基于EAST和Tesseract的文本检测
磐创AI目录
导言
现实世界问题
说明
问题陈述
业务目标和约束条件
可用于文本检测和识别的数据集
数据集概述和说明
探索性数据分析(EDA)
深度学习时代之前的文本检测方法
EAST(高效精确的场景文本检测器)
示范实现
模型分析与模型量化
部署
今后的工作
1.介绍
在这个数字化时代,从不同来源提取文本信息的需求在很大程度上增加了。
幸运的是,计算机视觉的最新进展减轻了文本检测和其他文档分析和理解的负担。
在计算机视觉中,将图像或扫描文档中的文本转换为机器可读格式的方法称为光学字符识别(OCR),该格式可在以后编辑、搜索并用于进一步处理。
光学字符识别的应用
A.信息检索和自动数据输入-OCR对于许多公司和机构起着非常重要的作用,这些公司和机构有成千上万的文档需要处理、分析和转换,以执行日常操作。
例如,在账户详细信息等银行信息中,可以使用OCR轻松提取支票金额。同样,在机场,在检查护照的同时也可以使用OCR提取信息。其他示例包括使用OCR从收据、发票、表单、报表、合同等中检索信息。
B车牌识别-OCR还可用于识别车辆牌照,然后可用于车辆跟踪、收费等。
C自动驾驶汽车-OCR也可用于建立自动驾驶汽车的模型。它可以帮助识别交通标志。否则,自动驾驶汽车将对道路上的行人和其他车辆构成风险。
在本文中,我们将讨论并实现用于OCR的深度学习算法。
数字化:将文本、图片或声音转换成计算机可以处理的数字形式
2.现实世界问题2.1说明
我们现在已经熟悉了文本检测和识别的各种应用。本文将讨论从自然场景图像中检测和识别文本。
因此,在我们的例子中,我们使用的是任何自然图像或场景(不特别是文档、许可证或车辆编号),对于给定的图像/场景,我们希望通过边界框定位图像中的字符/单词/句子。然后,我们要识别任何语言的本地化文本。总体工作流程图如下所示:
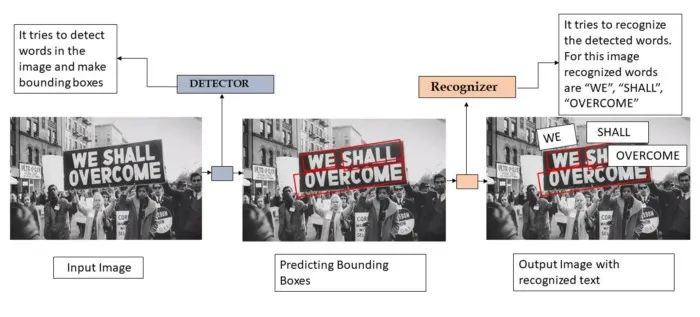
上面使用的图像用于显示整个任务。但对于本案例研究,我们将使用随机自然场景作为输入图像。
2.2问题陈述
对于给定的自然场景/图像,目标是通过绘制边界框来检测文本区域,然后必须识别检测到的文本。
2.3业务目标和约束条件。
自然场景图像中的文本可以使用不同的语言、颜色、字体、大小、方向和形状。我们必须在自然场景图像中处理这些文本,这些图像具有更高的多样性和可变性。
自然场景的背景可能带有图案或形状与任何文本极其相似的对象,这会在检测文本时产生问题。
图像中断(低质量/分辨率/多方向)
实时检测、识别和翻译图像中的文本需要低延迟。
3.可用于文本检测和识别的数据集
有许多公开的数据集可用于此任务,下面列出了不同的数据集,包括发布年份、图像编号、文本方向、语言和重要功能。
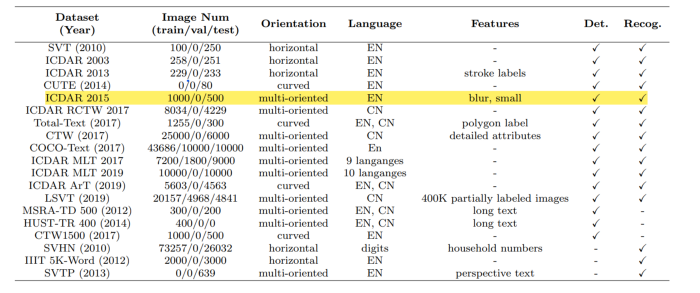
由于非结构化文本、不同方向等原因,所有数据集可能无法很好地适用于所有深度学习模型。
对于这项任务,我选择ICDAR 2015数据,因为它很容易获得足够数量的图像,用于非商业用途,这些图片中的文本是英文的,因为我是一名初学者,我想重点了解解决这项任务的算法的工作原理。
此外,该数据集中的图像很小,具有多方向性和模糊性,因此我可以对检测部分进行更多的实验。
3.1数据集概述和说明
数据源-下载:https://rrc.cvc.uab.es/?ch=4&com=downloads
ICDAR-2015由国际会议文件分析与识别提供
说明:
该数据集在训练和测试集中可用,每一组都有真实标签。它总共包含1500张图像,其中1000张用于训练,500张用于测试。它还包含2077个裁剪文本实例,包括200多个不规则文本示例。
这些图像是从可穿戴相机上获得的。
4.探索性数据分析(EDA)
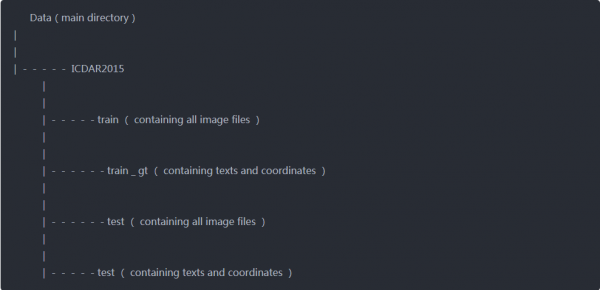
下载数据后,所有文件的结构如下-
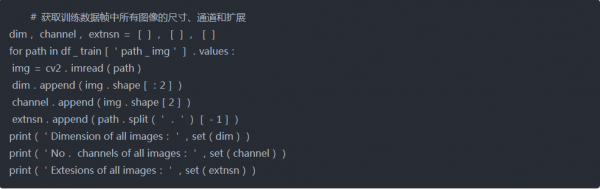
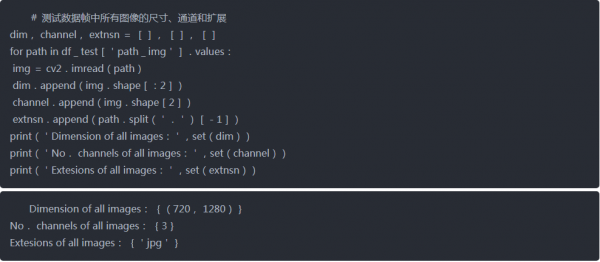
使用以下代码,观察到图像尺寸、通道数等其他信息
训练图像

测试图像
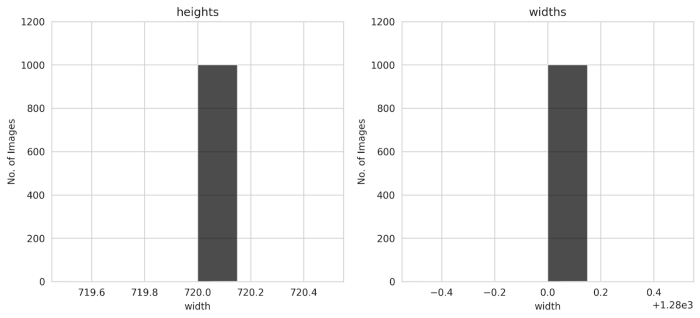
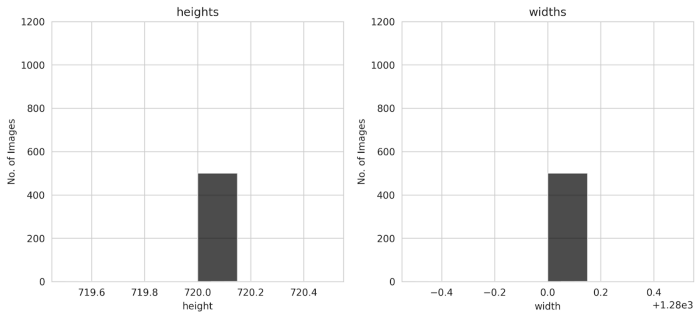
我们还可以从条形图得出结论,所有图像的高度和宽度都相同,即720和1280。
训练图像
测试图像
利用真实标签绘制原始图像和边界框图像
训练图像
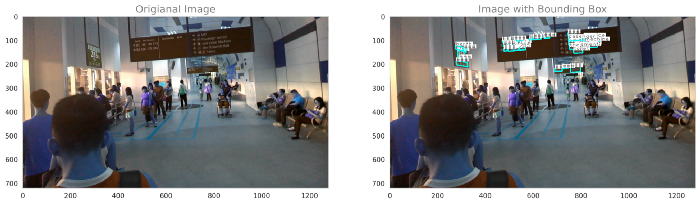

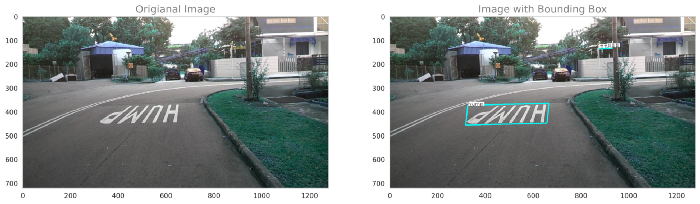
测试图像

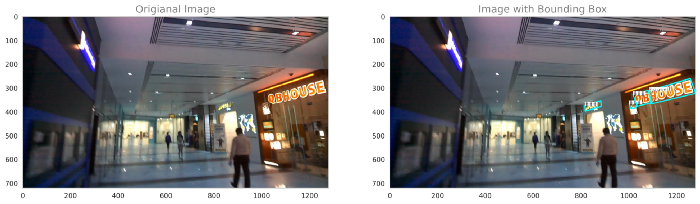

从EDA得出的结论
在ICDAR-15数据集中,所有图像具有相似的大小(720x1280)和扩展(.jpg)。
训练组有1000个图像,而测试组有500个图像。
所有图像的高度和宽度都是相同的,所以我们不需要取平均高度和平均宽度。
在大多数图像中,所有文本都位于小区域,图像模糊。
所有文本均为英语语言,少数文本也不可用,并且*替换为“###”。
大多数文本都是单个单词,而不是文字和句子,而且单词也有多种意思的。我们必须建立这样一个模型来预测这些模糊的文本。
5.深度学习时代之前的文本检测方法
正如问题陈述中提到的,我们必须首先定位图像中的文本,即首先检测文本,然后识别检测到的文本。
现在,对于检测,我们将尝试一些在深度学习时代之前用于检测文本的方法。
a.MSER
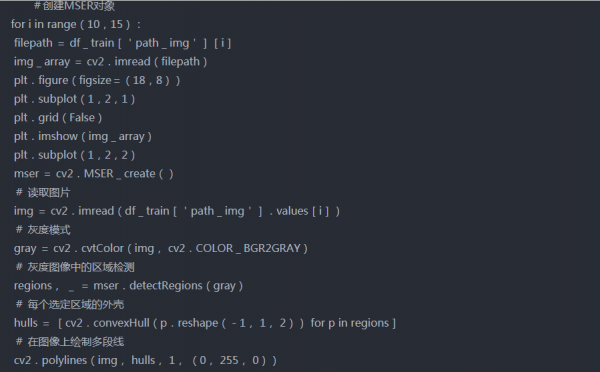






b. SWT(笔划宽度变换)
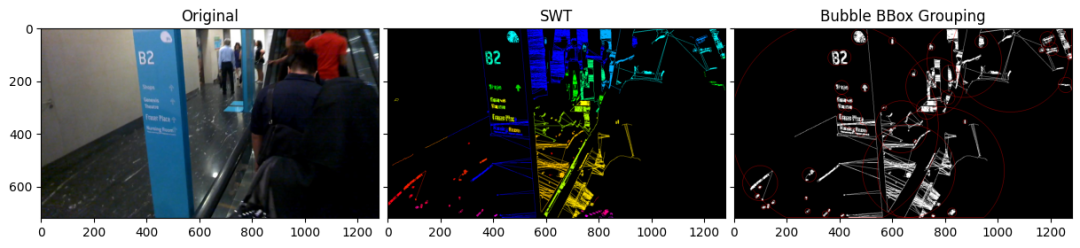
这两种方法的所有输出都不是很清楚,在第一种方法中,我们可以观察到图像中有一些区域没有文本,但仍然用方框标记。同样在第二种方法中,文本没有被正确检测。
还有许多其他用于文本检测和识别的深度学习算法。在本文中,我们将讨论EAST检测器,并将借助一篇关于EAST算法的研究论文尝试实现它。
https://arxiv.org/pdf/1704.03155.pdf
为了识别,我们将尝试预训练的模型Tesseract。
6.EAST(高效精确的场景文本检测器)
它是一种快速准确的场景文本检测方法,包括两个阶段:
1.它使用完全卷积网络(FCN)模型直接生成基于像素的单词或文本行预测
2.生成文本预测(旋转矩形或四边形)后,输出将发送到非极大值抑制以生成最终结果。
管道如下图所示:

网络体系结构-(带PVANet)
PVANet-它是一种用于目标检测的轻量级特征提取网络体系结构,可在不损失准确性的情况下实现实时目标检测性能。
该模型可分为三个部分:主干特征提取、特征合并分支和输出层。
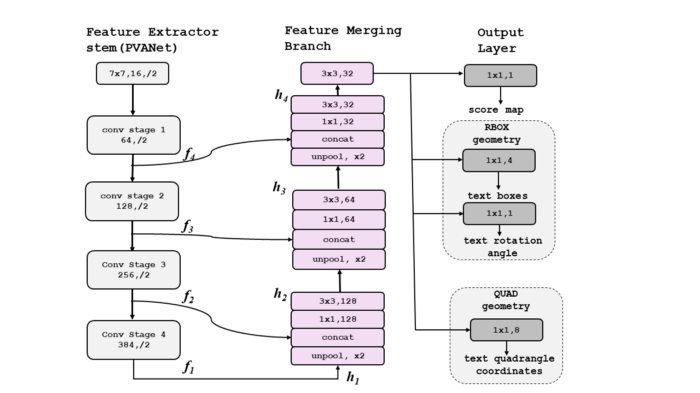
i.特征提取程序(PVANet)
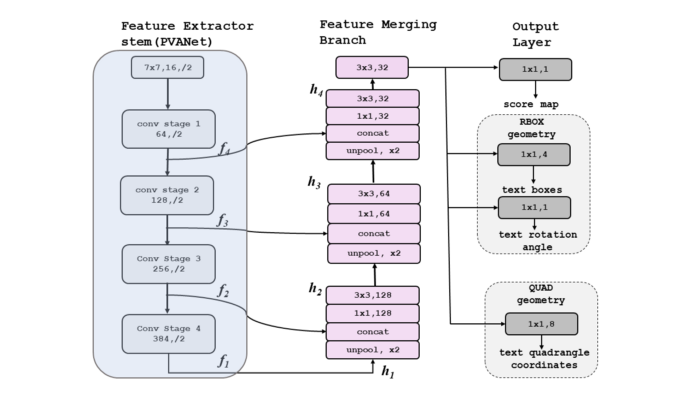
这部分可以是任何卷积神经网络,例如PVANet、VGG16和RESNET50。从该网络可以获得四个级别的特征图f1、f2、f3和f4。因为我们正在提取特征,所以它被称为特征提取器。
ii.特征合并分支
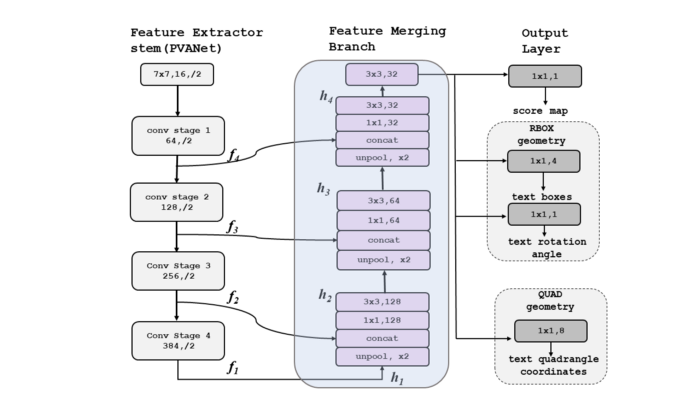
在这一部分中,从特征提取器获得的特征映射首先被馈送到上池化层,使其大小加倍,然后连接所有特征。接下来,使用1X1卷积,减少了计算,然后使用3X3卷积来融合信息,以产生每个合并阶段的最终输出,如图所示。
g和h的计算过程如下图所示
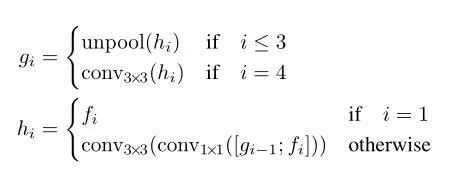
其中
gi是一种中间状态,是合并的基础
hi是合并的特征图
iii、输出层
合并状态的最终输出通过1X1 Conv层和1个通道,该通道给出范围为[0–1]的分数映射。最终输出还通过RBOX或四边形几何体(有关这些的说明如下图所示),该几何体给出了多通道几何体映射。

有关score map和geo map的详细信息将在实现时讨论。
7.实现
对于实现,我们将遵循上面显示的管道-
步骤1-数据准备和数据生成(数据管道)

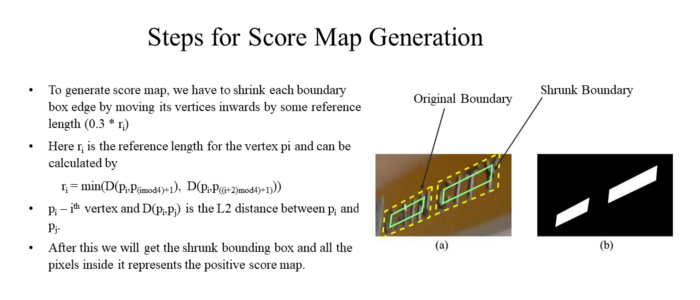
在这一步中,我们必须进行数据准备,还必须构建一个生成器函数,该函数将提供一个图像阵列(模型的输入),其中包含score map(输出)和geo map(输出),如上图所示,你可以观察到多通道FCN的输出以及训练掩码。
得分图:
它表示该位置预测几何地图的置信度分数/级别。它位于[0,1]范围内。让我们通过一个示例来理解它:
假设0.80是一个像素的分数,这意味着对于这个像素,我们有80%的信心预测对应的几何贴图,或者我们可以说,像素有80%的几率是预测文本区域的一部分。
geo map:
正如我们所知,随着score map,我们还获得了一个多通道几何信息地图作为输出。几何输出可以是RBOX或QUAD。下表显示了AABB、RBOX和QUAD的通道数量以及描述。
RBOX:
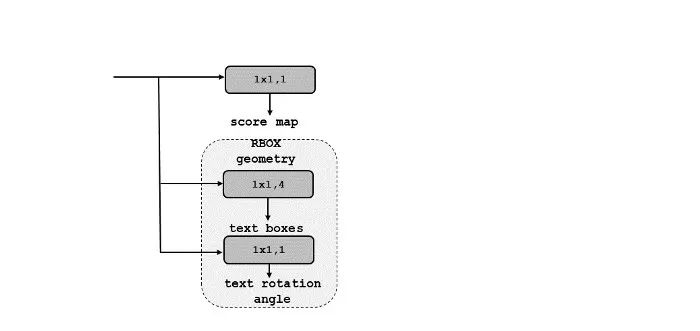
从上图中,我们可以观察到,对于RBOX,几何体使用四通道轴对齐边界框(AABB)R和通道旋转角度θ。R的公式为G。四个通道代表4个距离,即从像素位置到矩形边界的距离和通道的旋转角度,如下所示。
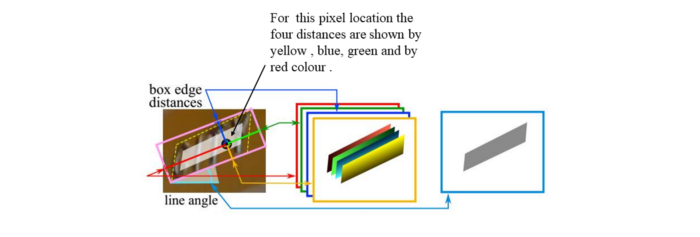
QUAD:

对于四边形,我们使用8个数字表示从四个顶点到每个像素位置的坐标位移。每个偏移距离包含Δxi | Δyi两个数,几何输出包含8个通道。下面是一个例子

在这个实现中,我们将只使用RBOX。
对于生成器功能,我们必须遵循几个步骤

这里有所有的代码
https://jovian.ai/paritosh/data-preparation-and-model-implt
此处显示了从生成器函数输出的原始图像,包括分数贴图、几何贴图和训练掩码-

步骤2:模型建立和损失函数

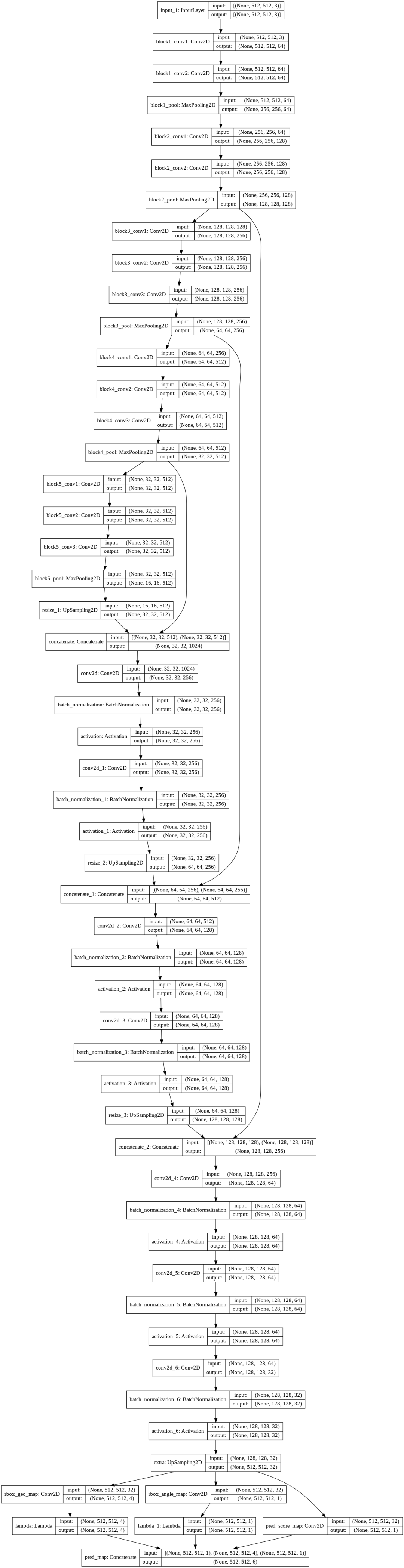
在这一步中,我们将尝试在Imagenet数据上使用预先训练过的VGG16模型和ResNet50模型作为特征提取器来构建检测器体系结构。
模型1(VGG16作为特征提取器)

源代码-
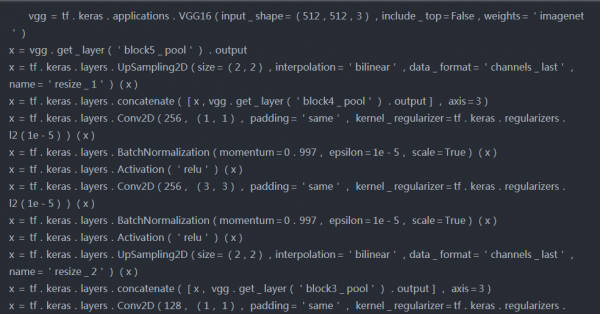
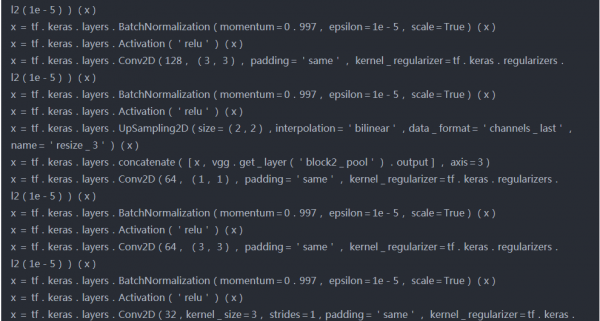
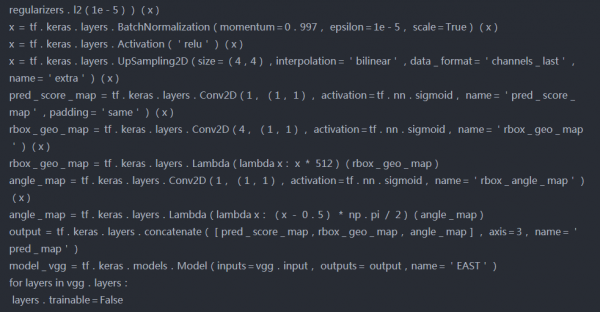
模型架构-
tf.keras.utils.plot_model(model_vgg,show_shapes=True)
模型2(作为特征提取器的ResNet50)
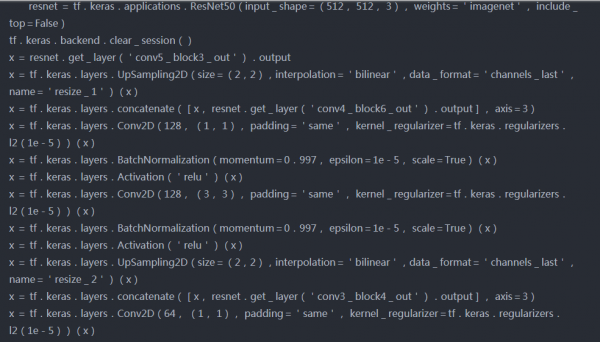
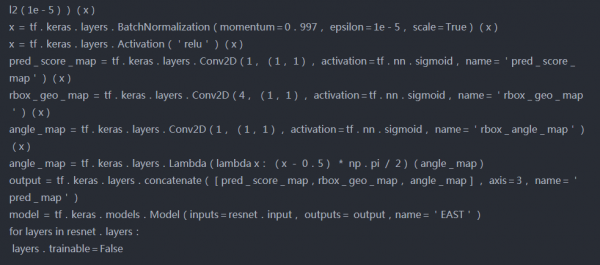
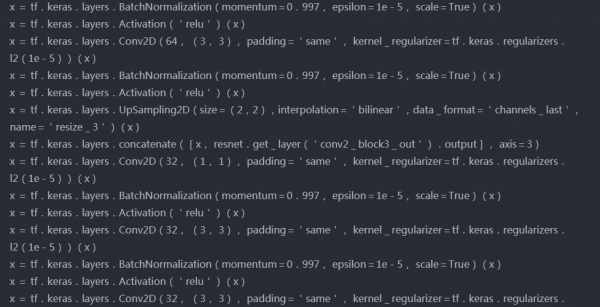
模型架构-
tf.keras.utils.plot_model(model,show_shapes=True)

损失函数
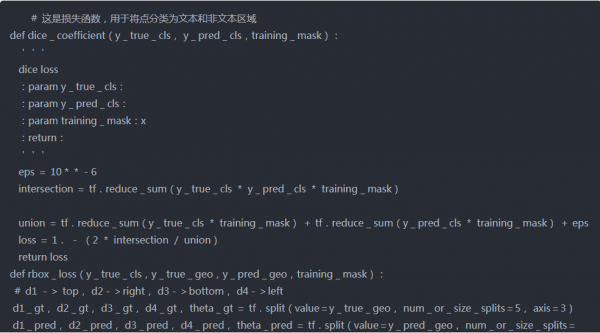
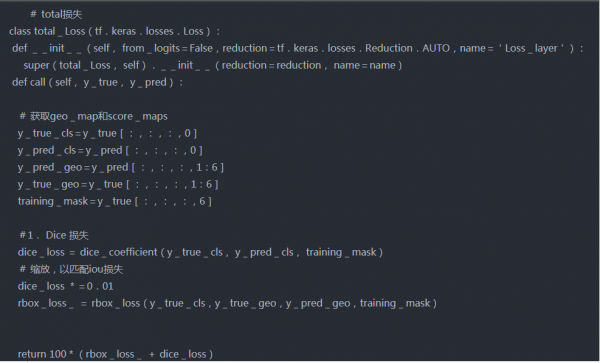
当我们处理图像数据时,IOU分数是常用的损失之一。但是这里我们主要有两个输出,score map和geo map,所以我们必须计算两者的损失。
总损失表示为:
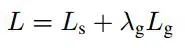
Ls和Lg表示得分图和几何形状,λg表示两个权重的重要性。在我们的实验中,我们设定λg为1。
score map损失
在本文中,用于score map的损失是二元交叉熵损失,其权重为正类和负类,如图所示。
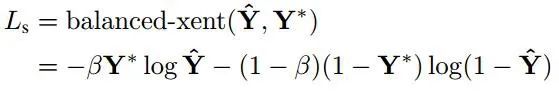
geo map损失
对于RBOX,损失定义为

第一个损失是盒子损失,对于这个IOU损失,它是针对不同比例的对象使用的不变量。
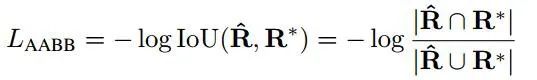
对于旋转角度,损失由下式给出-
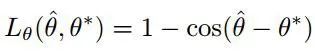
实现代码如下所示:
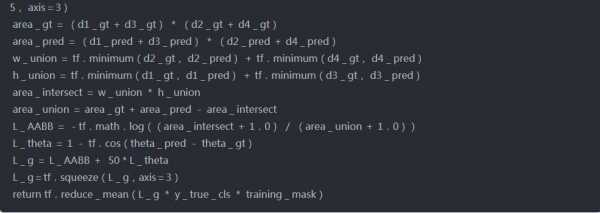
第三步模型训练
使用Adam优化器对这两个模型进行30个epoch的训练,其他参数如下所示-
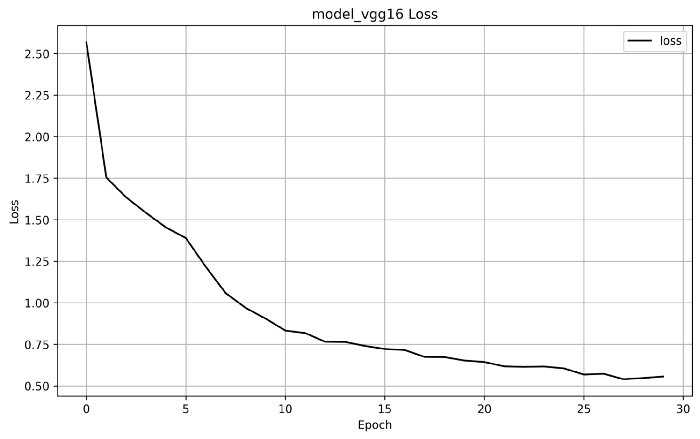
模型-1
model_vgg.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001,amsgrad=True),loss= total_Loss())
epoch与损失图:
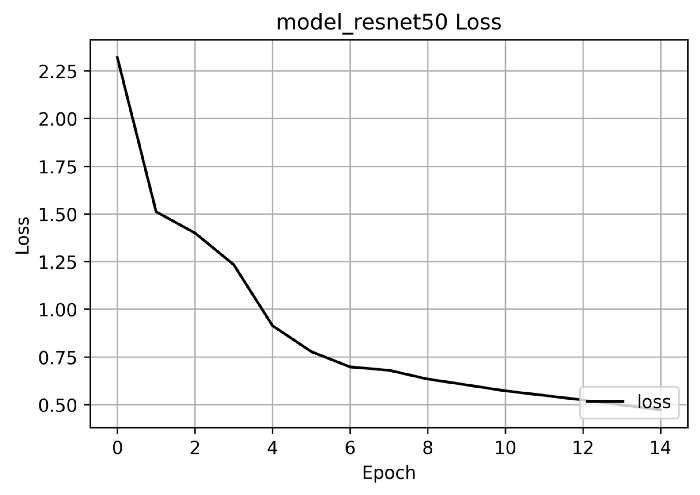
模型2
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001,amsgrad=True),loss=total_Loss())
epoch与损失图:
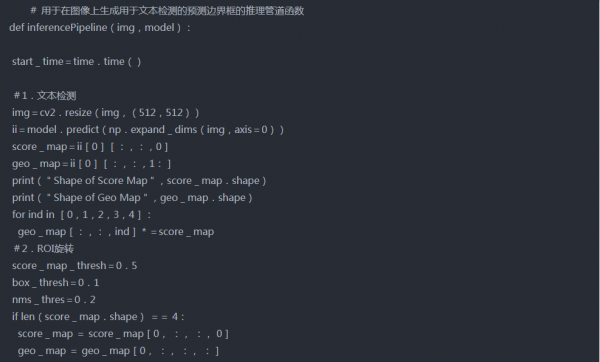
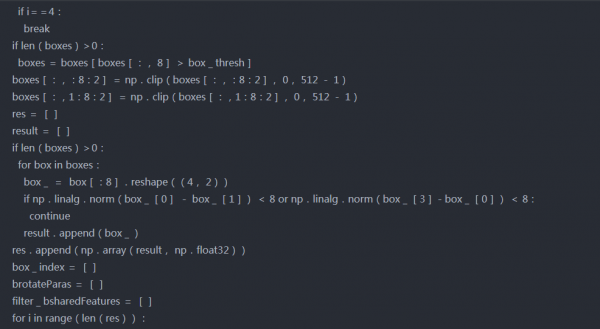
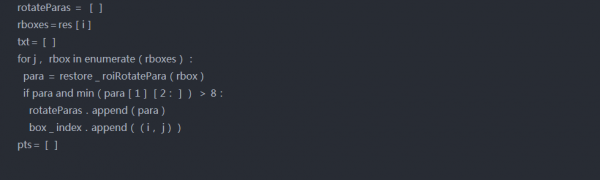
Step-4 推理管道
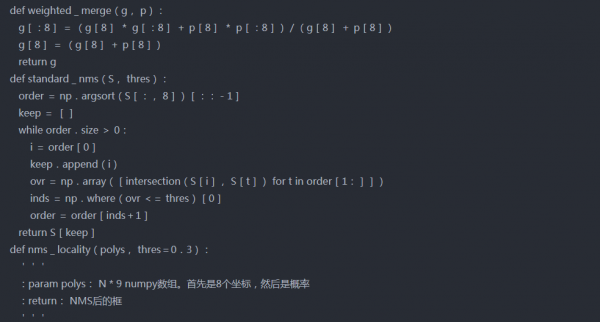
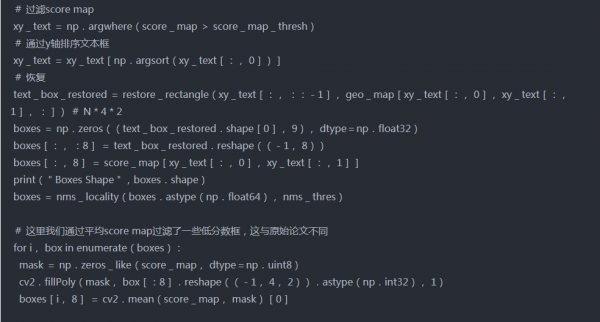
首先训练后,几何体贴图将转换回边界框。然后根据score map进行阈值分割,去除一些低置信度盒。使用非最大抑制合并其余框。
非最大抑制(NMS)是许多计算机视觉算法中使用的一种技术。这是一类从多个重叠实体中选择一个实体(例如边界框)的算法
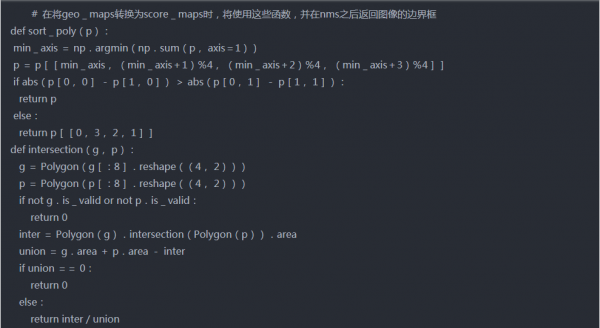
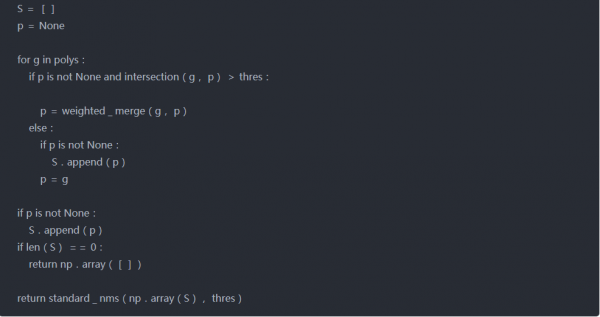
这里我们将使用本地感知的NMS。它将加权合并添加到标准NMS中。所谓加权合并是根据分数在输出框中合并高于某个阈值的2个IOU。下面讨论实施过程中遵循的步骤-
首先,对geo map形进行排序,并从最上面开始。
2.在这一行的下一个方框中找到带有上一个方框的iou
3.如果IOU>threshold,则通过按分数取加权平均值来合并两个框,否则保持原样。
4.重复步骤2至3,直到迭代所有框。
5.最后在剩余的框上应用标准NMS。
实现代码-
非最大抑制
检测模型的干扰管道
每个模型的输出:模型-1
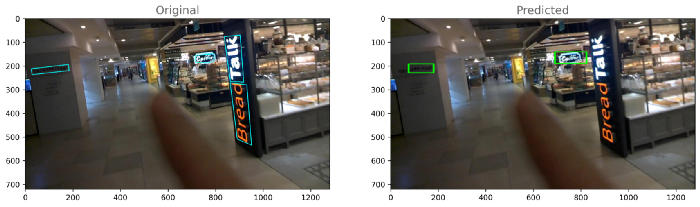
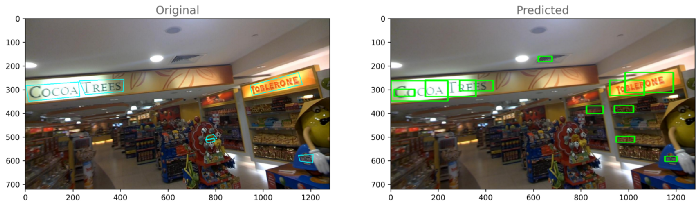
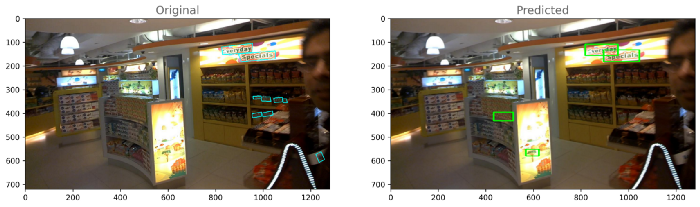
模型2
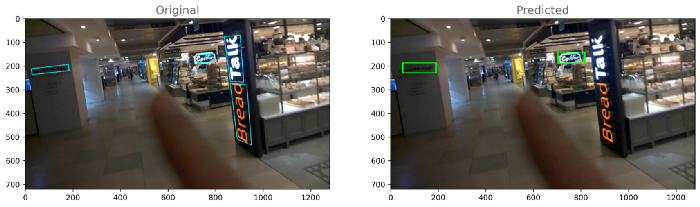
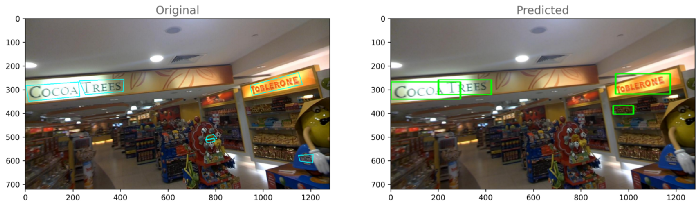

如果我们比较两个模型的损失,那么我们可以得出结论,模型2(resnet_east)表现良好。让我们对模型2的性能进行分析。8.模型分析与模型量化正如我们所看到的,模型2的性能优于模型1,这里我们将对模型2的输出进行一些分析。首先,计算训练和测试目录中每个图像的损失,然后基于分布,通过查看每个训练和测试图像的损失,我们将选择两个阈值损失,最后,我们将数据分为三类,即最佳、平均和最差。训练和测试的密度图-
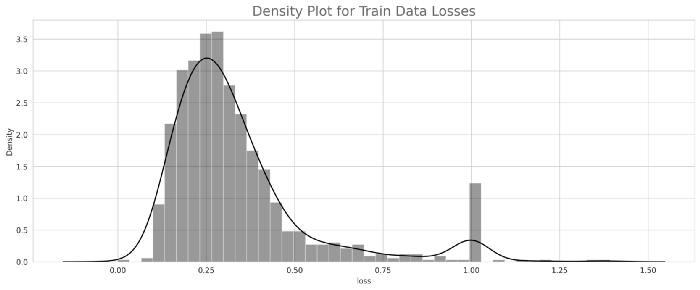
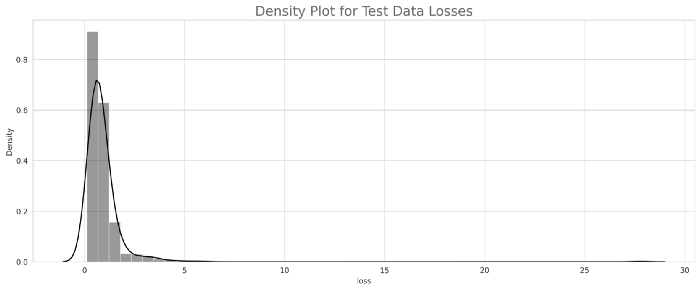
将图像数据分为3类(最佳、平均和最差)将数据分为3类Best = if loss < np.percentile(final_train.loss, 33)----->Threshold-1
Average = if np.percentile(final_train.loss, 33)< loss < np.percentile(final_train.loss, 75)
Worst = if loss > np.percentile(final_train.loss, 75)--Threshold-2
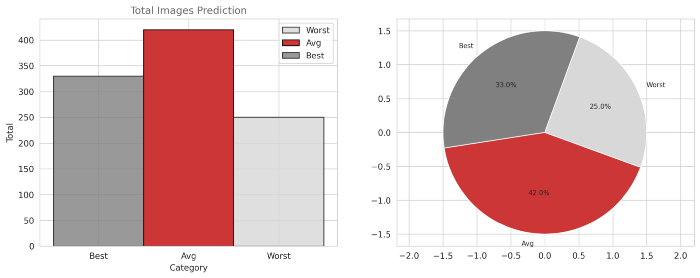
每个类别的图像数量如下所示:训练图像:
对于测试图像:
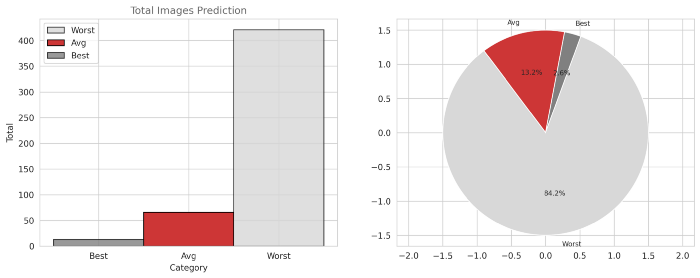
从第一个图中,对于训练数据,我们可以观察到33%的数据属于最佳类别,42%的数据属于平均类别,只有25%的数据属于最差类别。从第二个图中,对于测试数据,我们可以观察到2.6%的数据属于最佳类别,13.2%的数据属于平均类别,84.2%的数据属于最差类别。从这些观察结果中,我们还可以得出结论,我们的模型可能对测试图像(即新图像)表现不佳。模型量化深度学习的量化是通过低位宽数的神经网络近似使用浮点数的神经网络的过程。这大大降低了使用神经网络的内存需求和计算成本。量化后,原始模型和量化模型的大小如下所示-print("Orignal model size=",(os.path.getsize('east_resnet.h5')/1e+6),"MB")
print("Dynamic Post Training Quantization model size=",os.path.getsize('dynamic_east.tflite')/1e+6,"MB")
print("Float16 Post Training Quantization model size=",os.path.getsize('east_float16.tflite')/1e+6,"MB")
Orignal model size= 105.43348 MB
Dynamic Post Training Quantization model size= 24.810672 MB
Float16 Post Training Quantization model size= 48.341456 MB
9.部署模型量化后,使用streamlit和Github选择并部署了float16量化模型。使用Streamlight uploader函数,创建了一个.jpg文件输入部分,你可以在其中提供原始图像数据,模型将提供图像上存在检测到的文本。网页链接-https://share.streamlit.io/paritoshmahto07/scene-text-detection-and-recognition-/main/app_2.py部署视频-https://youtu.be/Pycj2fszhTk10.今后的工作在这项任务中,我们的主要目标是了解检测模型的工作原理,并从头开始实现它。为了提高模型的性能,我们可以使用大数据集来训练我们的模型。我们还可以使用另一种识别模型来更好地识别文本。Github:https://github.com/paritoshMahto07
