技术文章:技术文章使用Python+OpenCV+yolov5实现行人目标检测
磐创AI介绍目标检测支持许多视觉任务,如实例分割、姿态估计、跟踪和动作识别,这些计算机视觉任务在监控、自动驾驶和视觉答疑等领域有着广泛的应用。随着这种广泛的实际应用,目标检测自然成为一个活跃的研究领域。我们在Fynd的研究团队一直在训练一个行人检测模型来支持我们的目标跟踪模型。在本文中,我们将介绍如何选择一个模型架构,创建一个数据集,并为我们的特定用例进行行人检测模型的训练。什么是目标检测目标检测是一种计算机视觉技术,它允许我们识别和定位图像或视频中的物体。目标检测可以理解为两部分,目标定位和目标分类。定位可以理解为预测对象在图像中的确切位置(边界框),而分类则是定义它属于哪个类(人/车/狗等)。
目标检测方法解决目标检测的方法有很多种,可以分为三类。级联检测器:该模型有两种网络类型,一种是RPN网络,另一种是检测网络。一些典型的例子是RCNN系列。带锚框的单级检测器:这类的检测器没有单独的RPN网络,而是依赖于预定义的锚框。YOLO系列就是这种检测器。无锚框的单级检测器:这是一种解决目标检测问题的新方法,这种网络是端到端可微的,不依赖于感兴趣区域(ROI),塑造了新研究的思路。要了解更多,可以阅读CornerNet或CenterNet论文。什么是COCO数据集为了比较这些模型,广泛使用了一个称为COCO(commonobjectsincontext)的公共数据集,这是一个具有挑战性的数据集,有80个类和150多万个对象实例,因此该数据集是初始模型选择的一个非常好的基准。如何评估性能评估性能我们需要评价目标检测任务的各种指标,包括:PASCAL VOC挑战(Everingham等人。2010年)COCO目标检测挑战(Lin等人。2014年)开放图像挑战赛(Kuznetsova 2018)。要理解这些指标,你需要先去理解一些基本概念,如精确度、召回率和IOU。以下是公式的简要定义。平均精度
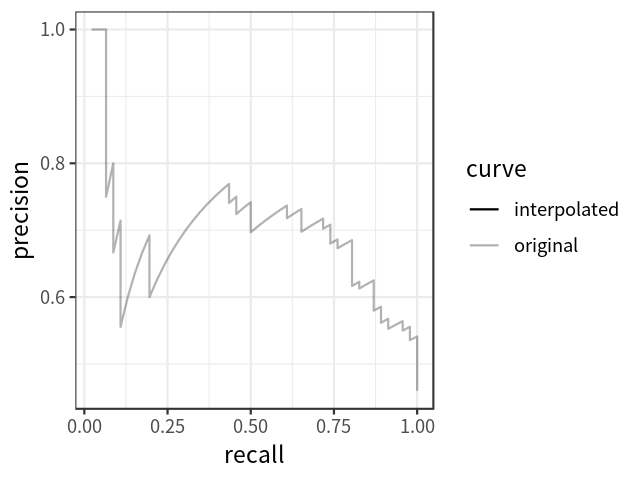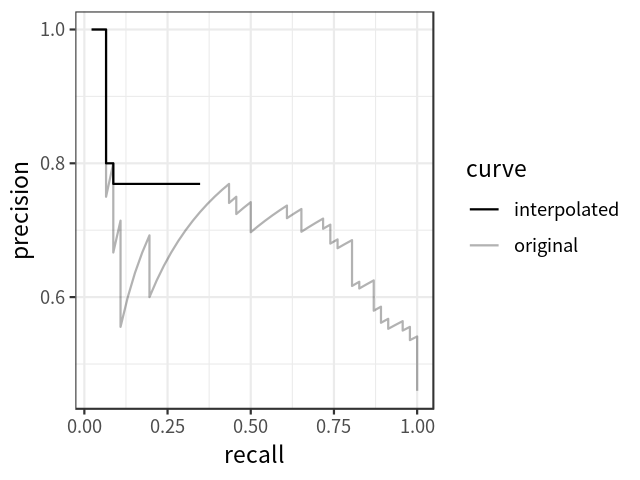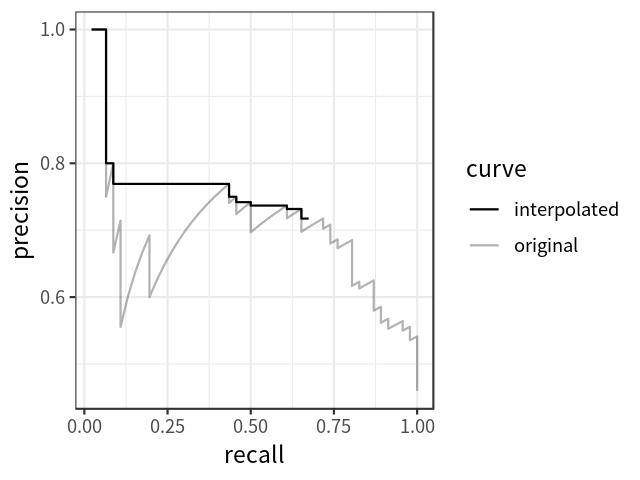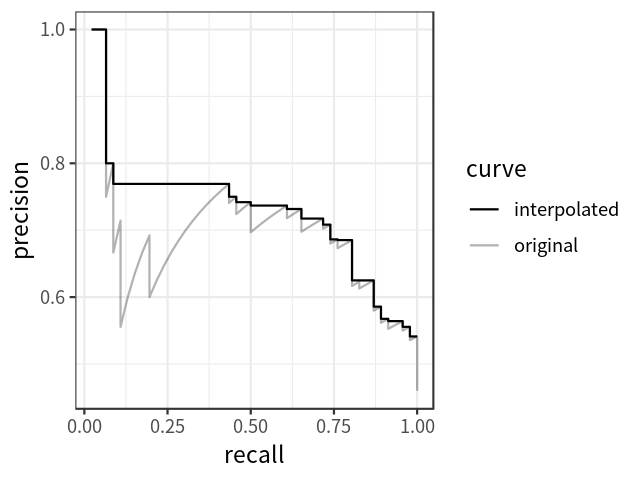
AP可定义为插值精度召回曲线下的面积,可使用以下公式计算:
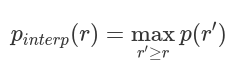
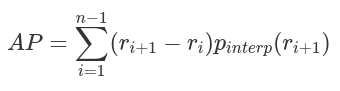
mAPAP的计算只涉及一个类,然而,在目标检测中,通常存在K>1类。平均精度(Mean average precision,mAP)定义为所有K类中AP的平均值:
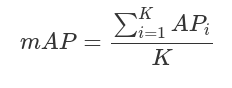
TIDETIDE是一个易于使用的通用工具箱,用于计算和评估对象检测和实例分割对整体性能的影响。TIDE有助于更详细地了解模型错误,仅使用mAP值是不可能找出哪个错误段导致的。TIDE可以绘制简单的图表,使分析变得轻松。https://youtu.be/McYFYU3PXcU实际问题陈述我们的任务是检测零售店闭路电视视频源中的人体边界框,这是跟踪模型的一个基础模型,且其检测所产生的所有误差都会传递到跟踪模型中。以下是在这类视频中检测的一些主要挑战。挑战视角:CCTV是顶装式的,与普通照片的前视图不同,它有一个角度人群:商店/商店有时会有非常拥挤的场景背景杂乱:零售店有更多的分散注意力或杂乱的东西(对于我们的模特来说),比如衣服、架子、人体模型等等,这些都会导致误报。照明条件:店内照明条件与室外摄影不同图像质量:来自CCTVs的视频帧有时会非常差,并且可能会出现运动模糊测试集创建我们创建了一个验证集,其中包含来自零售闭路电视视频的视频帧。我们使用行人边界框对框架进行注释,并使用mAP@0.50 iou阈值在整个训练迭代中测试模型。第一个人体检测模型我们的第一个模型是一个COCO预训练的模型,它将“person”作为其中的一个类。我们在每种方法中列出了2个模型,并基于COCO-mAP-val和推理时间对它们进行了评估。
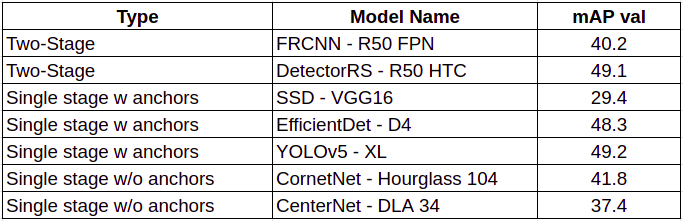
我们选择YOLOv5是因为它的单级特性(快速推理)和在COCO mAP val上的良好性能,它还有YOLOv5m和YOLOv5s等更快的版本。YOLOv5YOLO系列属于单阶段目标探测器,与RCNN不同,它没有单独的区域建议网络(RPN),并且依赖于不同尺度的锚框。架构可分为三个部分:骨架、颈部和头部。利用CSP(Cross-Stage Partial Networks)作为主干,从输入图像中提取特征。PANet被用作收集特征金字塔的主干,头部是最终的检测层,它使用特征上的锚框来检测对象。YOLO架构使用的激活函数是Google Brains在2017年提出的Swish的变体,它看起来与ReLU非常相同,但与ReLU不同,它在x=0附近是平滑的。
损失函数是具有Logits损失的二元交叉熵性能0.48 mAP@0.50 IOU(在我们的测试集上)分析这个现成的模型不能很好地执行,因为模型是在COCO数据集上训练的,而COCO数据集包含一些不必要的类,包含人体实例的图像数量较少,人群密度也较小。此外,包含人体实例的图像分布与闭路电视视频帧中的图像分布有很大不同。结论我们需要更多的数据来训练包含更多拥挤场景和摄像机视角介于45?-60?(类似于CCTV)的模型。收集公共数据我们的下一步是收集包含行人/行人边界框的公共可用数据集。有很多数据集可用于人体检测,但我们需要一些关于数据集的附加信息,如视角、图像质量、人体密度和背景等,以获取数据集的分布信息。我们可以看到,满足我们确切需求的数据集并不多,但我们仍然可以使用这些数据集,因为人体边界框的基本要求已经得到满足。在下载了所有的数据集之后,我们把它转换成一个通用的COCO格式进行检测。第二个人体检测模型我们用收集到的所有公共数据集训练模型。
1 2 下一页>
