ALphaGo进化,新一代ALphaGo Zero诞生
据外媒报道,英国DeepMind团队的人工智能研究取得了新进展:他们开发出了新一代的围棋AI-ALphaGo Zero。使用了强化学习技术的ALphaGo Zero,棋力大幅度增长,可轻松击败曾经战胜柯洁、李世石的ALphaGo。
战胜柯洁之后,ALphaGo可以说在围棋界里已是“独孤求败”的境界了,几乎没有人类是它的对手。但是这并不代表ALphaGo就已经对围棋领域的认知达到了顶峰。因此,ALphaGo想要再上一层楼追求围棋知识的上限,显然只有它自己能成为自己的老师。
而在过去,AlphaGo都是使用业余和专业人类棋手的对局数据来进行训练。虽然使用人类棋手的数据可以让ALphaGo学习到人类的围棋技巧,但是人类专家的数据通常难以获得且很昂贵,加上人类并不是机器,难免会出现失误情况,失误产生的数据则可能降低ALphaGo的棋力。因此,ALphaGo Zero采用了强化学习技术,从随即对局开始,不依靠任何人类专家的对局数据或者人工监管,而是让其通过自我对弈来提升棋艺。
那么到底什么是强化学习技术呢?简单地说,强化学习就是让AI从中学习到能够获得最大回报的策略。AlphaGo Zero的强化学习主要包含两个部分,蒙特卡洛树搜索算法与神经网络算法。在这两种算法中,神经网络算法可根据当前棋面形势给出落子方案,以及预测当前形势下哪一方的赢面较大;蒙特卡洛树搜索算法则可以看成是一个对于当前落子步法的评价和改进工具,它能够模拟出AlphaGo Zero将棋子落在哪些地方可以获得更高的胜率。假如AlphaGoZero的神经网络算法计算出的落子方案与蒙特卡洛树搜索算法输出的结果越接近,则胜率越大,即回报越高。因此,每落一颗子,AlphaGo Zero都要优化神经网络算法中的参数,使其计算出的落子方案更接近蒙特卡洛树搜索算法的结果,同时尽量减少胜者预测的偏差。
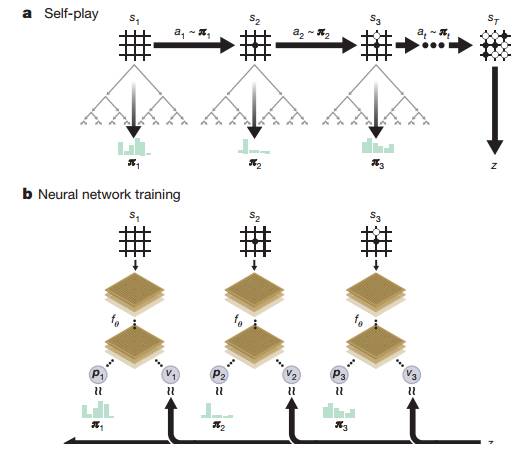
AlphaGo Zero的自我强化学习,图片源自Nature
刚开始,AlphaGoZero的神经网络完全不懂围棋,只能盲目落子。但经历无数盘“左右互搏”般的对局后,AlphaGo Zero终于从从围棋菜鸟成长为了棋神般的存在。
DeepMind团队表示,他们发现AlphaGo Zero自我对弈仅几十天,就掌握了人类几百年来来研究出来的围棋技术。由于整个对弈过程没有采用人类的数据,因此ALphaGo Zero的棋路独特,不再拘泥于人类现有的围棋理论,
DeepMind团队还表示,这个项目不仅仅是为了获得对围棋更深的认识,AlphaGoZero向人们展示了即使不用人类的数据,人工智能也能够取得进步。最终这些技术进展应该被用于解决现实问题,如蛋白质折叠或者新材料设计。这将会增进人类的认知,从而改善每个人的生活。
