基于朴素贝叶斯自动过滤垃圾广告
Python进阶学习交流贝叶斯定理
贝叶斯定理是关于事件A和事件B的条件概率。先认识一下这几个符号:
P(A|B):表示在事件B发生的情况下事件A发生的概率
P(B|A):表示在事件A发生的情况下事件B发生的概率
通常在已知P(A|B)的情况下,计算P(B|A)的值,此时P(A|B)可以称为先验概率,P(B|A)称为后验概率。
这个时候贝叶斯定理就登场啦:
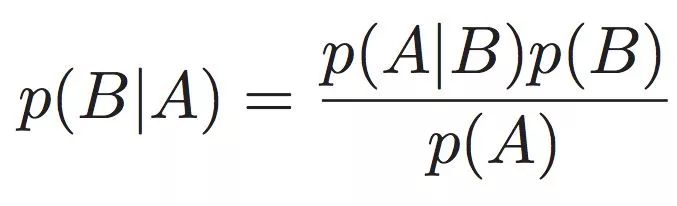
通过这个定理我们就可以计算出P(B|A)的值。举个栗子:
一座别墅在过去的 20 年里一共发生过 2 次被盗,别墅的主人有一条狗,狗平均每周晚上叫 3 次,在盗贼入侵时狗叫的概率被估计为 0.9,在狗叫的时候发生入侵的概率是多少?
我们假设 A 事件为狗在晚上叫,B 为盗贼入侵,则以天为单位统计,P(A) = 3/7,P(B) = 2/(20*365) = 2/7300,P(A|B) = 0.9,按照公式很容易得出结果:P(B|A) = 0.9*(2/7300) / (3/7) = 0.00058
贝叶斯定理延伸
其实到这里只是贝叶斯定理的简单版,下面来看看它的一般版。一般事件B的发生不止有一个影响因素,比如事件B为早上是否吃早餐,那么事件A1可以为几点起床,A2表示为早上是否有课,A3天气是否寒冷,...An食堂早餐卖到几点,这n个事件共同影响事件B是否吃早饭的发生,此时各事件的概率就发生了变化:
P(A)=P(A1,A2,A3,...An)
P(A|B)=P(A1,A2,A3,...An|B)
假设A1,A2,A3,...An都有两种结果,那么一共有2^n个结果,对应需要的样本数也是呈指数增加,这显然是不合实际的,这时,就提出了半朴素贝叶斯和朴素贝叶斯。
这两个定理都有朴素二字,这二字什么意思呢?白话一点就是简化的意思,将A1,A2,A3,...An这n个事件的关联切断,假设它们是相互独立的,即P(A)=P(A1,A2,A3,...An)=P(A1)P(A2)P(A3)...P(An);
P(A|B)=P(A1,A2,A3,...An|B)=
P(A1|B)P(A2|B)P(A3|B)...P(An|B)
这么一朴素,整个过程简单了不止一点点。但是事件A1可以为几点起床和事件A2表示为早上是否有课真的一点关联都没有吗?肯定是有关联的,将相关性很高的一些事件提出,P(A)=P(A1,A2,A3,...An)=
P(A1)P(A2)P(A3)...P(An)P(A1A2);既不忽略事件的相关性,又拥有朴素的特性,这就叫半朴素贝叶斯。
半朴素贝叶斯
朴素贝叶斯分类的正式定义如下:
1、设
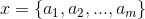
为一个待分类项,而每个a为x的一个特征属性。
2、有类别集合
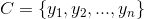
3、计算
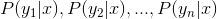
4、如果
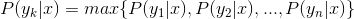
则
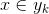
基于属性条件独立性假设,现在来计算P(y1|x),P(y2|x),...P(yn|x)。
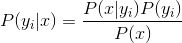
对于所有类别来说P(x)是相同的,因此只需计算分子部分。
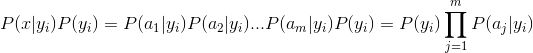
在实际计算时,为了避免下溢(小数点位数过高),一般会对等式两边同时进行Ln变形,将*变为+;这里ln为一个增函数,因此可以保证不改变P(yn|x)的大小排序。
另一个需要注意的点是:样本数是有限的,不可能包括所有的情形,这时会出现P(xn|yi)=0,但是这种情况不出现是不等价于不发生的,这是用到拉普拉斯修正进行平滑:
P(xn|yi)=(N(结果yi发生的前提下xn发生的次数)+1)/(结果yi发生的次数+属性xn所有可能的取值)
数据预处理
上图是这次要用到的原始数据,一行代表一则广告。ham代表有用的广告,spam代表垃圾短信。预处理一共有三部:
第一步:将数据读入进来。
def read_txt():
file = 'C:/Users/伊雅/Desktop/bayes.txt'
with open(file, encoding='utf-8') as f:
con = f.readlines()
return con
第二步:广告存到dataset中,分类结果存储到txt_class中,得到一个词汇表将dataset中的广告用于split为一个一个的单词,并将长度小于1的单词去掉(a)
def create_word_list(con):
reg = re.compile(r'W*')
dataset = []
wordlist = set([])
txt_class = []
for i in con[1:]:
dataset.append(re.split(reg, i)[1:])
wordlist = wordlist | set(re.split(reg, i)[1:])
if re.split(reg, i)[0]=='ham':#有用的邮件
txt_class.append(1)
else:#垃圾邮件
txt_class.append(0)
wordlist=[i for i in wordlist if len(i)>2]
return dataset,wordlist,txt_class
第三步:对每一个广告做循环,通过函数words_vec输入参数为每则广告的单词以及词汇表wordlists,返回一个文档向量,向量的每一个元素为0或1,分别表示词汇表中的单词在广告次中是否出现,如果出现该单词的index则更新为1,否则则为0。
def words_vec(txt,wordlist):
returnvec=[0]*len(wordlist)
for word in txt:
if word in wordlist:
returnvec[list(wordlist).index(word)]=1
return returnvec
经过这三步把单词文本转化为了数学向量,大大简化了计算。
1 2 下一页>
