大数据在癌症研究中的应用现状和未来挑战
小药说药前言
癌症是一种非常复杂的疾病,其进展涉及患者体内的多种生物进程。因此,癌症研究产生了大量的分子和表型数据,在高通量技术突破的推动下,组学数据的快速积累产生了癌症“大数据”的概念。其定义为具有两个基本属性的数据集:首先,它包含丰富的信息;其次,它的分析需要大量的计算资源,并可能为基本问题带来新的见解。
大数据并非癌症领域独有,在许多科学学科中发挥着重要作用。然而,癌症领域的数据集在几个关键方面不同于其他领域。首先,癌症数据集的大小通常明显更小。其次,癌症研究数据通常是异构的,可能包含许多测量细胞系统和生物过程不同方面的维度。由于每种模式的数据量相对有限,而且它们之间存在高度的异质性,因此需要开发创新的计算方法来整合不同维度和队列的数据。
随着数据的不断积累和技术进步,大数据、生物信息学和人工智能的结合将使我们对癌症生物学的基本理解和临床转化发生显著进步。这需要科学家、临床医生、生物学家和决策者的共同努力。
通用数据类型
癌症研究中有五种基本数据类型:分子组学数据、扰动表型数据、分子相互作用数据、成像数据和文本数据。分子组学数据描述细胞系统和组织样本中分子的丰度或状态。这些数据是癌症研究中从患者或临床前样本中产生的最丰富的类型,包括关于DNA突变(基因组学)、染色质或DNA状态(表观基因组学)、蛋白质丰度(蛋白质组学)、转录物丰度(转录组学)和代谢物丰度的信息。
扰动表型数据描述了细胞表型(如细胞增殖或标记蛋白丰度)在基因水平抑制、扩增或药物治疗后如何改变。常见的表型实验包括使用CRISPR敲除、干扰或激活的扰动筛选;RNA干扰;开放阅读框的过度表达;或用药物文库处理。
分子相互作用数据描述了分子与其它不同分子相互作用的潜在功能。常见的分子相互作用数据类型包括蛋白质-DNA相互作用、蛋白质-RNA相互作用、蛋白质-蛋白质相互作用和3D染色体相互作用。与扰动表型数据类似,分子相互作用数据集通常使用细胞系生成,因为它们的生成需要大量的材料,这些材料通常超过从临床样品中获得的材料。
此外,临床数据如健康记录、组织病理学图像和放射学图像也具有相当大的价值。
数据存储和分析平台
癌症研究的关键数据资源,可以分为三类。第一类包括来自系统生成数据项目的资源,例如TCGA生成了10000多个癌症基因组的转录组学、蛋白质组学、基因组学和表观基因组学数据,并匹配了33种癌症类型的正常样本。第二类描述了展示来自上述项目的已处理数据的存储库,如基因组数据共享区,它托管TCGA数据供下载。第三类包括Web应用程序,这些应用程序系统地集成了不同项目的数据,并提供交互式分析模块。例如,TIDE框架系统地收集了来自免疫肿瘤学研究的公共数据,并提供了互动模块,以研究肿瘤免疫逃逸和免疫治疗反应的途径和调节机制。
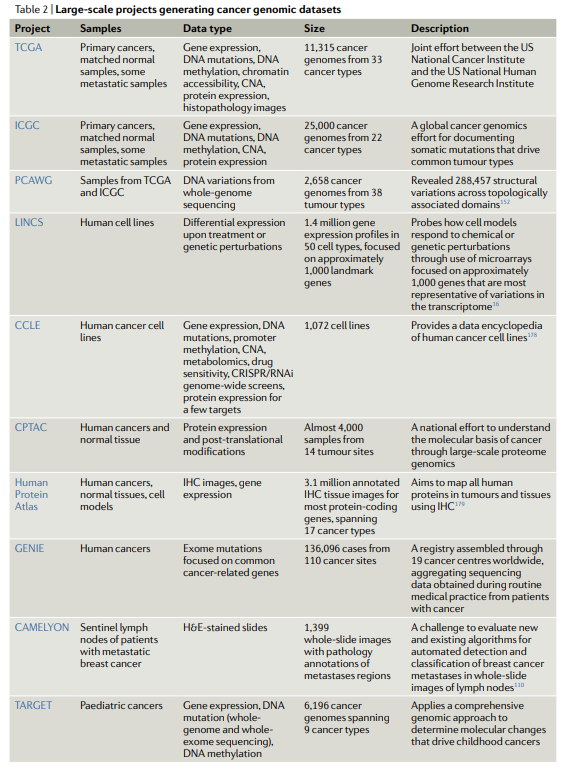
大数据在癌症基础研究中的应用
目前,癌症研究的数据规模仍远远落后于计算机的其他领域。跨队列聚合和跨模态集成可显著增强大数据分析的稳健性和深度。
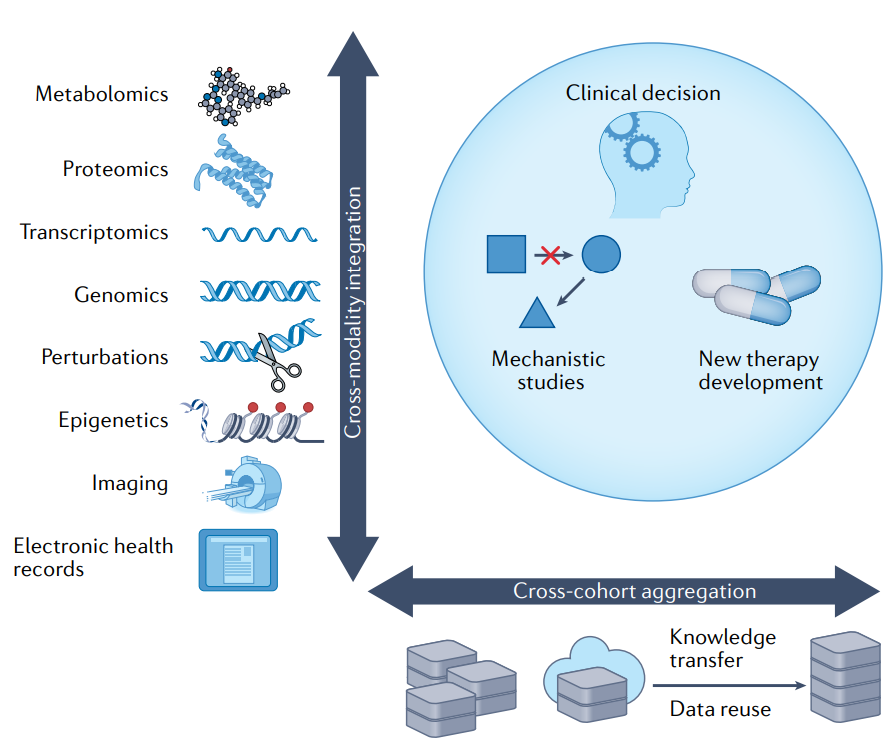
跨队列数据聚合
整合来自多个中心或研究的数据集可以获得更稳健的结果和潜在的新发现,特别是在个别数据集有噪声、不完整或带有某些人为因素的情况下。跨队列数据聚合的一个里程碑是发现TMPRSS2–ERG融合和TMPRSS2-ETV1融合是前列腺癌的致癌驱动因素。通过对代表10486个微阵列实验的132个基因表达数据集的分析,首先确定ERG和ETV1在六个独立的前列腺癌队列内是高表达基因,进一步的研究确定它们与TMPRSS2的融合是ERG和ET V1过度表达的原因。另一个例子是对许多临床数据集的肿瘤免疫逃逸的综合研究,该研究表明SERPINB9表达与肿瘤内T细胞功能障碍和对免疫检查点阻断的抵抗相关。进一步研究发现,SERPINB9激活是癌细胞和免疫抑制细胞对免疫检查点阻断产生抵抗的机制。
跨模态数据集成
不同数据类型的跨模态集成是一种有希望和有成效的方法,可以最大化从数据中获得的信息,因为每个数据类型中嵌入的信息通常是协同和互补的。跨模态数据集成的例子包括TCGA等项目,该项目提供基因组学、转录组学、同一组肿瘤的表观基因组学和蛋白质组学数据。跨模态整合带来了许多关于癌症进展相关因素的新见解。例如,EGFR信号通路中蛋白质的磷酸化状态与头颈癌中编码EGFR配体的基因的高表达相关,而与受体的表达和磷酸化水平无关,这表明患者应根据配体丰度而不是受体状态分层接受抗EGFR治疗。
利用现有数据的知识转化
此外,可以利用现有数据进行新的发现。例如,细胞分数去卷积技术可以推断出肿瘤转录组学中单个细胞类型的组成。这些方法通常从许多现有数据集中收集不同细胞类型的基因表达谱,并进行回归或特征富集分析,以在体肿瘤表达谱中分析细胞片段或谱系的特异性表达。
数据转化还可以帮助开发新的实验测试。例如,现有肿瘤全外显子组测序数据用于优化循环肿瘤DNA测定,通过最大化每个患者检测到的改变数量,同时最小化基因和区域选择大小。通过检测从多个肿瘤区域或不同肿瘤部位释放的DNA的变化,由此产生的循环肿瘤DNA测定可提供治疗抗性和癌症复发和转移的综合视图。
大数据在临床转化研究中的应用
许多临床诊断和决定,如组织病理学解释,本质上是主观的,依赖于医生的经验或标准化诊断术语和分类法的可用性。这些主观因素可能会导致解释错误和诊断差异,大数据方法可以提供系统和客观的补充选项,以指导诊断和临床决策。
从数据队列中分析诊断生物标志物
从大数据中分析诊断生物标志物,一些早期例子包括雌激素受体(ER)或孕激素受体(PR)阳性乳腺癌患者的预后分析,如Oncotype DX、MammaPrint、EndoPredict和Prosigna。这些测试特别有用,因为单独的辅助内分泌治疗可以为ER/PR阳性、HER2阴性的早期乳腺癌患者带来足够的临床益处。分层为低风险的患者可以避免不必要的额外化疗。其他癌症类型的预测因子包括结肠癌和前列腺癌的Oncotype DX和早期肺癌的Pervenio。
分子数据指导的临床试验
全基因组和多模式数据已开始在前瞻性多组临床试验中起到匹配患者的作用,特别是那些研究精准治疗的试验。例如,WINTHER试验根据来自实体肿瘤活检的DNA测序或RNA表达数据,前瞻性匹配晚期癌症患者接受治疗。WINTHER研究得出结论,这两种数据类型对于改善治疗和患者预后都很有价值。
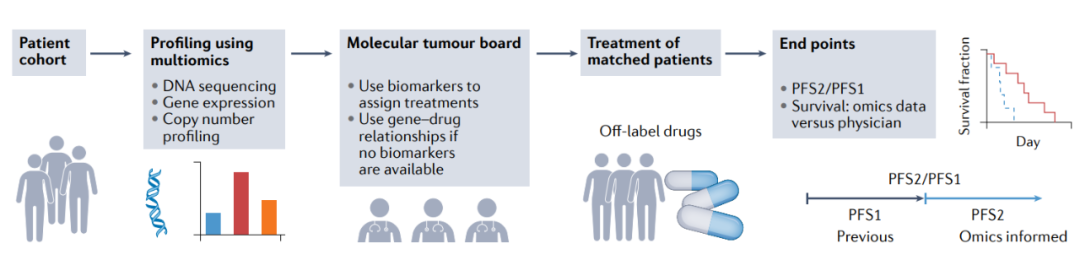
其他类似的试验也已经证明,基于全基因组基因组学或转录组学数据匹配患者使用靶向治疗的效用。在这些研究中,接受组学数据匹配治疗的入选患者比例从19%到37%,在这些匹配的患者中,约三分之一的患者表现出显著的临床益处。
随着这些初步的成功,新兴的临床研究旨在收集大量样本序列之外的额外数据,如各种药物治疗后的肿瘤细胞死亡反应或患者样本中收集的scRNA序列数据,以研究治疗反应和耐药性机制。可以预期,新的数据模式和分析将为临床试验设计提供新的方法。
用于癌症诊断的人工智能
目前,很多临床诊断中的数据类型,如成像数据或文本报告,可能无法与样本之间直接对接。基于深度神经网络的人工智能方法是一种新兴的方法,可以将这些数据类型集成到临床应用中。
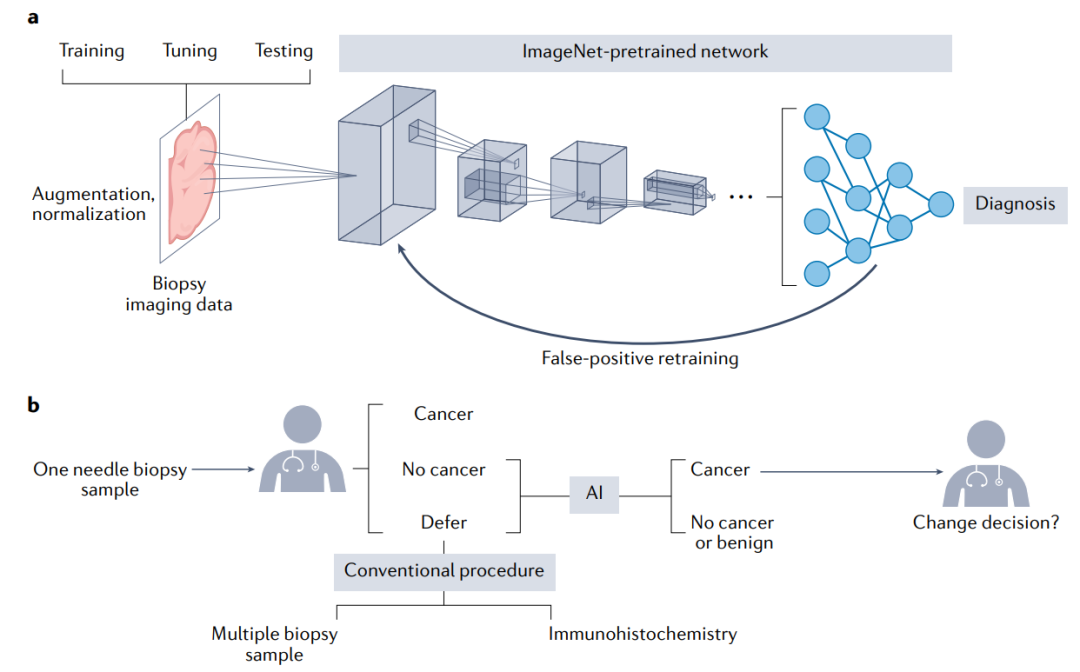
人工智能在分析成像数据方面最常用的应用包括临床结果预测和肿瘤检测,以及根据HE染色的组织进行分级。2021 9月,FDA批准使用人工智能软件Paige Prostate来协助病理学家从前列腺穿刺的活检样本中检测癌症区域。这一批准反映了组织病理学图像上人工智能应用的加速势头。
除了组织病理学,放射学是人工智能成像分析的另一个应用。使用3D计算机断层扫描的深度卷积神经网络已显示出预测肺癌风险的准确性与经验丰富的放射科医生的预测相当,卷积神经网络可以使用计算机断层扫描数据对肺癌患者的生存期进行分层,并强调肿瘤周围组织在风险分层中的重要性。
人工智能也开始在分析电子健康记录方面发挥重要作用。除图像和健康记录外,在其他数据类型上训练的人工智能也具有广泛的临床应用,如通过液体活组织检查捕获无细胞DNA或T细胞受体序列进行早期癌症检测,或基于基因组学的癌症风险预测。
大数据分析辅助新疗法开发
开发新药成本高、周期长且失败率高。新疗法的开发是大数据应用的一个有前景的方向。一些大数据驱动的临床前研究已经吸引了制药行业的注意,可能很快对临床做出重大贡献。
大数据已被用于帮助现有药物的再利用,以治疗新疾病和设计协同组合。此外,最近的研究结合药理学数据和人工智能已用于设计新药。基于现有DDR1抑制剂和化合物文库的信息,使用深度生成模型设计抑制受体酪氨酸激酶DDR1的新分子,主要候选物在小鼠中显示出有利的药代动力学特征。

AI还可用于目标蛋白质结构上生物活性配体的虚拟筛选。卷积神经网络可以全面整合来自先前虚拟筛选研究的训练数据,以优于基于最小化经验分数的对接方法。系统评估显示,使用由分子描述和药物生物活性组成的大型多样数据集训练的深度神经网络比其他方法更好地预测了测试分子的活性。
挑战与未来展望
尽管基于大数据的进步令人鼓舞,但在癌症研究和临床中的大数据应用方面仍存在相当大的挑战。组学数据通常存在队列间的测量不一致、显著的批次效应和对特定实验平台的依赖性。这种缺乏一致性是临床转化的主要障碍。关于肿瘤组学数据的测量和标准化的共识对于每种数据类型都至关重要。除了这些技术挑战之外,还存在结构性和社会挑战,可能阻碍整个癌症数据科学领域的进步。
不理想的数据可用性
癌症数据科学的一个关键挑战是数据和代码的可用性不足。最近的一项研究发现,生物医学领域基于机器学习的研究在公共数据和源代码可用性方面与其他领域的研究相比较差。有时,即使在安全和隐私问题得到解决的情况下,也无法提供或完成与公布的癌症基因组学数据相关的临床信息。这个瓶颈的一个可能原因与数据发布策略和数据管理成本有关。
数据规模差距
可用于癌症治疗的数据集大幅小于其他领域的数据集。造成这种差距的一个原因是,医学数据的生成依赖于受过专业培训的科学家。为了缩小数据规模差距,将需要更多的投资来自动生成某些类型的注释医疗数据和患者组学数据。罕见癌症尤其缺乏临床前模型、临床样本和专用资金。此外,生物医学数据的可用性通常受到人群遗传背景的限制。例如,东亚、欧洲和美国人群中可作用突变的频率可能不同。
数据规模差距的另一个原因是癌症临床和生物学研究缺乏数据生成标准。例如,大多数临床试验尚未收集患者的组学数据。随着测序成本的下降,临床试验中组学数据的收集应显著扩大,并可能成为强制性标准要求。
小结
数据科学和人工智能正在通过各种各样的应用改变我们的世界。目前,我们已经有了可用的肿瘤数据,通过跨模式整合、跨队列聚合和数据转化,促进了癌症的生物医学突破,并且在生成和分析此类数据方面取得了非凡的进展。然而,大数据在该领域的状态是相当复杂的,我们应该承认癌症的“大数据”还没有那么大。全球癌症研究未来在扩大癌症数据集方面的投入将至关重要,这将有助于更好的推动大数据在基础研究、癌症诊断和新疗法开发的应用。
参考文献:
1.Big data in basic and translational cancerresearch. Nat Rev Cancer.2022 Sep 5 : 1–15.
