Magic Leap公布透过MLO的演示视频,以及其他更多细节
AR酱Magic Leap在Twitch上的几次直播演示可以说都在画饼,对于实机以及操作并没有进行深入的讲解,这也让大家对于它如何运作充满了各种假设以及好奇心。
在前几天,也就是6月21日的Unite Berlin大会上,Magic Leap讲解了如何开发Magic Leap One,在其中包含了诸多Magic Leap One工作及运行的细节,那就让我们一起来看看吧。最关键的是,Magic Leap终于向我们演示了通过Magic Leap One的AR。
首先他们提出的是通过他们的技术,Magic Leap One的AR会真实的融入到环境当中去,可以让用户和平时一样观看,而不是与现在的AR眼镜一样叠加在视野的上方。不过他们并没有讲解他们用的是什么技术,就当成他们画的另外一张大饼算了。
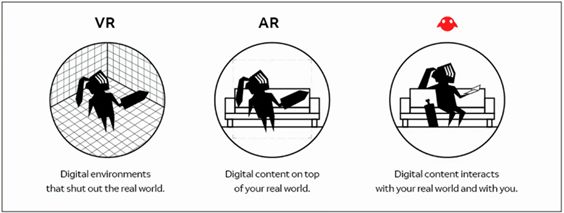
不过得到了一张饼也要失去一张饼,这就是大饼守恒定律。
Magic Leap交互实验室的负责人Schwab表示,Magic Leap One的视场是有限的,并没有此前宣称的那么神奇。不过他也没有具体说明有限到多少,而是告诉开发者再知道Magic Leap One有限的视场后如何改变他们的开发思路。
Schwab提出了四个观点他认为开发者应该注意的,分别为“Less is More”、“Respect The Real World”、“Getting your Attention”、“Reality Considerations”。

“少即是多”用在这里实在是太取巧了,Schwab提出的这三点其实都很中肯。在AR体验当中,应当以让用户体验到虚拟与现实之间的融合,将AR作为现实世界的延伸,而在视场中过多的填充就会造成反效果。
不过考虑到这是对于MLO有限的视场而做出的策略改变,只能拍着手说有道理了。
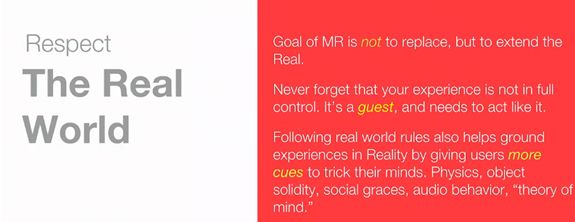
这条也是对于“少即是多”的阐述,Schwab做了一个比喻,AR就好比现实世界中的客人,主角任然是现实世界,AR不能喧宾夺主,可以使用更多的线索引导用户。
不过对于有限的视场也可以用其他方法补救。通过眼动追踪我们可以知道用户正在看什么,当用户视线不在目标上的时候,我们可以通过空间化音频或者是外围视场中的运动来引导用户的视线。

在设计的同时,也要考虑到用户的安全。比如你正在走一个下坡路,而AR信息在上方,这就很容易造成事故。而且在沉浸感强烈的情境下,人们的听觉会下降,甚至什么都听不到,这将会造成十分严重的结果,这也是Schwab提醒开发者需要十分注意的事情。

在用户数据方面,MLO会从五方面进行收集。分别是头部姿势、双手、双眼、语音还有地理/临时信息。
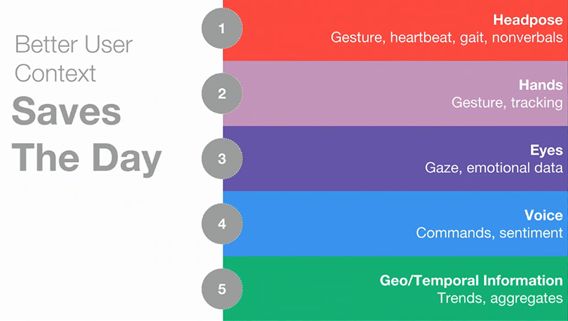
头部姿势能够搜集不仅能分析摇头和点头和其他的头部运动,还能检测心跳、步姿和你走路的速度等。
对于眼睛的眼动追踪和语音命令这两个功能,除了本职工作以外,还能够通过眼睛的形态和声调的高低大小来判断用户的情绪。
通过眼睛收集的信息主要来自于眼睛停止转动的时刻,我们的眼睛一直在不断地转动(这期间的速度很快,几乎采集不到什么信息),如果它没动说明我们正在经历某些事情。这时就会采用到心理学的知识,比如眼睛向下看说明在思考,向左上方看时在思考。
最令人意外的还是第一次被透露的地理信息和临时信息的收集,通过收集用户之间交互的地理信息与临时信息来分析趋势,来为用户判断更好的选择。不过如何运行这项功能,并未透露。
至于手部姿势,MLO可以识别八种手势,如下图所示。
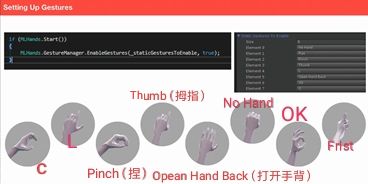
在识别手势时,将会先由头部姿势判断,然后开启深度摄像头扫描近场来识别手势,能够同时识别双手的手势。在手势识别的时候,会有八个点跟踪,这将会把八个特定的手势和平常的手势区分开来。
说到这里就要谈一下MLO的交互模式了。MLO对于指令的输入是对综合头部、眼动追踪、手势信息进行的综合,将头部姿势与视线还有手势相结合。
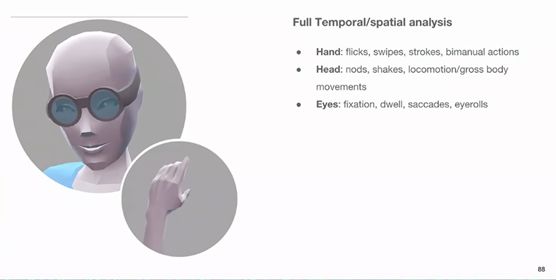
比如眼前有三个方块,通过头部姿势和眼动追踪能够知道你正在看的是哪一个方块,然后再识别手势例如Thumb就能够选中那个方块了,也就是说能够预判用户的选择。

通过之前所讲对于用户心理的分析,MLO可以判断用户是有目的的选择,而不是随便瞎选,从而达到准确的预判。
这种操作设置其实也比较符合人本身的运动规律,在同一时间是多个器官同时运作的。
而与之配套的,Magic Leap开发了一套多式交互模型——TAMDI。

代表着五个步骤,分别为Targeting(目标)、Activation(获取)、Manipulation(操纵)、Deactivation(失活)、Integration(整合),五个步骤构成一个循环过程,对头、眼、手三个部位的信息进行整合判断。
说了半天终于要讲到MLO的演示视频了,不过在此之前我们先来看看公布的Magic Leap的工具包——Magic Kit。受限于信息与篇幅(最主要还是丸子酱不懂),就不介绍具体的使用教程,让我们一起来看看这个工具包里面都有些什么。
首先是Environment Toolkit,能够说明现实空间中物体的位置,识别遮掩物背后被藏起来的识别点,还有房间的角落。
使得虚拟内容能够更符合现实世界规则,增强沉浸感。源代码则会放在在GitHub上,供开发者下载。


空间中那些点是Magic Leap提出的环境映射概念——BlockMesh,这是Lumin SDK for Unity中MLSpatialMapper预制件的可用网络类型。

网格在内部重建,物体都将会表现为互联的三角形网格。但这些网格之间并没有相互连接,是为了在转换目标的时候能够快速更新网格。同时带来的好处是MLO的识别更加紧密、贴近边界,你可以看到虚拟对象是结结实实的踩在地上的,这会带来更好的沉浸感。

在挥手时,虚拟人也能够同样向我们挥手,MLO的姿势API有以下这些。
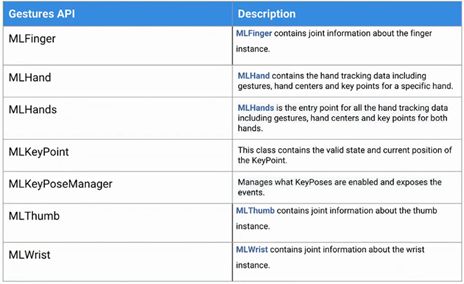
SDK API则有一下几种。

开发包包括的工具以下。

这些就是大致的内容了,除此之外他们还透露控制器将会继续保留,在手势与控制器之间,控制器能够带来更好的触感和反馈。在一项Magic Leap的专利里面我们可以找到控制器的样子。


这次大会上给我们带来了诸多MLO的信息,虽说戳穿了饼并没有画的那么大,但是更加的真实了,最终效果如何还是让我们一起期待吧。
