非常有效,同时传统的2D标注,包括人体关键点和人体分割并不是非常有效。2.密集响应是非常有效的。当没有成对的3D标注时,利用了密集响应的模型可以达到使用3D标注训练的模型92%的效果。
代表性论文:《基于卷积网络的人体骨骼序列生成》
现有的计算机视觉技术以及图形学技术已经可以生成或者渲染出栩栩如生的影像片段。在这些方法中,人体骨骼序列的驱动是不可缺少的。高质量的骨骼序列要么使用动作捕捉设备从人身上获取,要么由动作设计师手工制作。而让计算机代为完成这些动作,高效地生成丰富、生动、稳定、长时间的骨骼序列,就是这一工作的目标。
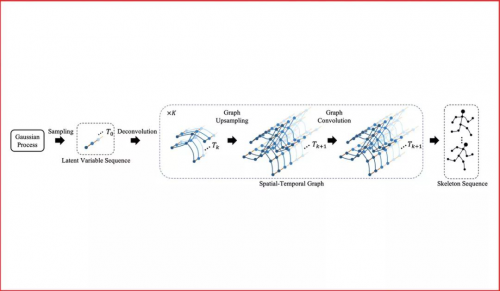
本文使用高斯过程产生随机序列,使用对抗网络和时空图卷积网络来学习随机序列和动作序列之间的映射关系。该方法既可以产生动作序列,也可将动作序列映射到随机序列所在的空间,并利用高斯过程进行编辑、合成、补全。
本方法在由真人动作捕捉得到的NTU-RGB+D数据集上,以及我们收集的虚拟歌手“初音未来”的大量舞蹈设计动作上,完成了详细的对比实验。实验表明,相对于传统的自回归模型(Autoregressive Model),本文使用的图卷积网络可以大大提高生成的质量和多样性。
面向全场景理解的多模态分析
代表性论文:《基于图匹配的电影视频跨模态检索框架》
电影视频检索在日常生活中拥有极大需求。例如,人们在浏览某部电影的文字简介时,时常会被其中的精彩部分吸引而想要看相应的片段。但是,通过文字描述检索电影片段目前还存在许多挑战。相比于日常生活中普通人拍摄的短视频,电影有着极大的不同:1.电影是以小时为单位的长视频,时序结构很复杂。2.电影中角色的互动是构成故事情节的关键元素。因此,我们利用了电影的这两种内在结构设计了新的算法来匹配文本段落与电影片段,进而达到根据文本检索电影片段的目标。
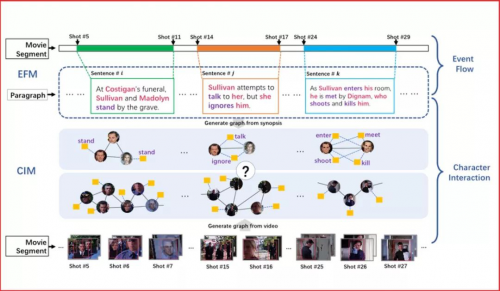
首先,我们提出事件流模块以建模电影的时序特性。该模块基于二分图匹配,将文本中的每一句话按照事件与电影片段的对应子片段匹配。其次,我们提出人物互动模块,该模块通过图匹配算法计算文本中解析得到的人物互动图和视频中提取的人物互动图的相似度。综合两个模块的结果,我们能得到与传统方法相比更精准的匹配结果,从而提高检索的正确率。
代表性论文:《融合视觉信息的音频修复》
多模态融合是交互智能发展的重要途径。在多媒体信息中,一段音频信号可能被噪声污染或在通信中丢失,从而需要进行修复。本文我们提出依据视频信息对缺失音频信息进行修复的一种融合视觉信息的音频修复方案。
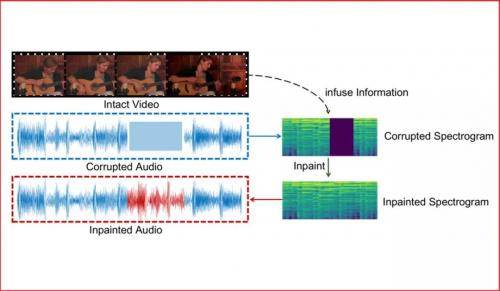
此方案核心思想在于:1.将音频信号在频谱上进行操作,并将频谱作为二维图像信号进行处理,可以极大地利用计算机视觉领域的优势,超越传统的音频解决方案。2.为了融合视觉信息,基于音视频同步学习得到的联合子空间会发挥巨大的优势。
针对此问题的研究,我们将已有的多模态乐器演奏数据集MUSIC扩大成为一个新的更全面的数据集,MUSICES。实验证明我们提出的视觉融合的音频修复系统可以在没有视频信息注入的情况下取得可观的效果,并在加入视频信息后,生成与视频和谐的音频片段。
