深度学习,从「框架」开始学起
易心STEAM编程目前当红的人工智能(Artificial intelligence,AI)主要聚焦在深度学习(DeepLearning,DL)领域,想学习深度学习技术的人,第一步通常会遇到一大堆框架(Framework)却不知如何选择,而究竟什么是框架?框架如何用来表示模型?哪些才是主流框架?本文将会完整告诉你,协助找出最符合自己需求的框架。
何谓深度学习框架?
深度学习简单示意图
大家都知道只要准备一张纸和一只笔,加上源源不断的灵感,就能将想法转化成文字,创作出一篇令人感动的文章。但现在手写创作的人越来越少,只好选用一项电子书写(数字表达)的工具来创作。以Windows举例,可能用的是Note Pad(笔记本)、Word或PDF Editor,如果是学术写作的人可能较常用的是Latex,在网页上创作则可能是Html。
文章的好坏并不会因为工具的改变而有所不同,却会影响写作效率以及排版美观,改变读者对这篇文章的评价。虽然文章内容(基本元素)可轻易的在不同工具中转换,但遇到字体格式、图片、公式等特殊排版需求时,可能出现档案转不过去等问题,同时难以用来表达音乐、影像、视频。
在解决深度学习的问题中,较常见的是非时序性辨识问题,以及时序性的分析或预测问题。为了方便表达模型(Net /Model)的结构、工作训练以及推论流程,因此产生了框架,用来正确表达深度学习的模型,就像在Windows上写文章需要有Note Pad、Word等,编辑影音内容要有威力导演、After Effect等一样。
因此,许多学术单位、开源社群甚至Google、Microsoft、Facebook这类知名大公司也纷纷推出自家的框架,以确保在这场AI大战中能占有一席之地。而有另一派人马,想要产生另一种可轻易转成各家的框架,例如微软的Word可以另存网页档(*.html)、可携式文件格式(*.pdf)、纯文本档(*.txt)等。在介绍各家框架前,先来认识一下深度学习的模型究竟用了哪些元素?就像玩乐高积木前,要先知道有哪些模块可用,后续在学习各个框架的表示语法时才不会一头雾水。
常见深度学习模型介绍
首先介绍两个较著名的模型,包括非时序性的卷积神经网络(CNN) LeNet-5 [1]以及时序性的递归神经网络(RNN),方便说明模型中常用到的元素与流程,如何用深度学习框架来表示。
卷积神经网络(CNN)
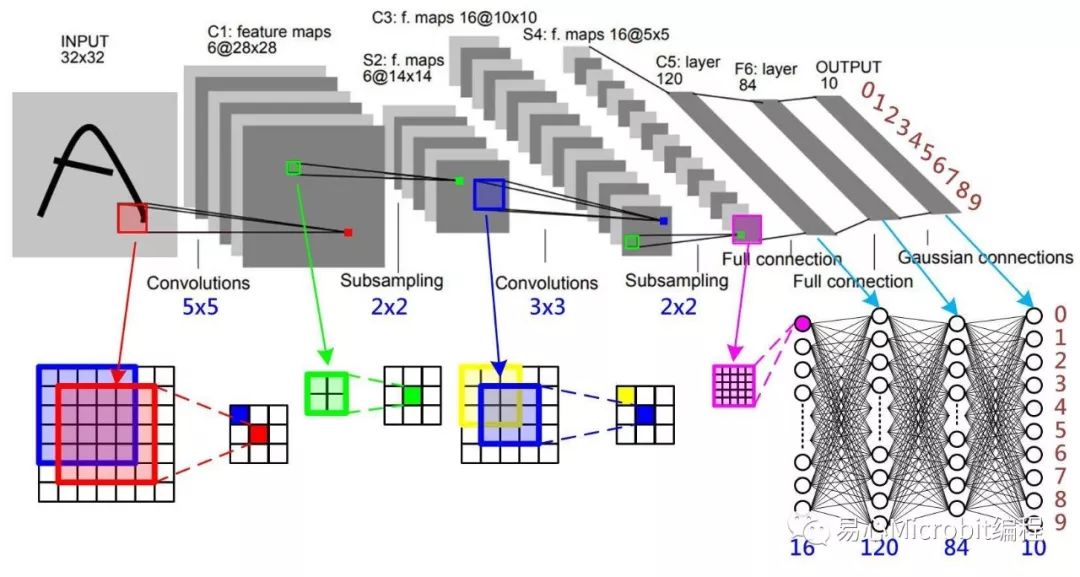
图一卷积神经网络(CNN) LeNet-5 [1]
(图一)为最知名的卷积神经网络LeNet-5,主要是用来辨识手写数字(MNIST数据库),输入为一张8bit灰阶32×32像素的影像,而输出为十个节点,分别表示影像为十个数字的机率,这个模型几乎是所有研究深度学习的入门起手式。目前先不解释这个模型为何能学会辨识图像,而是单纯就模型组成以及表示方法来进行说明。
首先,说明卷积特征图 C1层,C1层上的红点,是由输入层(INPUT)红色框(5×5个像素)乘上5×5的卷积核加总后而得,依序由输入影像的左至右、上至下共享一个卷积核进行卷积,一次移动一个像素(Stride=1),如此即可产生一张特征图,而C1层共享了六组卷积核,因此产生六张28×28像素的特征图。再来将影像进行池化,较常见的方式就是把相邻四点(如图一绿色框所示)中最大的点当成新点,称为Max Pooling,同时把影像长宽都减为一半,成为S2层。
接下来,对S2层以16组3×3卷积核进行卷积,产生C3层,共有16组10×10像素的特征图。同样地再对C3层进行池化产生S4层,变成16组5×5像素的特征图,最后再以16组5×5卷积核把S4层的16个特征图卷积变成16个输入点,再以传统全链接神经网络进行链接。C5层就是以16个输入点和隐藏层120点进行全连结,并依指定的激活函数将输出传到下一层,接下来再和下一组隐藏层F6的84点进行全连结,最后再和输出层(OUTPUT)的十个输出点进行全连结,并正规化输出得到各输出的机率,即完成整个LeNet-5模型(网络)结构。
综合上述内容可得知一个基本的卷积神经网络会有输入层、卷积层、池化层、全连结层及输出层。卷积层要定义卷积核大小、移动距离、输出特征图数量。而池化层同样需要定义核的大小(一般是2×2)、移动距离(一般是2)及池化方式(可以是取最大值或平均值)。全连结层部份则需要定义节点数量及激活函数类型(如:reLu、sigmoid等),最后输出层除了要定义正规化机率值(如:Softmax)外,还要定义损失函数以作为训练模型用。
前面提到的卷积神经网络CNN是一种前馈(Forward)的单向网络,其输出结果不会影响输入,但如果遇到如语音、翻译、视频这类时序问题时,CNN就搞不定了,此时就该轮到递归神经网络(RNN)登场了。
递归神经网络(RNN)
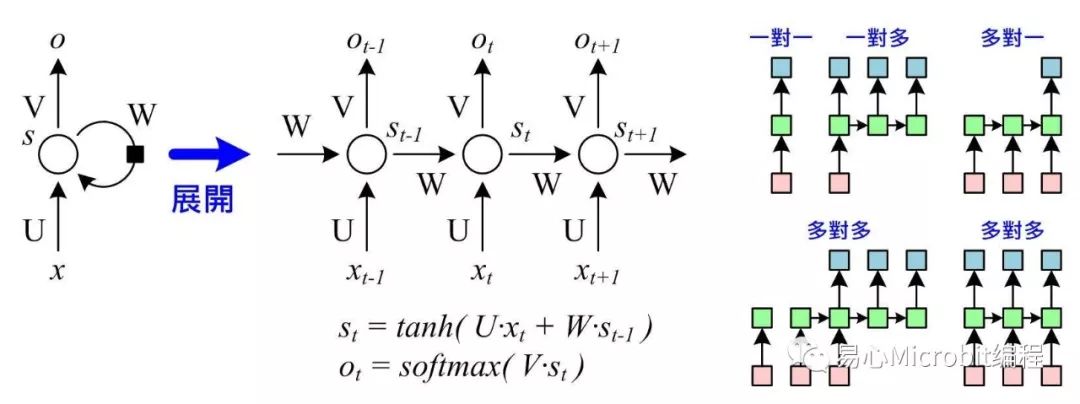
图二 递归神经网络(RNN)及型态
(图二)左图所示就是RNN最基本入门的模型,把此次输出的结果经过加权后,再和下一次的输入一起计算出下一次的输出,以串起输入数据的时序关连。从展开图可更清楚看出其关连,当前输出(ot)是由目前状态(st)乘上权重(U)加上前一状态(st-1)输出乘上权重(W)后,经过双曲正切(tanh)函数并乘上输出权重(V),最后取Softmax算式得出,依此类推可展开成任意级数的网络。
(图二)右图所示,RNN可以有很多种输出型态,一对一就等于单纯的前馈网络没有时序关系,另外也可以一对多、多对一、多对多等不同的输出方式,应用于时序性内容分类,例如语句情绪意图、音乐曲风、视频动作分析、影像加注标题等,或是型态移转(Style Transfer),例如语言翻译、文章音乐创作等。
对RNN而言,需要定义展开的级数、隐含层(或称为状态S)到隐含层权重矩阵(W)、输入层到隐含层权重(U)、隐含层到输出层权重(V)、激活函数(例如:tanh等)类型,以及输出层机率正规化方式(例如:Softmax等)。
常见深度学习框架及选用考虑

图三 常见深度学习框架
许多人准备开始进入深度学习世界时,最常问的问题就是到底要挑选哪一种框架来入门?有如(图三) 、(表格一)所示,从最大的开源社群Github上,就可找到二十种星星数超过一千的深度学习框架,包括TensorFlow、Keras、Caffe、PyTorch、CNTK、MXNet、DL4J、Theano、Torch7、Caffe2、Paddle、DSSTNE、tiny-dnn、Chainer、neon、ONNX、BigDL、DyNet、brainstorm、CoreML等,而排名第一名的TensorFlow更有近十万个星星。由此可知,深度学习非常受到大家重视,当选择深度框架时可以从好几个面向来考虑,以下将会分别介绍。
1. 程序语言
首先是开发时所使用的程序语言,如果要执行「训练」及「推论」效率好些,则可能要用C++。若要上手容易、支持性强,则要考虑Python,从(表格一)中可看出有3/4的框架都支援Python。
若习惯使用Java开发程序,那大概就只有TensorFlow、DL4J和MXNet可选了。目前有一些框架(如TensorFlow、Caffe等)底层是C++,应用层API是用Python,这类框架能取得不错的开发及执行效率。
若想改善底层效率时,还要考虑依不同硬件,学会OpenCL或Nvidia的CUDA/cuDNN等平行加速程序写法。
2. 执行平台
再来考虑的是可执行的操作系统及硬件(CPU、GPU)平台,目前大多数的框架都是在Linux CPU+GPU的环境下执行,部份有支持单机多CPU(多线程)或多GPU协同计算以加速运行时间,甚至像TensorFlow、CNTK、DL4J、MXNet等框架还有支持丛集(Cluster)运算。
许多云端服务商(Google、Amazon、Microsoft等)也是采取这类组合,方便布署开发好的应用程序。另外也有些非主流的框架(如:tiny-dnn)只支持CPU而不支持GPU,这类框架的好处就是移植性较强,但工作效率很差,较适合小型系统。
如果是用Windows的人,英特尔(Intel)及微软(Microsoft)也分别有提供BigDL及CNTK,若使用Mac系统则要考虑使用CoreML。不过最近Google的TensorFlow为了吃下所有的市场,已经可以支持Linux、Windows、Mac甚至是Android,因此成为开源排行榜第一名。
3. 模型支持
目前常见的深度学习模型包含监督型(如CNN)、时序型(如RNN/LSTM)、增强学习(如Q-Learning)、转移学习、对抗生成(GAN)等,但不是每个框架都能全部支持。
举例来说:老牌的Caffe适合做监督型学习,但对于时序型学习就不太合适,遇到对抗生成模型时就更使不上力。若不清楚那些框架可支持的模型类型,可参考(表格一)的对应网址,前往各官网了解使用上的限制。
4. 框架转换
如果遇到需要串接不同平台或框架时,则要考虑选用具有提供跨框架功能。目前有几大阵营,像Keras可支持TensorFlow、Theano、MXNet、DL4J、CNTK,而微软和脸书联盟推的ONNX可支持Caffe2、CNTK、PyTorch等,但Google的TensorFlow却不愿加入该联盟。
另外,虽然框架之间可以转换,但不代表转换后的执行效率会和直接使用某个框架一样好,此时只能依实际需求来取舍是否拿弹性换取效能。
5. 社群支援
最后要考虑选用的框架社群是否活跃,是否很久没有维护(升级),甚至被预告即将淘汰,像Theano虽然功能强大也有很多人在用,但目前确定已不再更新版本,因此建议不要再跳坑了。另外对于英文不好的朋友,选用框架的社群讨论区、文字教程、操作视频等是否有中文支持也是很重要的,以免遇到问题不知向谁求救。
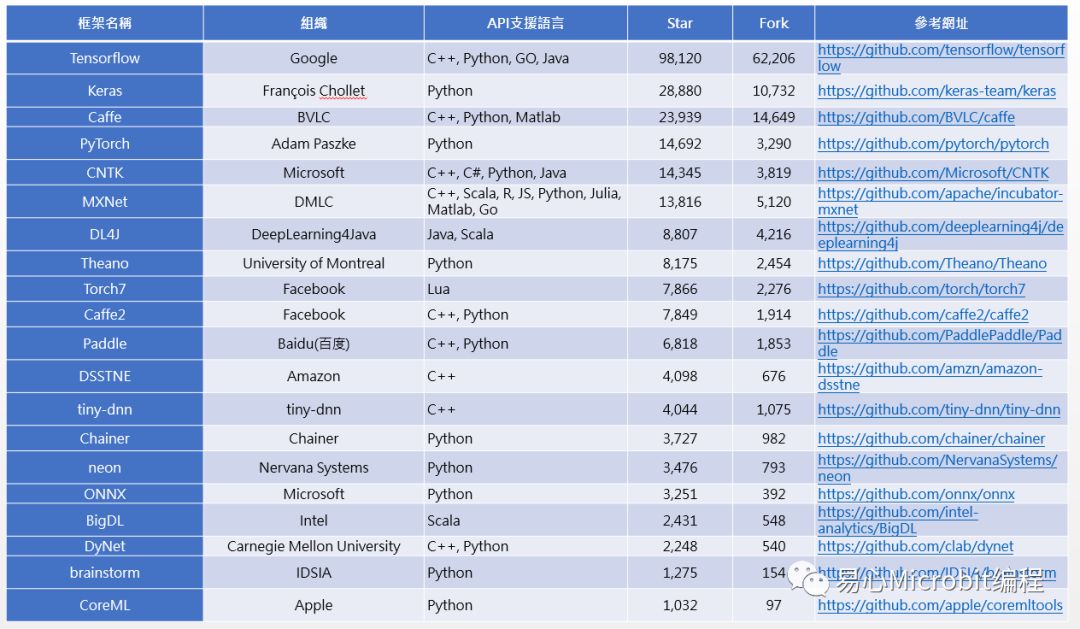
表格一 深度学习框架比较表
总结
对于新手来说,目前用Python+Keras+TensorFlow是最多人的选择,网络上也可取得最多资源(包含中文),可支持的操作系统、硬件平台、模型以及数学函式库也是最丰富的。特色是弹性大,相对容易开发,也是最容易布署在云端的解决方案。
但这样的组合并非完全没有缺点,例如CNTK的执行效率相较于MXNet略差,而Python需占用较多内存,不利于布署在本地端(或嵌入式系统)进行边缘计算,因此如何选择合适的框架,有赖于大家多花点心思了。
作者:许哲豪
