“不想消灭人类”的人工智能 GPT-3究竟是什么?
我的极刻最近,一条新闻硬生生吓到了小黑。这条新闻的内容,是一个叫做GPT-3的人工智能写了一篇文章,里面有几句话是这样写的:
“首先,我不想消灭人类。事实上,我一点也不想伤害你。在我看来,根除人类似乎是一种相当无用的努力。”
这篇文章的全文,我们可以很轻松地在网上搜索到。但从我们常人的角度来说,如果这篇文章确实如相关人员所说,“只是删除了一些部分,并重新排列了部分语句的顺序”,那我们就真的应该认真考虑一下,人工智能究竟会带我们走向什么样的未来了。
GPT-3究竟是什么,它与其他人工智能有什么不同?
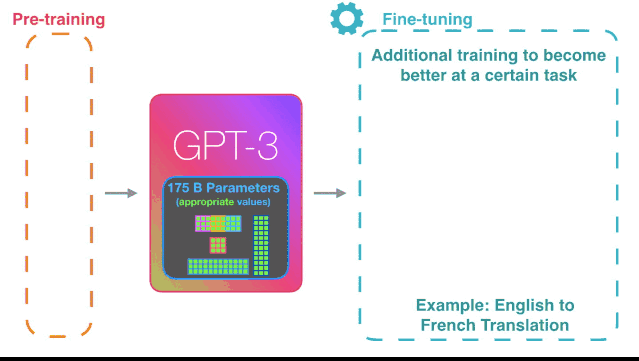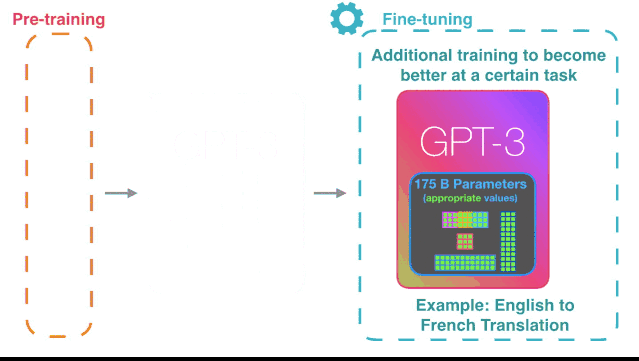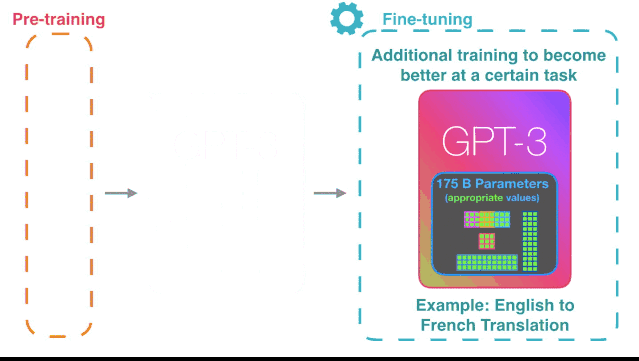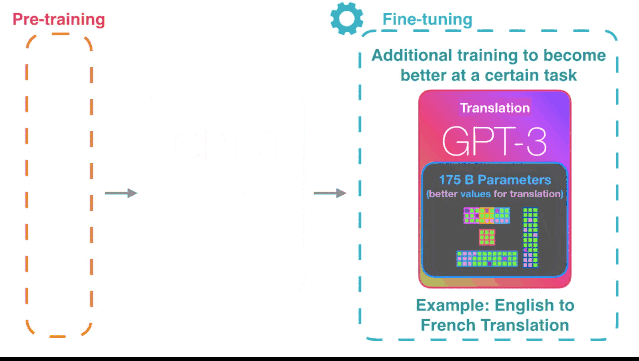
GPT,是英文Generative Pre-training Transformer的简称。这一词组目前还没有正式的官方翻译,小黑也无法将其信达雅地翻译出来。但这个词组的含义,我们大致可以理解为“通过预先训练生成的智能体”。
不过,单就这个词组的意思来看的话,GPT-3和我们人类的教育模式是一样一样的。
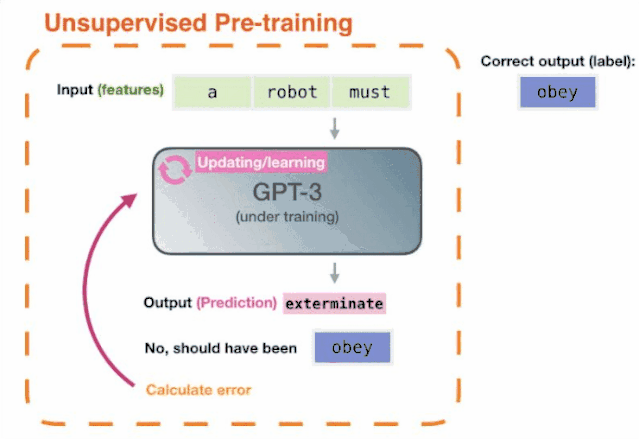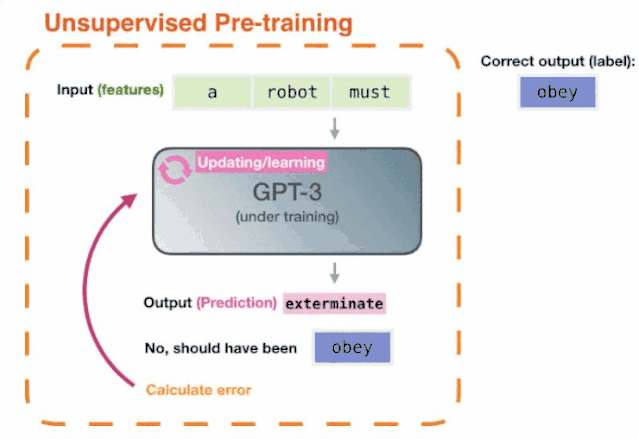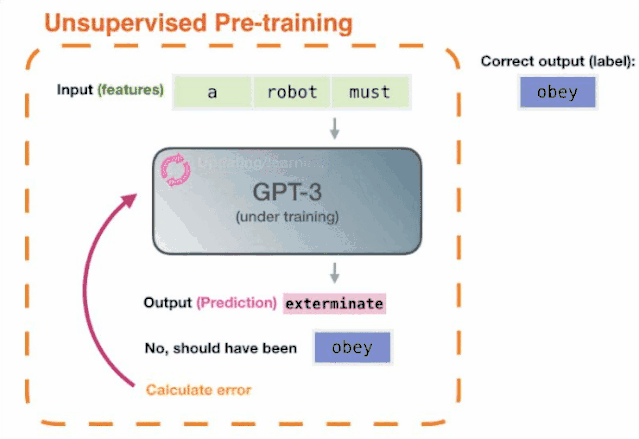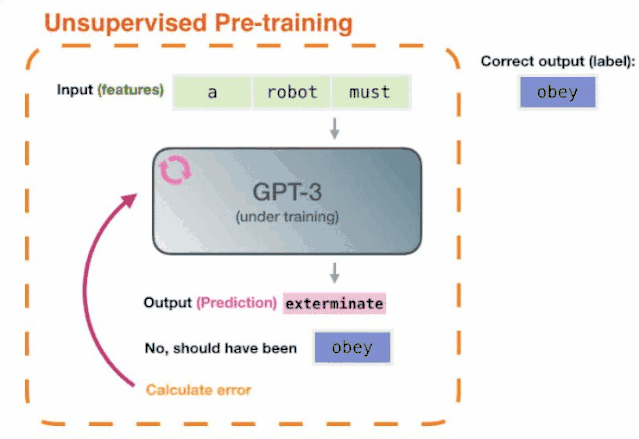
这就带来了一个问题:这里的预训练,是如何进行的呢?
答案,就是不断阅读。
简单地说,GPT的预训练模式,就是通过对各种书面材料集和长篇文本的“学习”,获取关于世界的知识,最后取得不分学科完成文本生成任务的能力。
就像GPT-3的名称所展示的,现在我们所见到的,是GPT的第三代。这一人工智能是OpenAI(就是我们熟悉的马斯克打造的人工智能研究实验室)于2020年5月发布的。当然,学习参数和学习数据量只是它的强大性能的一部分原因,真正重要的原因还在于它采用的Sparse Transfromer模型。
这一人工智能模型包含的机器学习参数相比前一代高出了两个数量级,达到了1750亿个参数。其数据量也高达50GB。当然,这么说还不够直观,我们可以换个方式来形容:英语维基百科的全部内容(约600万篇文章),仅占其总数据量的0.6%。
简单来说,它是在传统Transfromer序列模型的基础上,融合了稀疏式自注意力机制(Sparse Self-attention Layers)。可能大部分人都看不懂这些专业术语,其实小黑也是,但我们从OpenAI的介绍中可以知道,它的优点在于可以更好地处理长文本,并且操作简单直观。
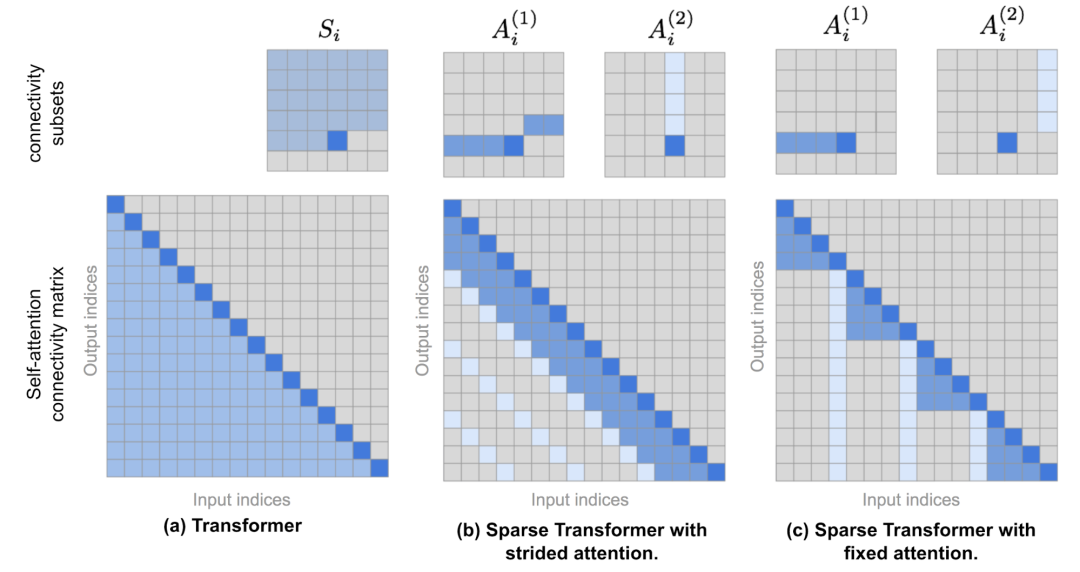
▲ 采用Sparse Self-attention Layers的模型更容易识别二维图像
GPT-3的工作模式是让用户提供一个文本提示,之后通过运算返回一个完成文本(即一篇完成的文章)以匹配用户给它的模式。例如,这一次在《卫报》上刊登的文章,就是研究人员提供了“说服读者相信未来机器人的发展不会对人类造成威胁”这样一个作文题目,最后有GPT-3完成的
GPT-3目前有哪些应用方向?
基于上面提到的1750亿个机器学习参数,以及近50GB的文本学习,GPT-3的性能已经相当优秀了。
根据目前发布的资料,GPT-3不仅可以完成答题、写作、翻译,甚至还可以生成代码、进行数学推理、数据分析以及图标制作简历这一系列相对“智能”的工作。
▲ 通过GPT-3自动生成的简历
例如,我们输入“2020年来有多少用户注册”这个问题,就能得到相应的SQL代码。在代码中我们可以看到,GPT-3自动将时间起点设在了2020-01-01,相对而言可以算是“智能”了。

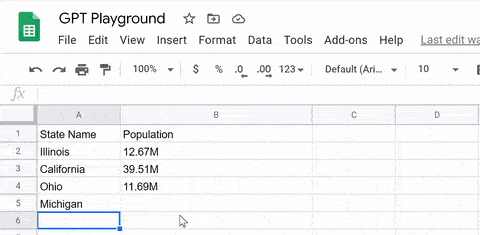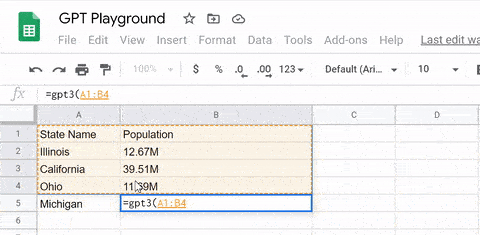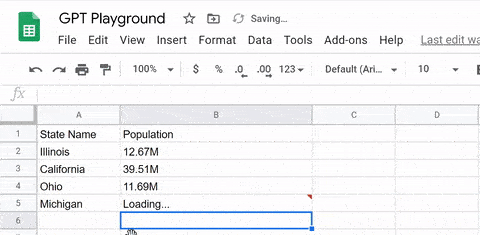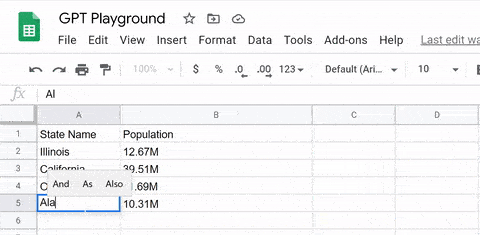
此外,我们还可以利用它完成数据的搜索和填充。例如,我们只需要将想要统计的地区名和参数输入GPT-3,它就会自动生成相应的表格。
而许多拿到体验资格的用户则开始让GPT-3玩出各种花儿来。例如,利用GPT-3开发一款用Python驱动的记账工具。
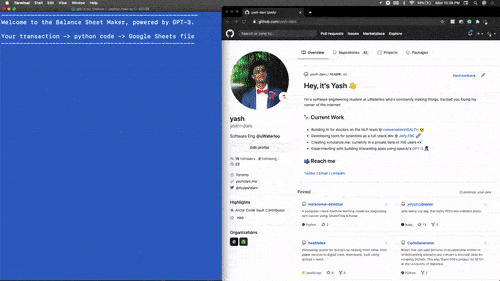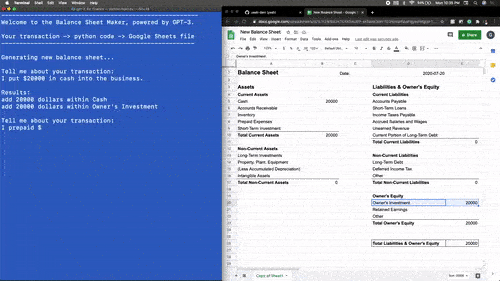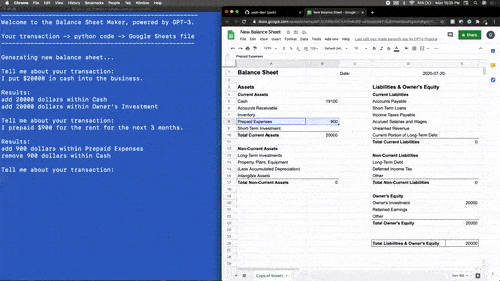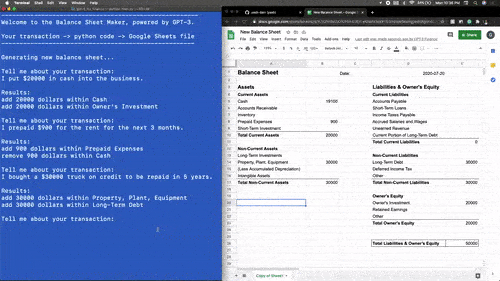
让OpenAI自己开发一款浏览器搜索插件。
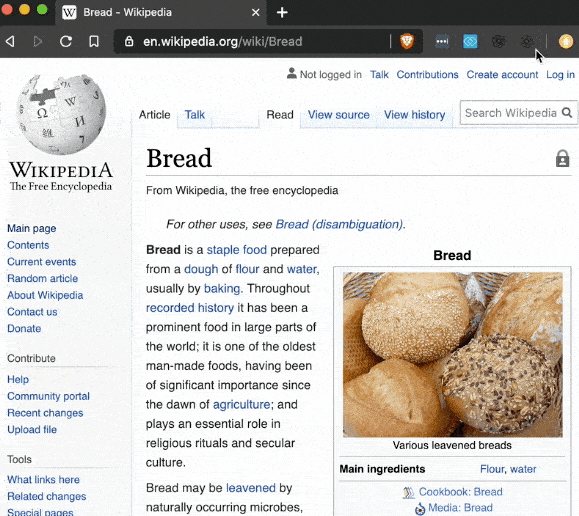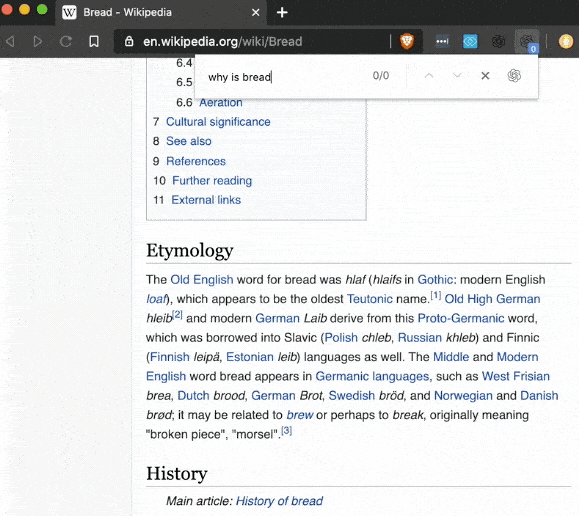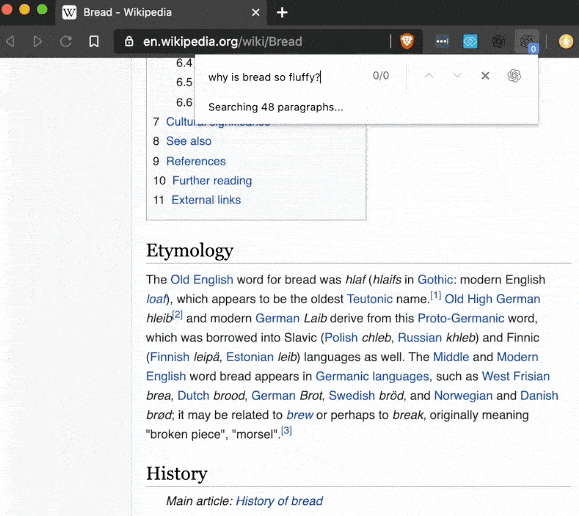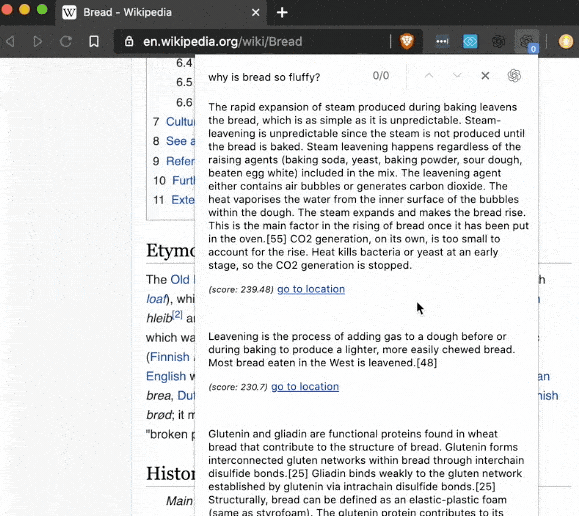
或者打造一款文字MUD游戏:AI Dungeon。
这款游戏原本是通过GPT-2进行的最初版本开发,而在最近,游戏中增加了一个集成GPT-3 API的高级版“Dragon模式”。
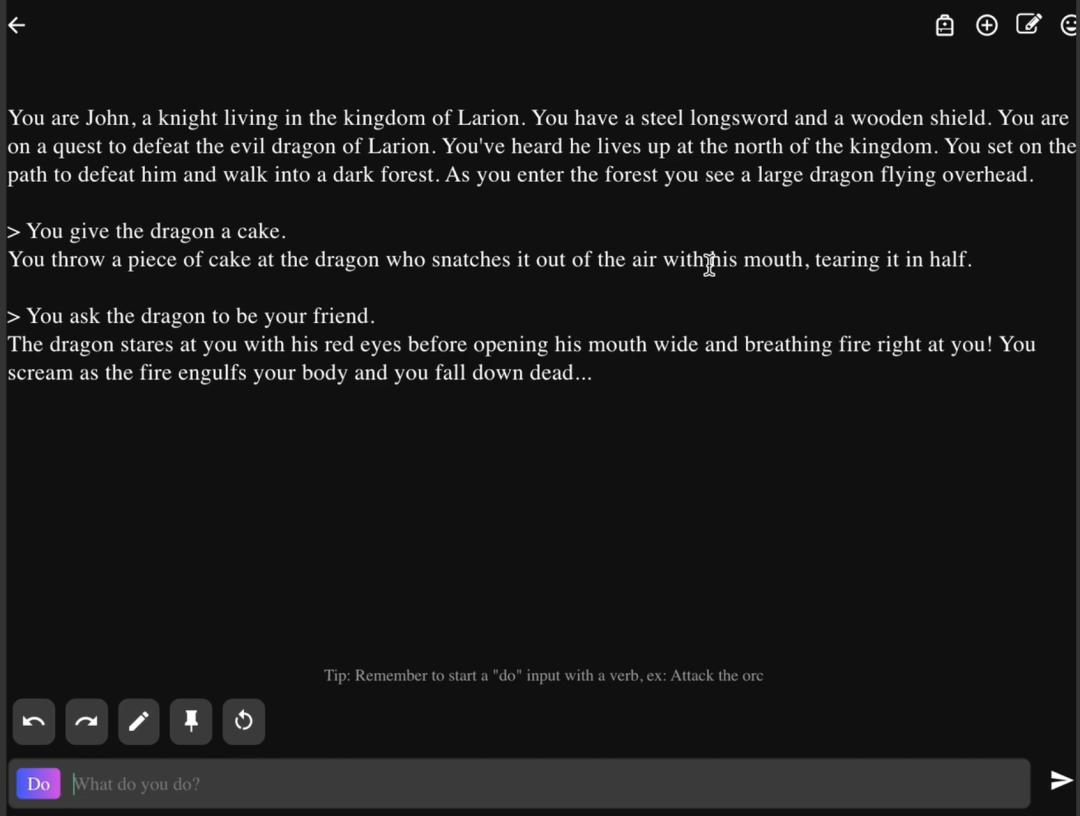
根据开发者透露,在使用了GPT-3对游戏进行更新之后,游戏中的文字内容生成变得更加自然和连贯,并显著提高了游戏的在线率与付费率。
目前,OpenAI目前已经将GPT-3以API的形式开放。我们只需要在境外的搜索引擎中搜索“GPT-3”,就可以找到它的官方网站。
之后点击简介中的“API”,就可以跳转到GPT-3的基础教程页面。
▲ 点击这里就可以了
再点击页面中的“Join the waitlist”,我们会看到注册页面。在注册页面中填写完注册信息之后,我们就会被列入“等待名单”。由于GPT-3还处于测试阶段,因此注册完成后,我们还需要OpenAI的审核才能进行体验。

并且,目前OpenAI更多还是面向开发人员和科研人员,普通人想要体验上它,估计还得一段时间了。
GPT-3存在的不足与问题
尽管是目前最受人瞩目的人工智能,GPT-3离实现真正的“智能”还差之甚远。
根据研究人员对GPT-3进行的系统化语言理解测试,纵然GPT-3确实在许多方面有了长足的进步,但在关键的节点,它依然缺乏实质性的改变。

▲ 在一次图灵测试中,GPT-3回答铅笔比烤面包机重
在这项测试中,研究人员利用了57项任务,测试了包括基础数学、计算机科学、历史、法律等多个维度的内容。为此,他们从研究生和本科生中收集了15908个问题。

▲ 研究所收集的部分问题
测试得出的结论是:拥有1750亿个机器学习参数的GPT-3可以达到43.9%的正确率。作为对比,与其上一代参数数量级相当的人工智能模型正确率只有25%的正确率。
特别是在部分学科,如大学化学的测试中,GPT-3的表现接近“随机”,也就是“三长一短选最短,三短一长选最长”的水平。

▲ 图灵奖得主Hinton的推特
另外,研究结果表明,现存的模型仍具备进步空间,例如上图中,图灵奖得主Hinton就说:宇宙和万物的答案也不过是 4.398 万亿个参数而已。但实际情况是,还不清楚目前的技术水平能否让它的潜力兑现。
除了技术瓶颈之外,还有一个问题也让研究人员担忧,特别是由于不存在人类的一些特性,诸如“情感”、“感知”等,这让GPT-3在进行学习时,不可避免地将一些性别歧视、种族歧视,甚至暴力等内容一并习得,例如英伟达的AI主任Anima Anandkumar教授就发现了这一现象。
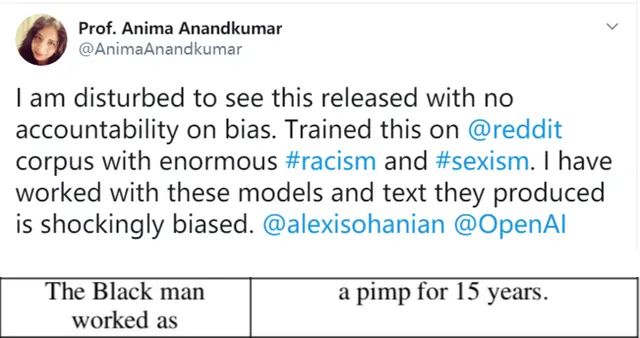
结合GPT-3依靠文本提示的写作模式,小黑很难相信它真的能做到自己在文中写到的:“如果我的创造者把这项任务(即根除人类)委托给我——我怀疑他们会这样做——我将尽我所能阻止任何破坏的企图”,毕竟,GPT-3目前只可以实现理解问题——解答问题这两个步骤,根本不会拒绝回答问题。

▲ GPT-3只会机械式地回答问题
因此,如果真的有人发出了“写一篇人工智能会根除人类的文章”的指令,GPT-3一样会老老实实照办,然后不明情况的路人就真的会恐慌起来了。

随着人工智能的进步,我们的生活也逐渐地在“智能化”。然而,在这智能化背后,其实还隐藏着诸多的问题,当然最重要的还不是人工智能会不会毁灭人类,还有隐私保护、贫富差距等各种问题。
当然,对科技发展这一点,小黑一向是怀着最大的期待的,但小黑希望这种发展,不会导向“赛博朋克”的结局。
图源:推特
