如何用Python网络爬虫获取头条所有好友信息?
Python进阶学习交流前言
大家好,我是黄伟。今日头条我发觉做的挺不错,啥都不好爬,出于好奇心的驱使,小编想获取到自己所有的头条好友,
看似简单,那么情况确实是这样吗,下面我们来看下吧。
项目目标
获取所有头条好友昵称
项目实践
编辑器:sublime text 3
浏览器:360浏览器,顺带一个头条号
实验步骤1.登陆自己的头条号:
可以看到2599,不知道谁会是下一个幸运观众了,哈哈哈哈哈,下面我们老样子,打开浏览器,因为我们是要获取到所有的好友啊,所以我们得先进入粉丝列表看看有哪些粉丝吧:
然后右键--审查元素,来一波骚操作,定位粉丝的位置:
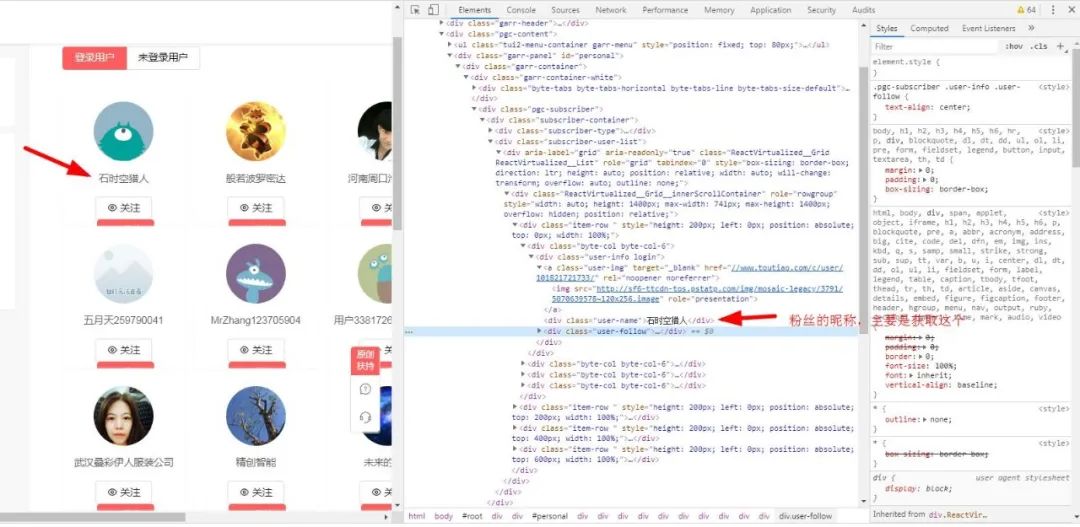
接下来我们要做的就是获取粉丝的昵称,从上面的图可以看出我余下的粉丝都隐藏在ajax加载的动态页面中,如果我不进行滚动则看不到后面的粉丝,那怎么办呢?不过不要紧,遇到问题先不慌,淡定。
2.查找粉丝列表的接口
打开network:
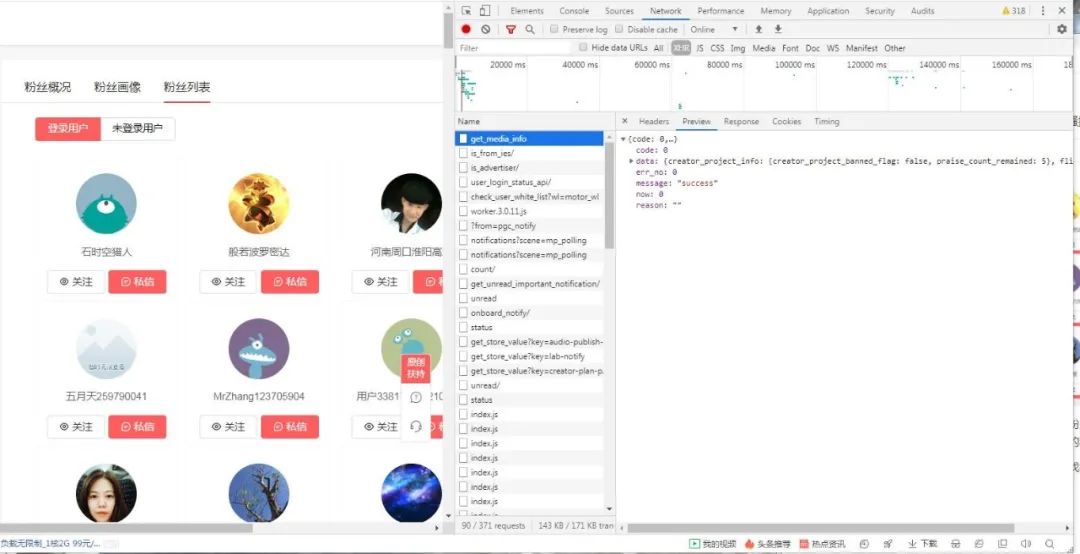
然后你会发现有很多get_info_list 中文译为获取信息列表,我想这应该很重要,打开一看:
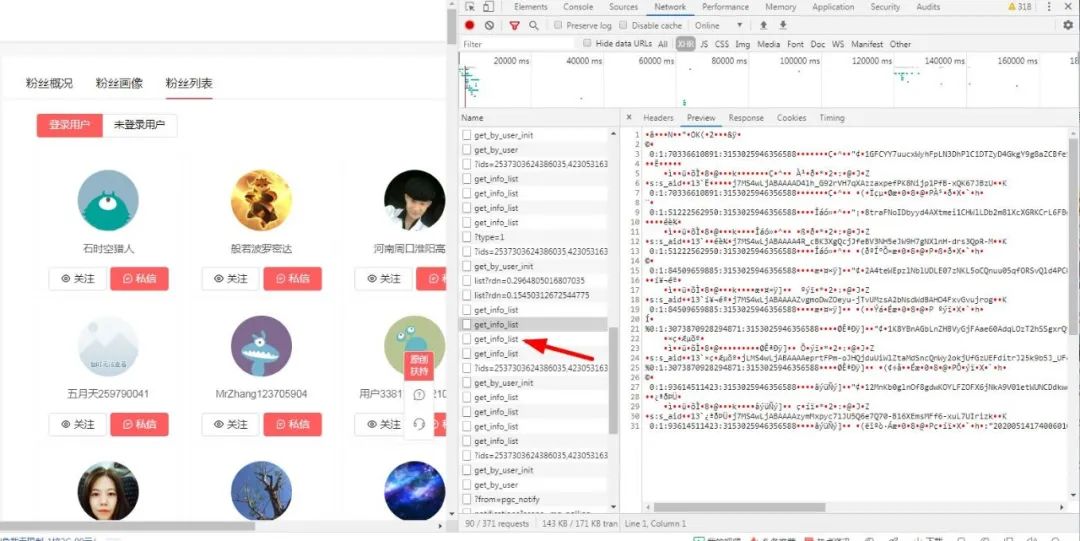
妈妈耶,这啥玩意,吓得我都不会说话了。
3.加载所有请求
于是只好满满滚动鼠标滚轮期待发现点什么,终于,功夫不负苦心人,终于让我滚到了有用的结果:
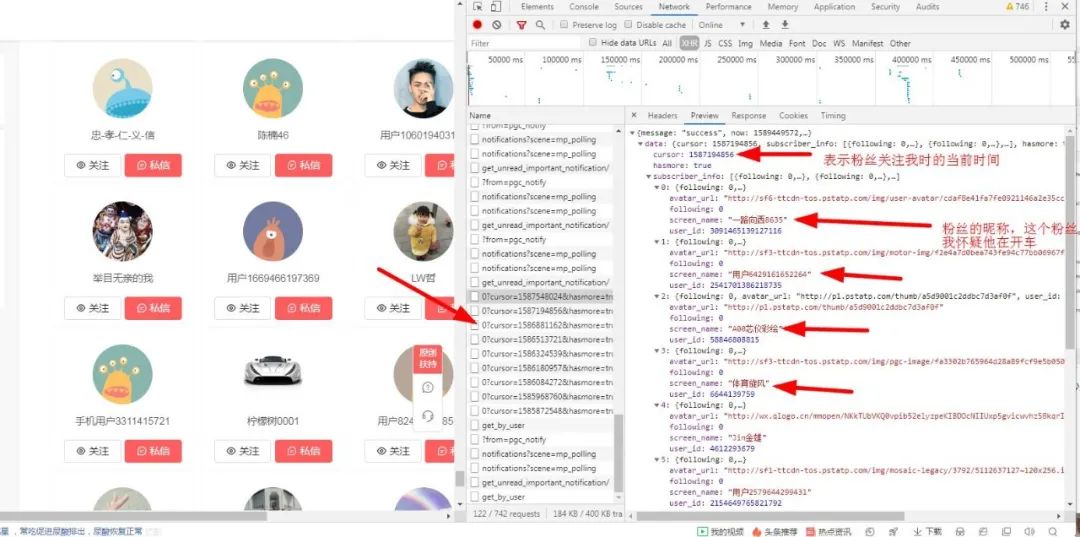
于是我在看看它的头部信息,有重大发现:
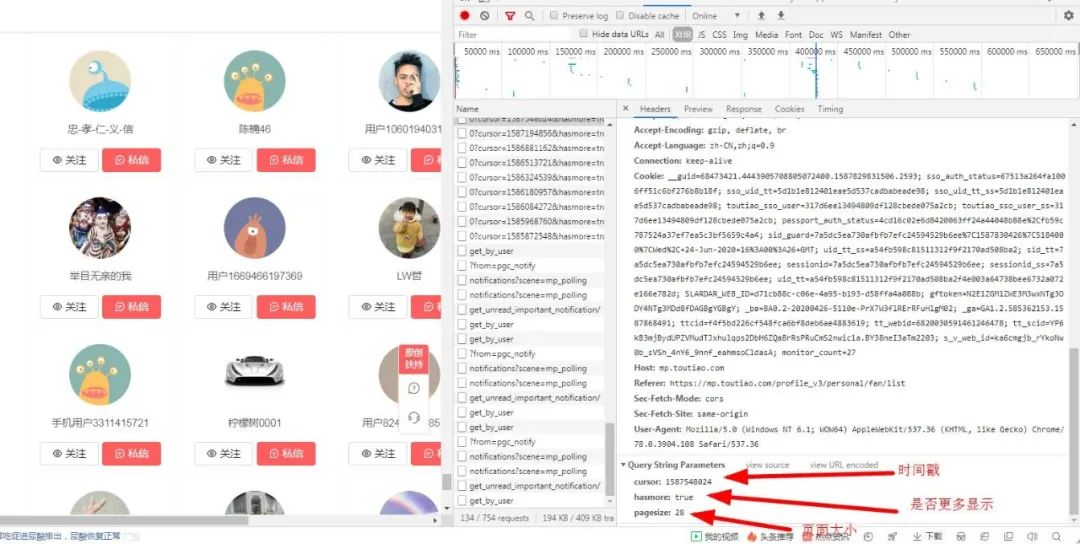
4.找接口分析内容,转换Unicode
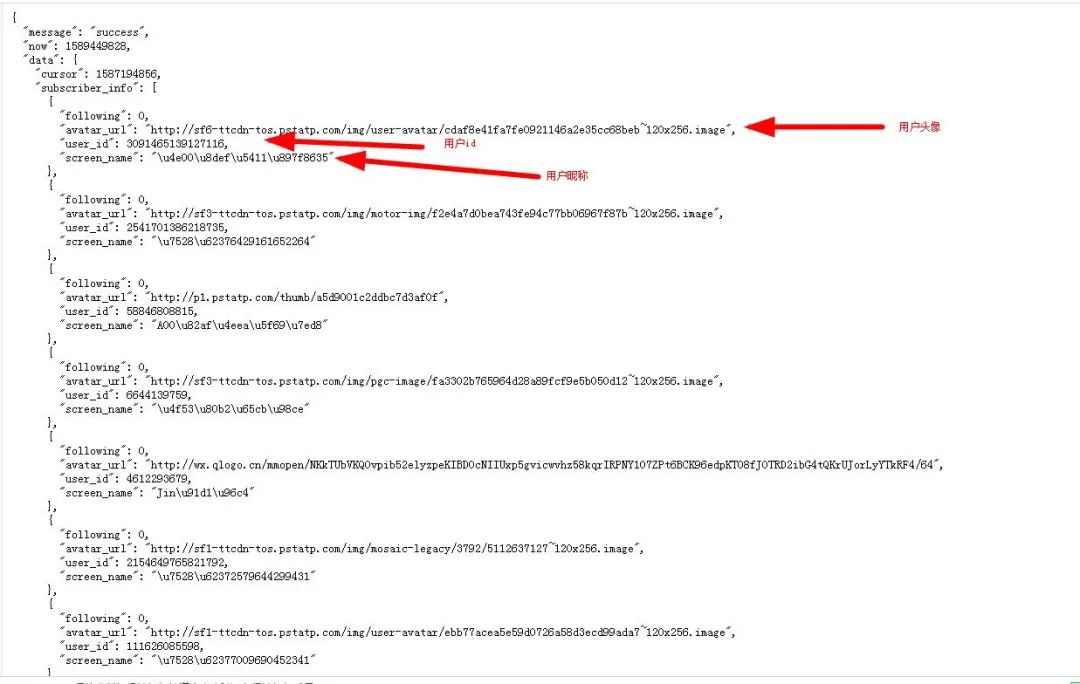
可以看到用户的昵称使用Unicode码表示,所以我们需要将他们转换为中文,关于Unicode转中文,两种方法:
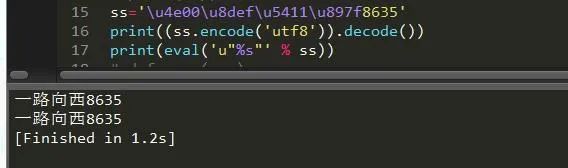
ss='u4e00u8defu5411u897f8635'print((ss.encode('utf8')).decode())print(eval('u"%s"' % ss))
没毛病,老铁。
5.获取页面文件
那我们现在就要获取这个页面的所有结果啦:
发现既然和结果不一样,这是什么骚操作,好吧,我服了。
6.对页面数据进行猜解
通过对上上个图的反复分析,我发现一个很重要的信息,那就是pagesize的值就等于当前页面所显示的粉丝的数量,那小编有2599个粉丝,那pagesize不就是2599吗?哈哈,说干就干:
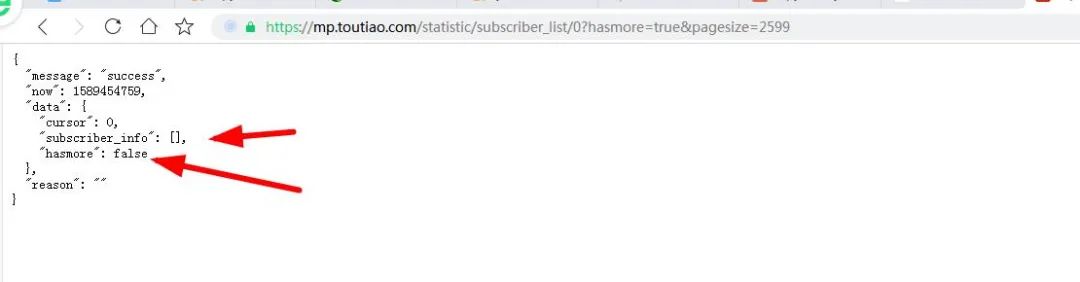
然后小编不断对页面的粉丝进行请求:
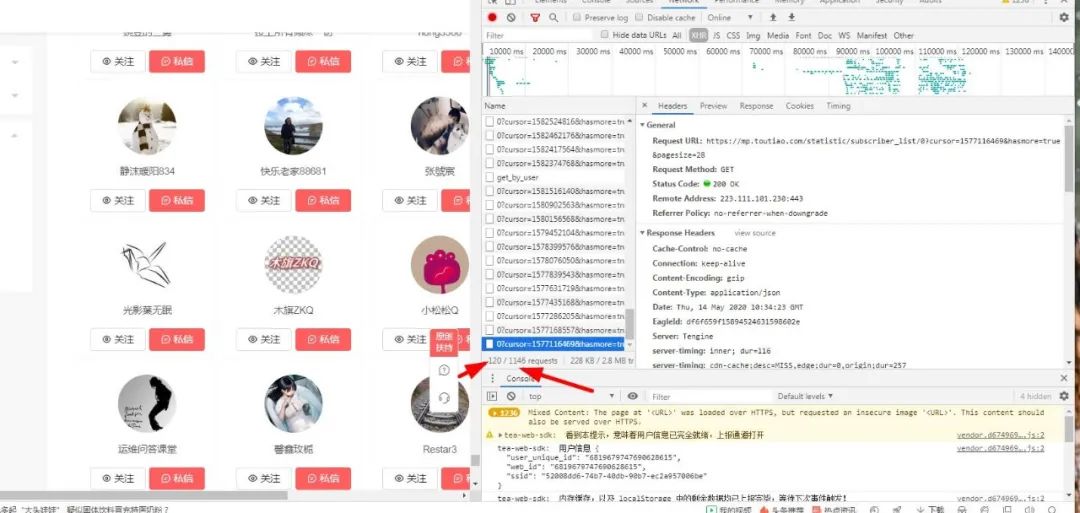
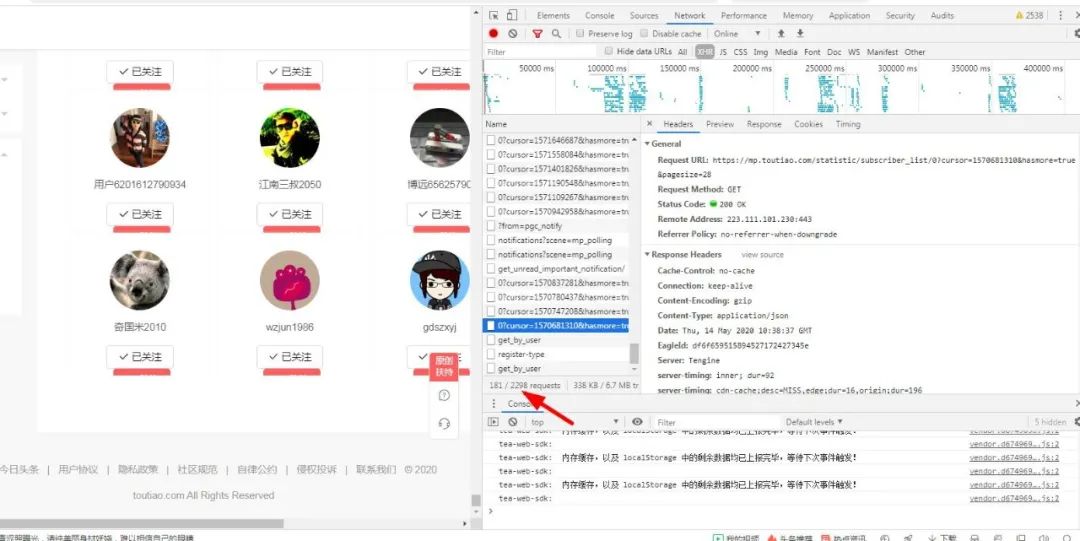
发现还是不行啊,跟我们想的背道而驰,在试试,发现最多只有200才行的通:
其实这个情况下,已经捕捉到所有请求了,只是那些粉丝每28个粉丝分为一个请求,而且每个请求的时间戳不一,其实我们可以用三方软件来捕获这些请求响应然后将他们加入到程序中,我们好对他们进行一个请求分析,最后将他们保存为json格式的文件,然后我们获取到他们对应的值。
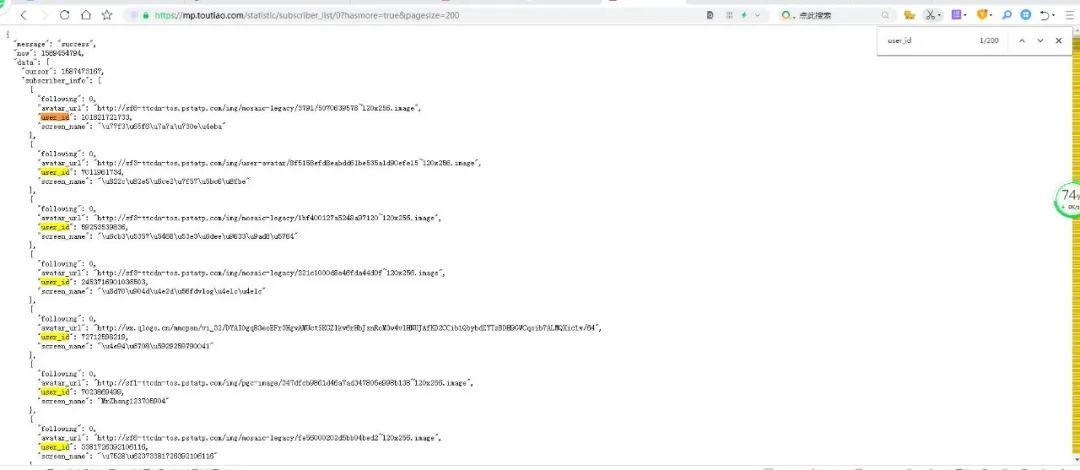
7.打印粉丝名称和响应正常的网址
我们还可以将所有请求中cursor最小的值和最大值拿出来分析,通过查找我找到,
cursor取值:1570591241~1589072863
这个信息很重要,接下来我们就可以依次对这些cursor构建请求了:
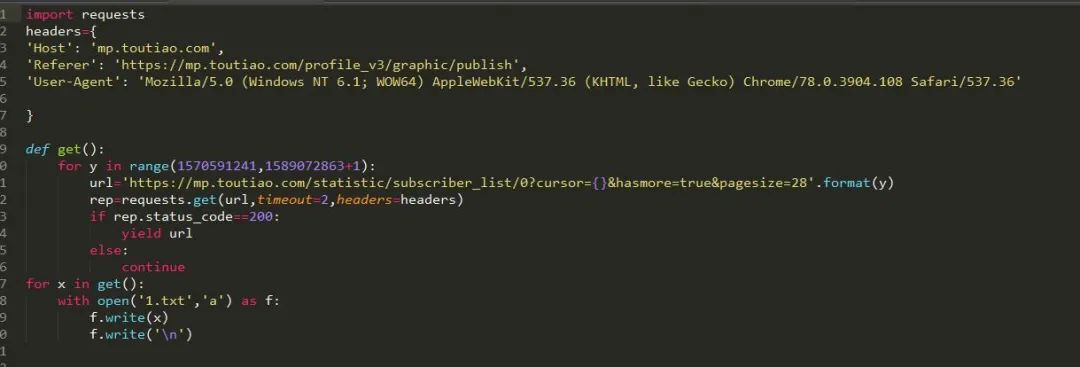
我们将所有能成功请求的页面信息输入到1.txt 文件中去,然后我们在对1.txt中的网页内容逐个读取。然后我们获取他们的json文件保存下来,最后直接把他读取出来就ok啦。由于时间的关系,在此我只演示上图中出现的两百条信息,我们把它保存为json文件然后用json 模块进行读取:
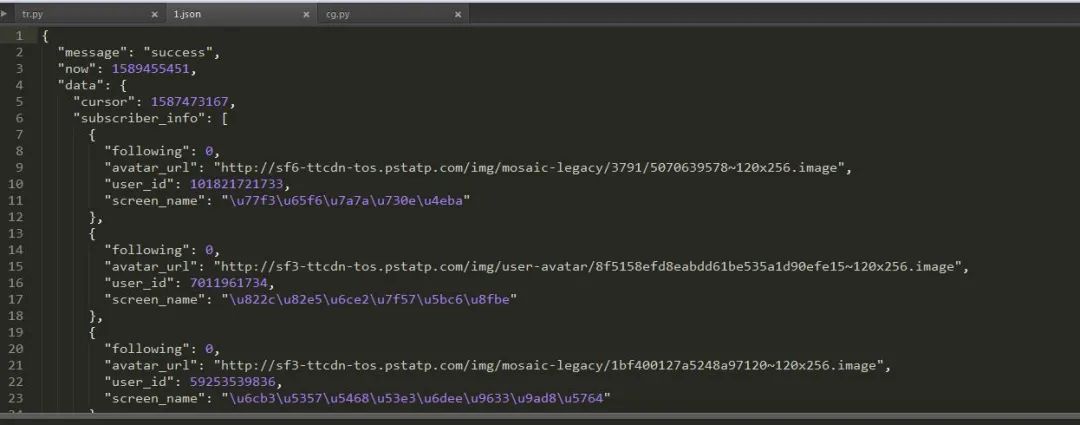
json是系统自带的模块,所以直接导入json模块并读取文件:
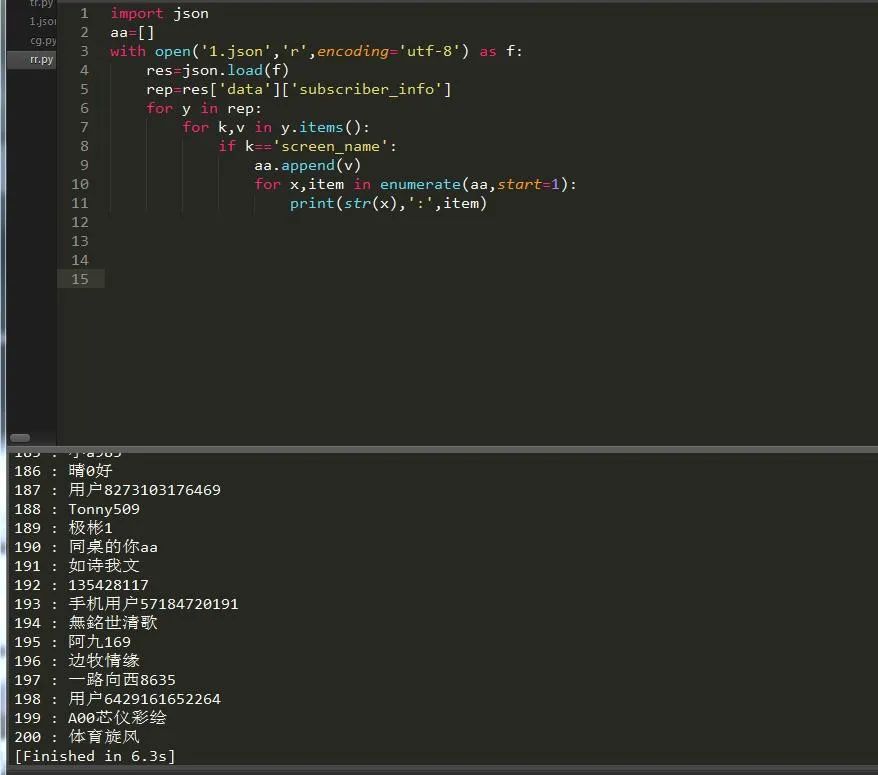
终于全部打印出来啦,哈哈哈,然后我们就可以去获取我们自己关注了哪些人,如果有人把我们取消关注了,那么我们也相应取消对他们的关注。通过一段时间的爬取,终于爬的差不多了,不过我想应该没有爬完,因为网站有反爬:
项目总结
通过对今日头条ajax和一些加密数据的一些情况使我认识到爬虫这条路真的很远,不学js逆向是不可能的。希望大家多多学习,学无止境的。
