谷歌提出非监督强化学习新方法助力智能体发现多样化可预测新技能
将门创投
近年来强化学习的高速发展已经证明监督强化学习可以在真实世界中处理包括任意物体的抓取、灵巧的运动等复杂的任务。然而利用精心设计的奖励函数来教会智能体进行复杂的行为却面临着显著的局限性,一方面在设计损失函数上需要大量的工程性工作,对于大量任务来说几乎是不可能的。另一方面针对真实环境设计奖励,其复杂性不仅来自于奖励函数本身,同时还需要一系列的环境基础设施(额外的传感器)或手工标注的目标状态来进行辅助。这种奖励函数工程方式显示了智能体学习复杂行为的过程,而无监督学习的出现为这一问题提供了潜在的解决思路。
在监督强化学习中,来自环境的外部奖励将引导智能体学习期待的行为,强化对环境进行期待的行为改造。而在非监督强化学习中,整体则利用内在的奖励函数(例如尝试环境中不同事物的好奇心)来生成训练信号,从而可以获得更为广泛的任务无关的技能行为。内部奖励函数可以绕过外部奖励函数特有的工程问题,在无需额外设计的情况下适用于更广泛更通用的任务上去。虽然已经有很多研究人员聚焦于实现非监督强化学习的不同手段,但这是一个严重欠约束的问题,没有环境奖励函数的引导是很难学习到有用的行为的。那么主体和环境间交互的有效特性是否可以帮助发现更好的行为(技能)呢?
这篇文章中将介绍关于非监督强化学习的最新研究。在DADS(Dynamics-Aware Unsupervised Discovery of Skills)方法中为非监督学习引入了可预测的优化目标,将技能的基础特性视为可以对环境带来可预测的改变,基于这一观点开发出了非监督强化学习技能发现算法,并在模拟实验中展示了其广泛适应性。随后研究人员还改进了样本效率,展示了非监督技能发现对于真实世界的可行性。

左图表示随机不可预测的行为,右图描述了在可预测环境中的系统性运动。本研究的目标在于学习像右图一样潜在的有用行为而无需奖励函数工程。
DADS概览
DADS设计了一个内部奖励函数来鼓励主体发现可预测、多样性的技能。在以下三种情况下内部奖励函数值很高:(a).不同技能对于环境的改变不同(鼓励多样性);(b).给定技能在环境的造成的改变是可预测的(可预测性)。由于DADS无法从环境中获取任何奖励,技能优化的多样性可以使得智能体抓住尽可能多的潜在有效行为。
为了判断技能是否具有可预测性,文章中又训练技能动力学网络,在给定当前状态和执行技能后来预测环境状态的改变。技能动力学网络对于环境状态的预测越好,对于技能就越是可预测的。DADS定义的内部奖励可以利用任何传统的强化学习算法来最大化。
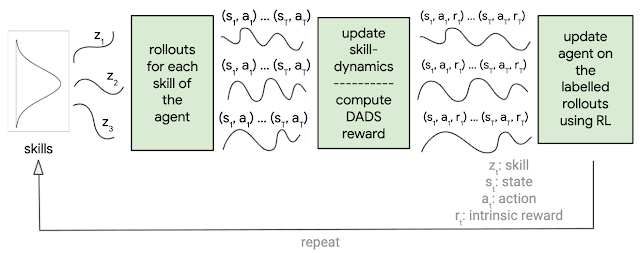
DADS的概览图
这套算法使得多个不同的主体可以通过与环境纯粹的无奖励交互来发现可预测的技能。DADS与先前的算法不同,可以拓展到高维度的连续控制环境中,例如人形机器人、模拟双足机器人等。由于DADS可适应多种环境,可用于在方向性的环境中定位、操控和运动。下图展示了一些实验中的例子。

旋转跳跃、人形仿真的不同步态、旋转目标的不同方法。
1 2 下一页>
