深度学习技术如何用于寻找乳腺癌数据集的准确性
磐创AI介绍在本文中,我们将学习一种深度学习技术如何用于寻找乳腺癌数据集的准确性,但我知道大多数技术人员不知道我在说什么,我们将从基础开始,然后继续讨论我们的主题。首先我们简单介绍一下深度学习,什么是人工神经网络?什么是深度学习?如果我们谈论深度学习,那么可以简单地理解它是机器学习的一个子集。我们可以说深度学习是一种人工智能功能,它模仿人脑并处理该数据并创建用于决策的模式。深度学习是一种类似于人脑的机器学习类型,它使用称为神经网络的多层算法结构。它的算法试图复制人类将使用给定逻辑结构分析数据的数据。它也被称为深度神经网络或深度神经学习。
在深度学习中有一个叫做人工神经网络的概念,我们将在下面简要讨论:人工神经网络顾名思义,人工神经网络,就是人工神经元的网络。它指的是模仿大脑的生物启发模型。可以说,构建人脑结构的通常是基于生物神经网络的计算网络。大家都知道,在我们的大脑中,神经元是相互连接和传递数据的过程。它类似于人脑神经元之间相互连接,神经网络由大量人工神经元组成,称为按层顺序排列的单元。具有各层神经元并形成一个完整的网络。这些神经元被称为节点。它由三层组成,分别是:输入层隐藏层输出层
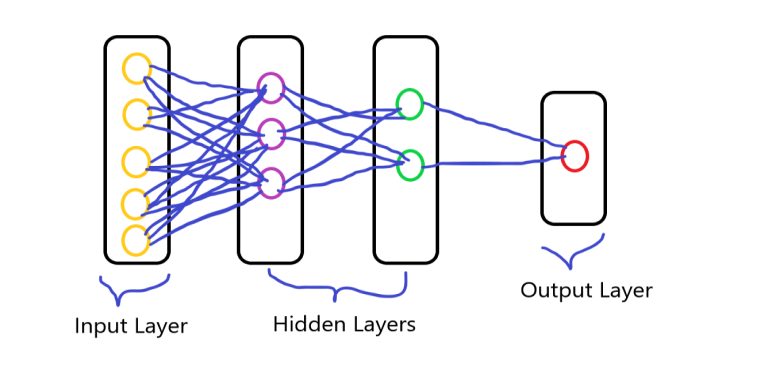
使用乳腺癌数据集创建ANN现在我们进入我们的主题,这里我们将采用数据集,然后创建人工神经网络并对诊断进行分类。首先,我们采用乳腺癌的数据集,然后继续前进。

下载数据集后,我们将导入所需的重要库。
导入库#import pandas
import pandas as pd
#import numpy
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sb
这里我们导入了 pandas、NumPy 和一些可视化库。现在我们使用pandas加载我们的数据集:df = pd.read_csv('Breast_cancer.csv')
df
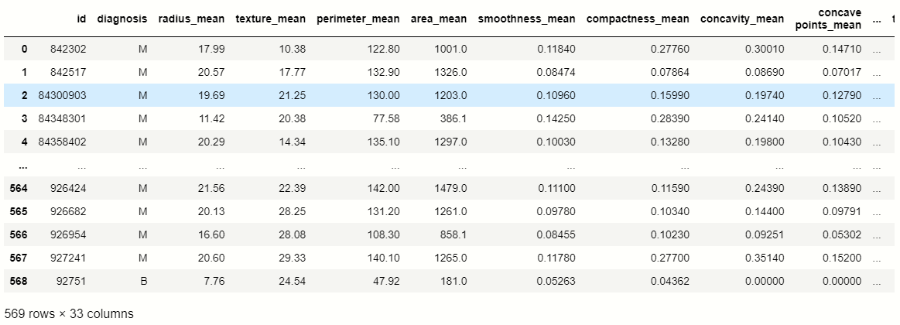
在此数据集中,我们指向**“diagnosis”**特征列,因此我们使用 Pandas 检查该列的值计数:# counting values of variables in 'diagnosis'
df['diagnosis'].value_counts()

现在为了更好地理解,我们可视化“diagnosis列”的值计数。可视化值计数plt.figure(figsize=[17,9])
sb.countplot(df['diagnosis'].value_counts())
plt.show()
空值在数据集中,我们必须检查我们使用pandas的变量中是否存在空值:df.isnull().sum()
执行程序后,我们得出结论,特征名称“Unnamed:32”包含所有空值,因此我们删除该列。#droping feature
df.drop(['Unnamed: 32','id'],axis=1,inplace=True)
自变量和因变量现在是时候将数据集划分为自变量和因变量了,为此我们创建了两个变量,一个代表自变量,另一个代表因变量。# independent variables
x = df.drop('diagnosis',axis=1)
#dependent variables
y = df.diagnosis
处理分类值当我们打印因变量y 时,我们看到其中包含分类数据,我们必须将分类数据转换为二进制格式以进行进一步处理,因此我们使用 Scikit learn Label Encoder 对分类数据进行编码。from sklearn.preprocessing import LabelEncoder
#creating the object
lb = LabelEncoder()
y = lb.fit_transform(y)
拆分数据现在是时候将数据拆分为训练和测试部分了:from sklearn.model_selection import train_test_split
xtrain,xtest,ytrain,ytest = train_test_split(x,y,test_size=0.3,random_state=40)
缩放数据当我们创建人工神经网络时,我们必须将数据缩放为更小的数字,因为深度学习算法将节点的权重和输入数据相乘,这需要大量时间,因此为了减少该时间,我们缩放数据。对于缩放,我们使用 scikit learn StandardScaler模块,我们缩放训练和测试数据集:#importing StandardScaler
from sklearn.preprocessing import StandardScaler
#creating object
sc = StandardScaler()
xtrain = sc.fit_transform(xtrain)
xtest = sc.transform(xtest)
从这里我们开始创建人工神经网络,为此我们导入用于创建 ANN 的重要库:#importing keras
import keras
#importing sequential module
from keras.models import Sequential
# import dense module for hidden layers
from keras.layers import Dense
#importing activation functions
from keras.layers import LeakyReLU,PReLU,ELU
from keras.layers import Dropout
创建层导入这些库后,我们创建了三种类型的层:输入层隐藏层输出层首先,我们创建模型:#creating model
classifier = Sequential()
Sequential模型适用于每一层恰好有一个输入张量和一个输出张量的平面堆栈。现在我们创建神经网络的层:#first hidden layer
classifier.add(Dense(units=9,kernel_initializer='he_uniform',activation='relu',input_dim=30))
#second hidden layer
classifier.add(Dense(units=9,kernel_initializer='he_uniform',activation='relu'))
# last layer or output layer
classifier.add(Dense(units=1,kernel_initializer='glorot_uniform',activation='sigmoid'))
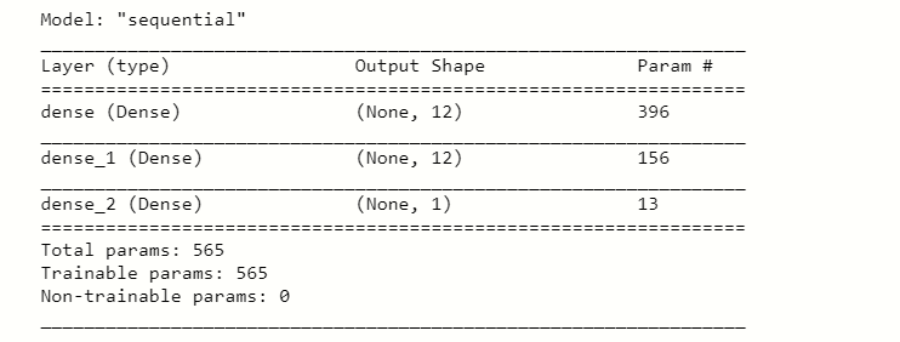
在以下代码中,使用 Dense 方法创建图层,因为我们使用基本参数。第一个参数是输出节点第二个是内核权重矩阵的初始化器第三个是激活函数最后一个参数是输入节点或独立特征的数量。执行此代码后,我们使用以下方法对其进行总结:#taking summary of layers
classifier.summary()
编译人工神经网络现在我们用优化器编译我们的模型:#compiling the ANN
classifier.compile(optimizer='adam',loss='binary_crossentropy',metrics=['accuracy'])
将 ANN 拟合到训练数据中编译模型后,我们必须将 ANN 拟合到训练数据中以进行预测: #fitting the ANN to the training set
model = classifier.fit(xtrain,ytrain,batch_size=100,epochs=100)

fit()方法将神经网络与训练数据进行拟合,在参数中设置batch_size、epochs等变量的具体值。在训练数据之后,我们还要对测试数据的准确性评分进行测试,如下所示:#now testing for Test data
y_pred = classifier.predict(test)
在执行此代码时,我们发现 y_pred 包含不同的值,因此我们将预测值转换为阈值,如True, False。#converting values
y_pred = (y_pred>0.5)
print(y_pred)

分数和混淆矩阵现在我们检查混淆矩阵和预测值的分数。from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
cm = confusion_matrix(ytest,y_pred)
score = accuracy_score(ytest,y_pred)
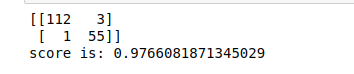
print(cm)
print('score is:',score)
输出:
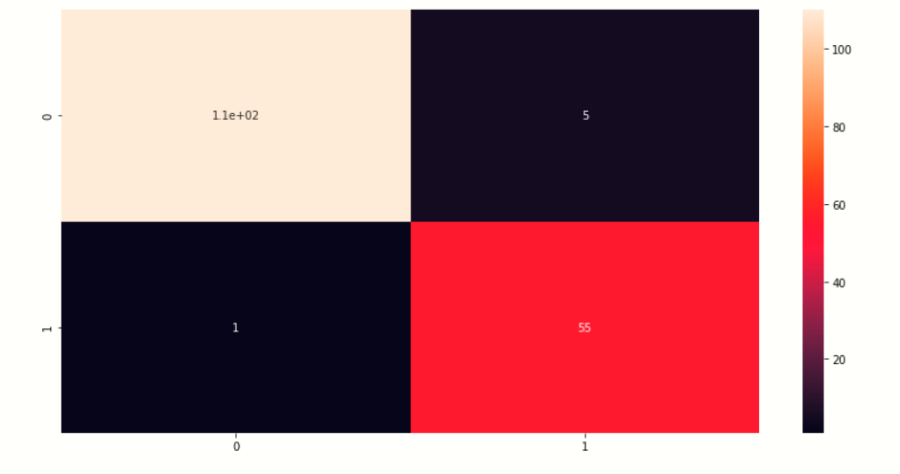
可视化混淆矩阵在这里,我们可视化预测值的混淆矩阵# creating heatmap of comfussion matrix
plt.figure(figsize=[14,7])
sb.heatmap(cm,annot=True)
plt.show()
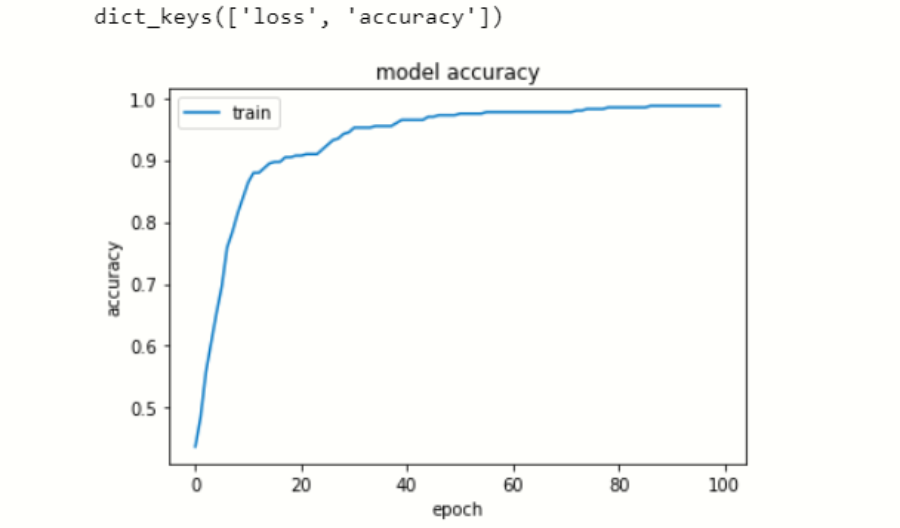
可视化数据历史现在我们可视化每个时期的损失和准确性。# list all data in history
print(model.history.keys())
# summarize history for accuracy
plt.plot(model.history['accuracy'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
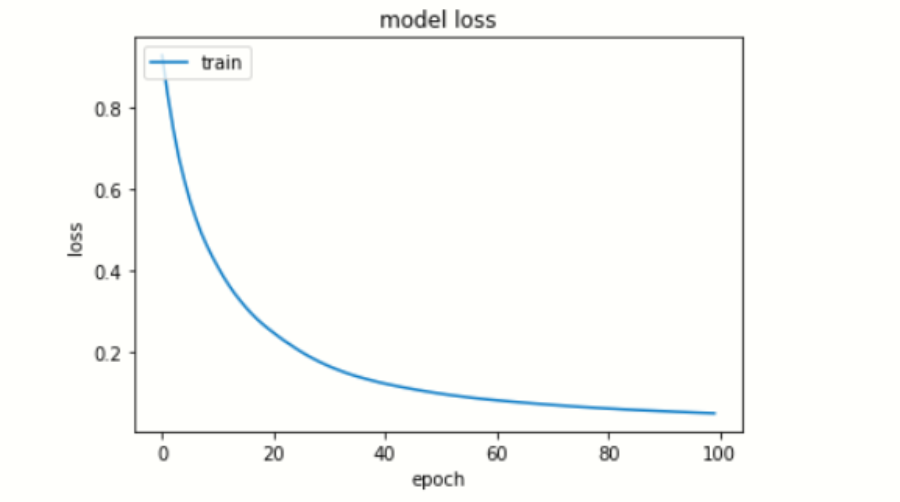
# summarize history for loss
plt.plot(model.history['loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
保存模型最后,我们保存我们的模型#saving the model
classifier.save('File_name.h5')
