用Python和OpenCV为对象检测任务实现最流行、最高效的数据扩充
磐创AI数据扩充是一种增加数据集多样性的技术,无需收集更多真实数据,但仍有助于提高模型精度并防止模型过拟合。
在本文中,你将学习使用Python和OpenCV为对象检测任务实现最流行、最高效的数据扩充过程。
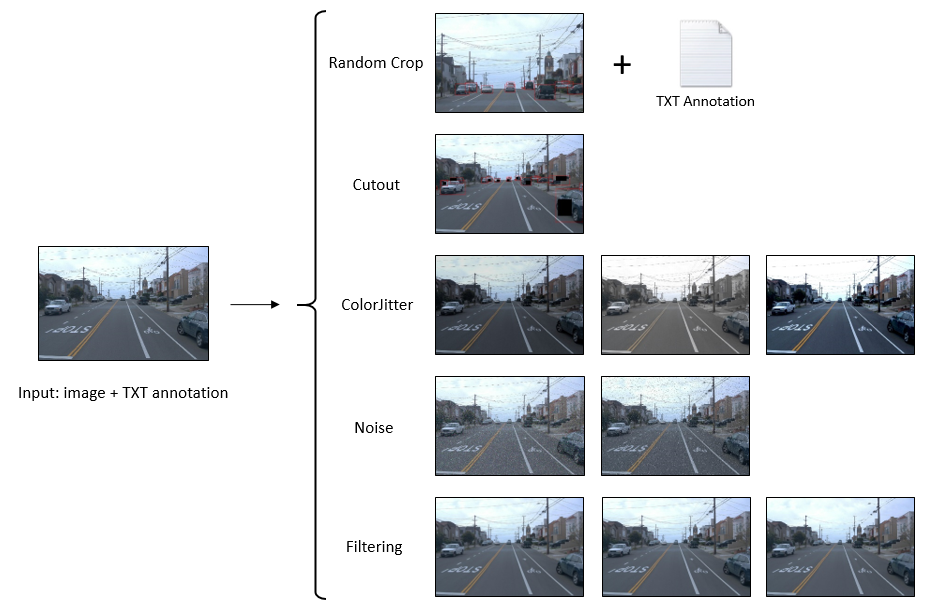
即将引入的一组数据扩充方法包括:
1.随机裁剪
2.Cutout
3.颜色抖动
4.增加噪音
5.过滤
首先,在继续之前,让我们导入几个库并准备一些必要的子例程。
import os
import cv2
import numpy as np
import random
def file_lines_to_list(path):
'''
### 在TXT文件里的行转换为列表 ###
path: 文件路径
'''
with open(path) as f:
content = f.readlines()
content = [(x.strip()).split() for x in content]
return content
def get_file_name(path):
'''
### 获取Filepath的文件名 ###
path: 文件路径
'''
basename = os.path.basename(path)
onlyname = os.path.splitext(basename)[0]
return onlyname
def write_anno_to_txt(boxes, filepath):
'''
### 给TXT文件写注释 ###
boxes: format [[obj x1 y1 x2 y2],...]
filepath: 文件路径
'''
txt_file = open(filepath, "w")
for box in boxes:
print(box[0], int(box[1]), int(box[2]), int(box[3]), int(box[4]), file=txt_file)
txt_file.close()
下面的图片是在这篇文章中使用的示例图片。

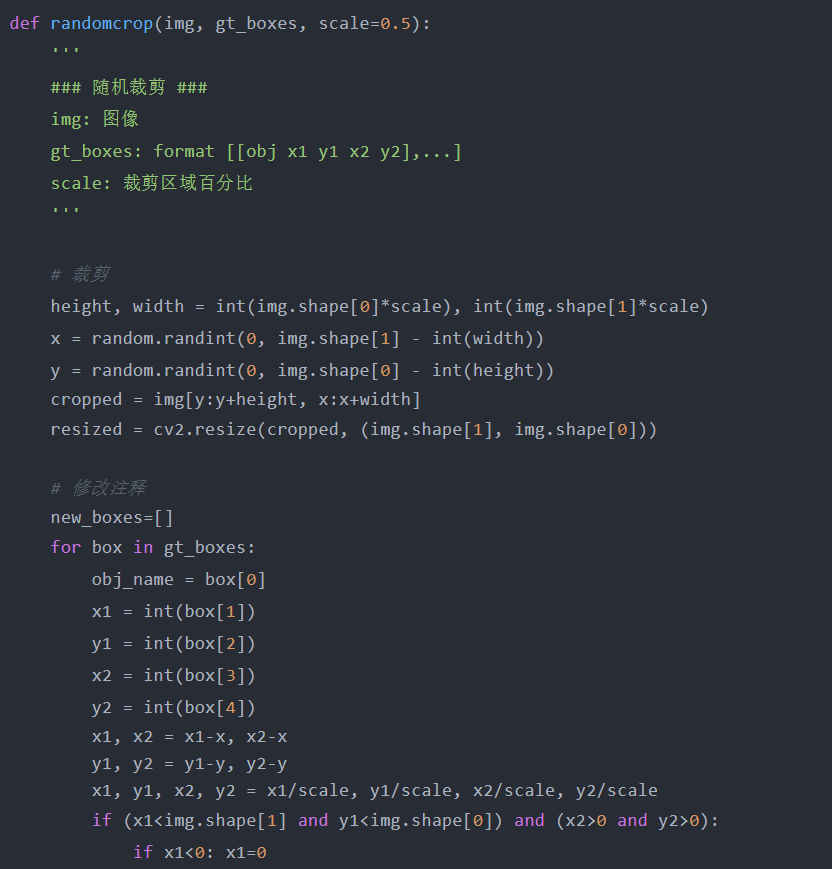
随机裁剪随机裁剪随机选择一个区域并进行裁剪以生成新的数据样本,裁剪后的区域应具有与原始图像相同的宽高比,以保持对象的形状。

从上图中,左侧图像表示具有边界框(红色)的原始图像,通过裁剪橙色框内的区域创建一个新样本作为右侧图像。在新示例的注释中,将删除与左侧图像中的橙色框不重叠的所有对象,并细化位于橙色框边界上的对象的坐标,使其适合新图像示例。原始图像的随机裁剪输出为新裁剪图像及其注释。

Cutout
Terrance DeVries和Graham W.Taylor在2017年的论文中介绍了Cutout,它是一种简单的正则化技术,用于在训练过程中随机屏蔽输入的方块区域,可用于提高卷积神经网络的鲁棒性和整体性能。
这种方法不仅非常容易实现,而且还表明它可以与现有形式的数据扩充和其他正则化工具结合使用,以进一步提高模型性能。
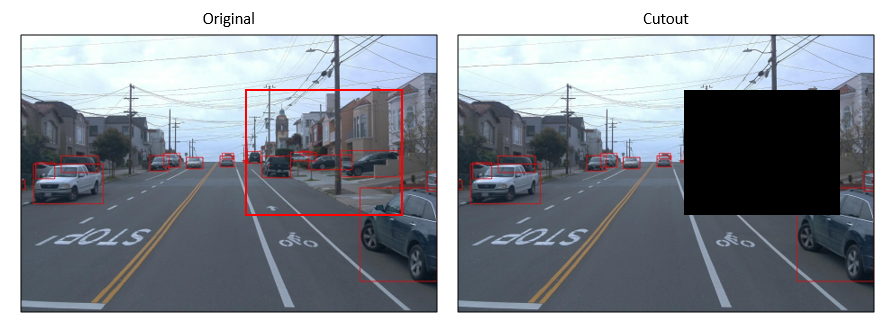
如本文所述,剪切用于提高图像识别(分类)的准确性,因此,如果我们将相同的方案部署到对象检测数据集中,可能会导致丢失对象的问题,尤其是小对象。
在下图中,cutout区域(黑色区域)内的大量小对象被移除,这不符合数据扩充的精神。
为了使这种方式适用于对象检测,我们可以进行简单的修改,而不是仅使用一个蒙版并将其放置在图像中的随机位置。当我们随机选择一半数量的对象并将剪切应用于这些对象区域时,效果会更好。增强图像如下图中的右图所示。
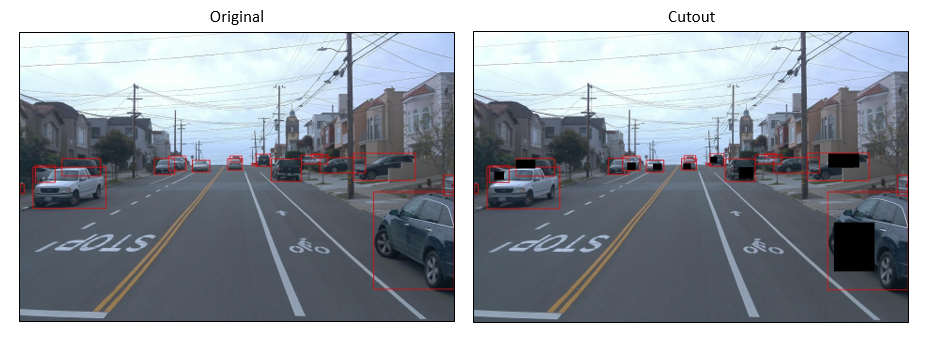
剪切输出是新生成的图像,我们不移除对象或更改图像大小,则生成图像的注释与原始图像相同。
def cutout(img, gt_boxes, amount=0.5):
'''
### Cutout ###
img: 图像
gt_boxes: format [[obj x1 y1 x2 y2],...]
amount: 蒙版数量/对象数量
'''
out = img.copy()
ran_select = random.sample(gt_boxes, round(amount*len(gt_boxes)))
for box in ran_select:
x1 = int(box[1])
y1 = int(box[2])
x2 = int(box[3])
y2 = int(box[4])
mask_w = int((x2 - x1)*0.5)
mask_h = int((y2 - y1)*0.5)
mask_x1 = random.randint(x1, x2 - mask_w)
mask_y1 = random.randint(y1, y2 - mask_h)
mask_x2 = mask_x1 + mask_w
mask_y2 = mask_y1 + mask_h
cv2.rectangle(out, (mask_x1, mask_y1), (mask_x2, mask_y2), (0, 0, 0), thickness=-1)
return out
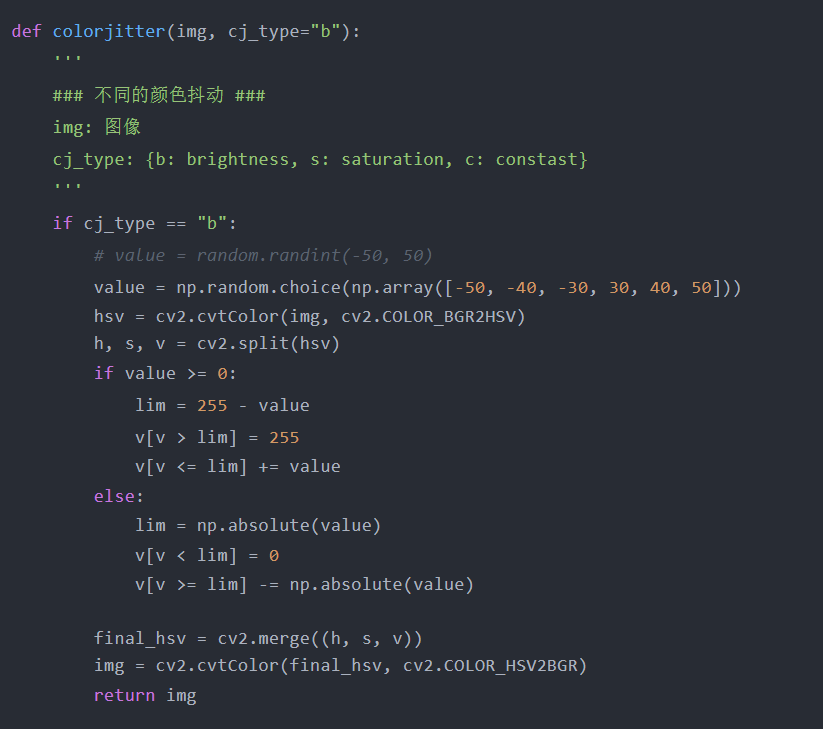
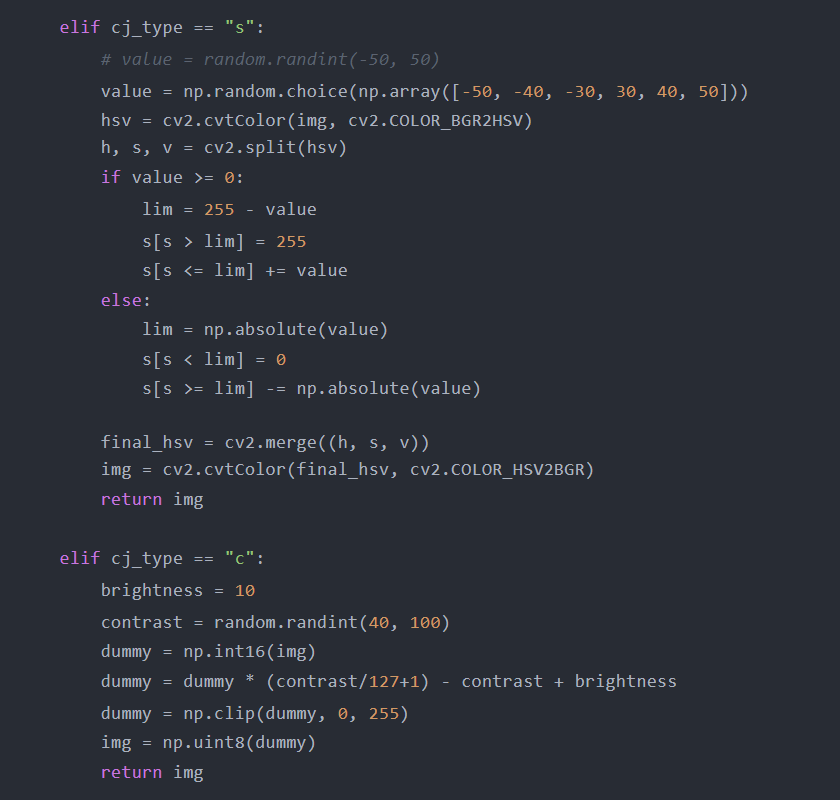
颜色抖动
ColorJitter是另一种简单的图像数据增强,我们可以随机改变图像的亮度、对比度和饱和度。我相信这个技术很容易被大多数读者理解。

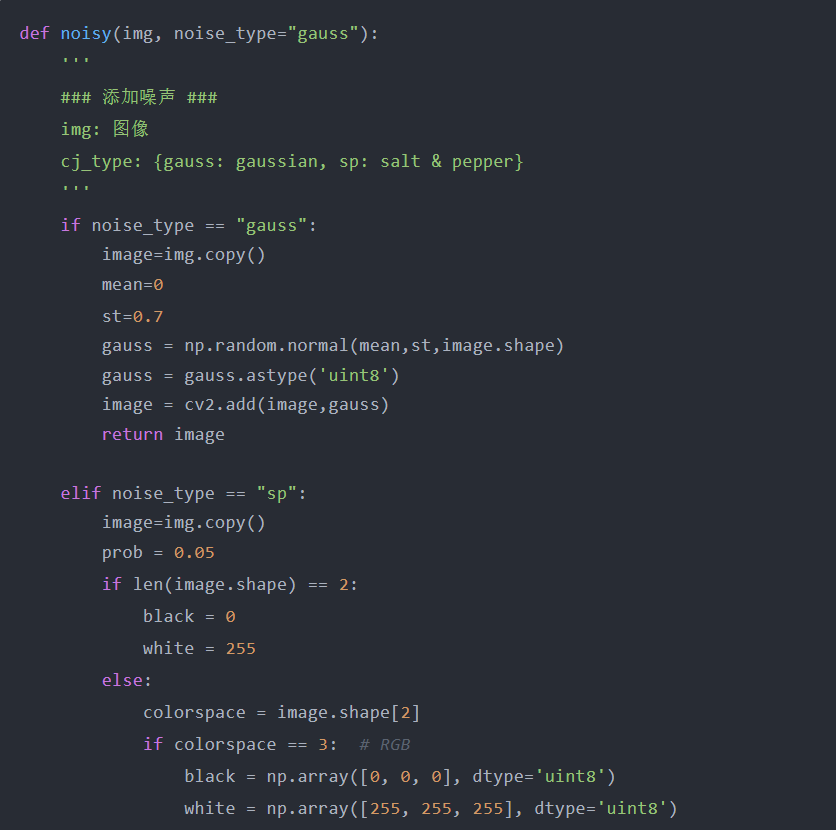
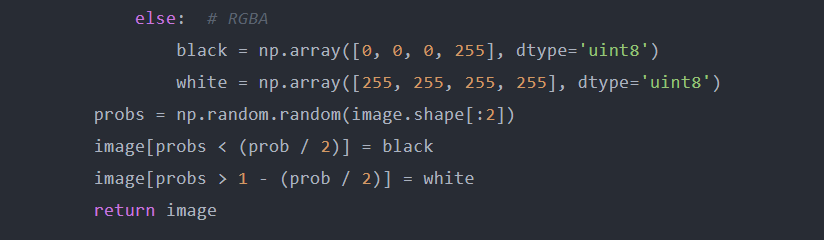
增加噪声在一般意义上,噪声被认为是图像中的一个意外因素,然而,几种类型的噪声(例如高斯噪声、椒盐噪声)可用于数据增强,在深度学习中添加噪声是一种非常简单和有益的数据增强方法。在下面的示例中,为了增强数据,将高斯噪声和椒盐噪声添加到原始图像中。

对于那些无法识别高斯噪声和椒盐噪声之间差异的人,高斯噪声的值范围为0到255,具体取决于配置,因此,在RGB图像中,高斯噪声像素可以是任何颜色。相比之下,椒盐噪波像素只能有两个值0或255,分别对应于黑色(PEPER)或白色(salt)。
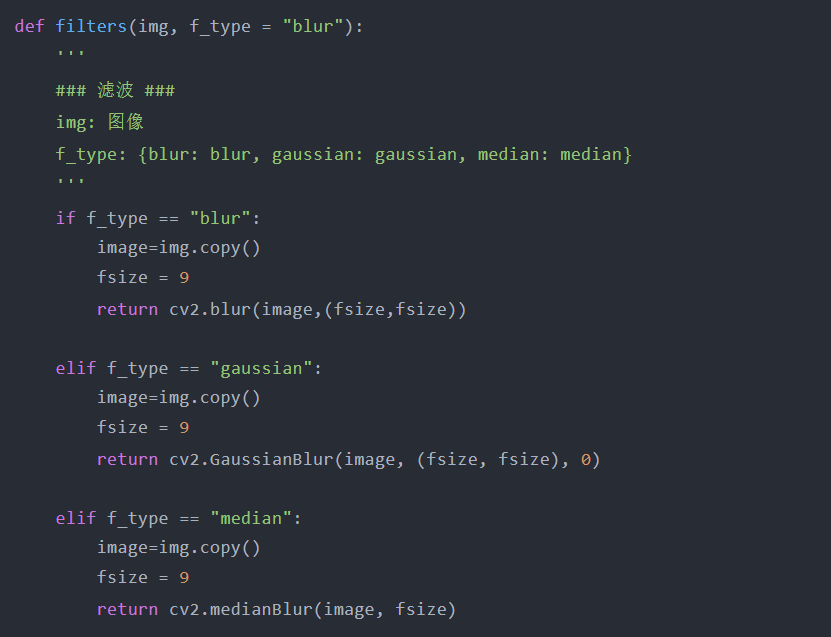
滤波本文介绍的最后一个数据扩充过程是滤波。与添加噪声类似,滤波也简单且易于实现。实现中使用的三种类型的滤波包括模糊(平均)、高斯和中值。

总结
在这篇文章中,向大家介绍了一个关于为对象检测任务实现数据增强的教程。你们可以在这里找到完整实现。
