如何设计可口可乐瓶的图像识别方法?
磐创AI介绍
可口可乐公司已经进行了瓶子的再利用,接受了其随之而来的所有环境影响和金钱利益。当客户购买玻璃瓶中的可乐饮料时,他们会在返回空瓶时获得奖励,而如果没有奖励则会这些玻璃瓶被扔掉和浪费,所以我们可以设计一种自动识别可口可乐瓶的图像识别方法。使用带有大“ Coca Cola”字样的标签可以轻松辨认可口可乐瓶,而且该字样通常为白色,我们可以通过隔离白色并在分割图像上训练模型来获得标签。依赖库import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from matplotlib import cm
from matplotlib import colors
import os
import cv2
import PIL
from tensorflow.keras.layers import Dense,Conv2D, Dropout,Flatten, MaxPooling2D
from tensorflow import keras
from tensorflow.keras.models import Sequential, save_model, load_model
from tensorflow.keras.optimizers import Adam
import tensorflow as tf
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.preprocessing.image import load_img
from tensorflow.keras.applications.inception_v3 import InceptionV3, preprocess_input
from tensorflow.keras.callbacks import ModelCheckpoint
from sklearn.decomposition import PCA
Numpy用于操纵数组数据。Matplotlib用于可视化图像,并显示在特定的颜色范围内颜色可辨性。OS用于访问文件结构。CV2用于读取图像并将其转换为不同的配色方案。Keras用于实际的神经网络。转换颜色方案确定适当的颜色方案:为了能够隔离颜色,我们需要检查颜色在不同配色方案中的可分辨性,可以为此使用3D图首先,我们可以在3D空间中以RGB颜色格式可视化图像。在这里,我们基本上将图像分为其成分(在这种情况下为红色,绿色和蓝色),然后设置3D图;接下来是对图像进行整形,然后对图像进行归一化,从而将范围从0-255减小到0-1;最后,使用scatter()函数创建散点图,然后我们相应地标记轴。red, green, blue = cv2.split(img)
fig = plt.figure()
axis = fig.add_subplot(1, 1, 1, projection="3d")
pixel_colors = img.reshape((np.shape(img)[0]*np.shape(img)[1], 3))
norm = colors.Normalize(vmin=-1.,vmax=1.)
norm.autoscale(pixel_colors)
pixel_colors = norm(pixel_colors).tolist()
axis.scatter(red.flatten(), green.flatten(), blue.flatten(), facecolors=pixel_colors, marker=".")
axis.set_xlabel("Red")
axis.set_ylabel("Green")
axis.set_zlabel("Blue")
plt.show()
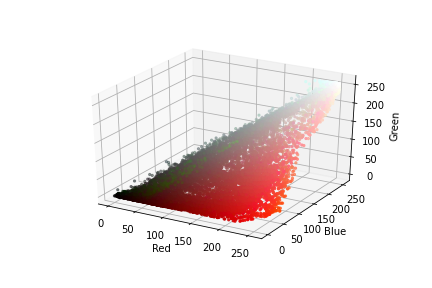
HSL和HSV方案通常可以更好地用于图像分割,我们可以在HSL方案中绘制图像的3D图。hue, saturation, lightness = cv2.split(img)
fig = plt.figure()
axis = fig.add_subplot(1, 1, 1, projection="3d")
axis.scatter(hue.flatten(), saturation.flatten(), lightness.flatten(), facecolors=pixel_colors, marker=".")
axis.set_xlabel("Hue")
axis.set_ylabel("Saturation")
axis.set_zlabel("Lightness")
plt.show()
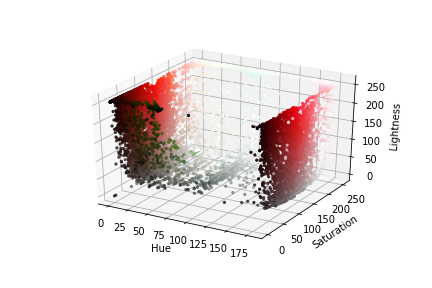
要注意的是,第二种图中的特定颜色不像第一种中那样混乱,我们可以很容易地从其余像素中分辨出白色像素。转换颜色默认情况下,CV2以BGR方案读取图像。img = cv2.imread(img_path)
plt.imshow(img)
plt.show()

该图像需要先转换为RGB格式img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.imshow(img)
plt.show()
最后,应将此图像转换为HLS方案,以便于识别颜色。HSL是图像的色相,饱和度和亮度的描述。img = cv2.cvtColor(img, cv2.COLOR_RGB2HLS)
plt.imshow(img)
plt.show()
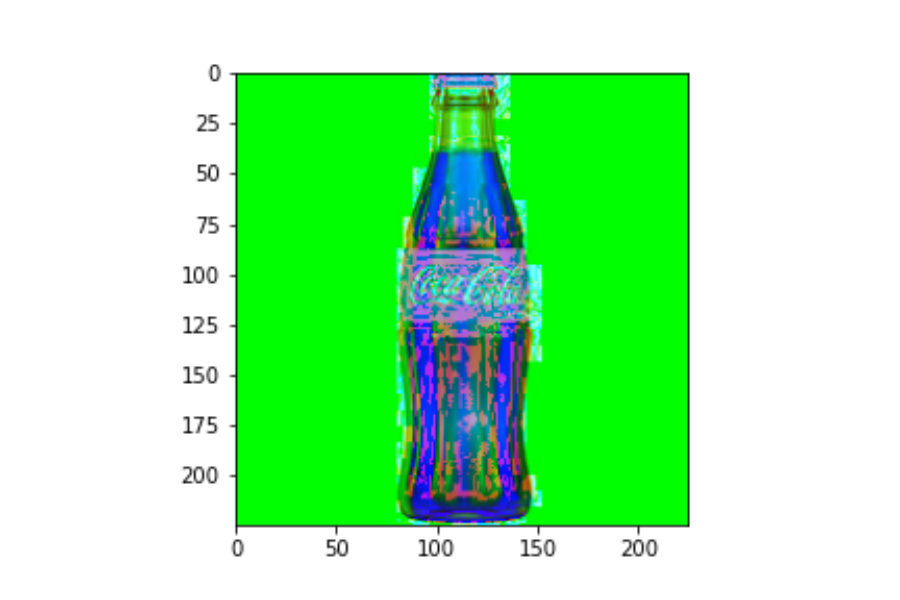
隔离色白色:我们为白色指定较低和较高的阈值,然后使用cv2.inRange()指定对HSL图像进行阈值处理的蒙版,这会返回0和1。然后,我们使用bitwise_and函数将蒙版施加到原始RGB图像上,如果蒙版的相应值为1,它将保留像素值,同时我们应用高斯模糊以平滑边缘。hsl_img = cv2.cvtColor(img, cv2.COLOR_RGB2HLS)
low_threshold = np.array([0, 200, 0], dtype=np.uint8)
high_threshold = np.array([180, 255, 255], dtype=np.uint8)
mask = cv2.inRange(hsl_img, low_threshold, high_threshold)
white_parts = cv2.bitwise_and(img, img, mask = mask)
blur = cv2.GaussianBlur(white_parts, (7,7), 0)
INCEPTIONV3的迁移学习有些模型需要很长时间来训练,但最终仍然没有达到预计的预测精度。虽然从零开始创建模型没问题,但迁移学习使用的模型在ImageNet图像上产生了巨大的效果。在这个特定的项目中,我会展示如何使用InceptionV3。我们定义要使用的模型,包括权重和输入形状,然后将X的值放入模型中,并将结果值保存在名为“bottle_nec_features_train”的变量中。model = InceptionV3(weights='imagenet', include_top=False, input_shape=(299, 299, 3))
bottle_neck_features_train = model.predict_generator(X, n/32, verbose=1)
bottle_neck_features_train.shape
np.savez('inception_features_train', features=bottle_neck_features_train)
train_data = np.load('inception_features_train.npz')['features']
train_labels = np.array([0] * m + [1] * p) // where m+p = n
结果特征的形状为((n,8,8,2048)),n为所用图像的数量;然后,我们将值保存在名为“ inception_features_train.npz”的文件中,以避免重复的预训练。可口可乐瓶识别是一个二进制分类问题(一个瓶子要么是可口可乐瓶,要么不是),因此,标签可以是“可乐”的0或“非可乐”的1(或数字对的任何其他组合)。可以通过创建一系列等于可乐瓶图像数量的零,然后为其余图像添加一个零,来制作出训练标签。神经网络神经网络可以描述为一系列通过模仿人脑工作方式来解决问题的算法,在这里,我们采用序列Keras模型。classifier = Sequential()
classifier.add(Conv2D(32, (3, 3), activation='relu', input_shape=train_data.shape[1:], padding='same'))
classifier.add(Conv2D(32, (3, 3), activation='relu', padding='same'))
classifier.add(MaxPooling2D(pool_size=(3, 3)))
classifier.add(Dropout(0.25))
classifier.add(Conv2D(64, (3, 3), activation='relu', padding='same'))
classifier.add(Conv2D(64, (3, 3), activation='relu', padding='same'))
classifier.add(MaxPooling2D(pool_size=(2, 2)))
classifier.add(Dropout(0.50))
classifier.add(Flatten())
classifier.add(Dense(512, activation='relu'))
classifier.add(Dropout(0.6))
classifier.add(Dense(256, activation='relu'))
classifier.add(Dropout(0.5))
classifier.add(Dense(1, activation='sigmoid'))
输入层是卷积层,用于该层的参数是:过滤器的数量为32,内核大小为3×3,激活函数为“整流线性单位”,输入形状为一幅图像的形状,并进行填充。第一个conv2d层的输入总是4D数组,前三个维度是图像输入,最后一个维度是通道。校正后的线性单元是一个非线性激活函数,尽管看起来是一个线性函数,但它执行的计算可能产生作为输入的附加值,也可能产生零。MaxPooling用于特征提取,我们将池大小设置为3,3,这意味着模型将提取一个3,3像素图像,并在该池中获得最大值。dropout 用于防止过度拟合,在训练阶段的每次更新时,它会将隐藏单元的输出边缘随机设置为0。Flatten层将输入数据转换为2D数组,全连接层确保一层的每个节点都连接到下一层的另一个节点。我们将Sigmoid激活函数用于输出层。输入将转换为0.0到1.0之间的值,远大于1.0的输入将转换为值1.0,类似地,远小于0.0的值将捕捉为0.0。对于所有可能的输入,函数的形状为S形,范围从零到0.5到1.0。为了以特定的间隔保存模型和权重,我们将ModelCheckpoint与model.fit一起使用。将'save_best_only'设置为true可确保仅保存产生最佳结果的模型,最后,我们编译模型并拟合数据。checkpointer = ModelCheckpoint(filepath='./weights_inception.hdf5', verbose=1, save_best_only=True)
classifier.compile(optimizer='adam',loss='binary_crossentropy',metrics=['binary_accuracy'])
history = classifier.fit(train_data, train_labels,epochs=50,batch_size=32, validation_split=0.3, verbose=2, callbacks=[checkpointer], shuffle=True)
执行预测由于我们需要使用与输入到分类器的数据相似的数据,因此我们可以编写一个函数来进行转换然后进行预测。def predict(filepath):
img = cv2.imread(filepath)
img = cv2.resize(img,(299,299))
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
hsl_img = cv2.cvtColor(img, cv2.COLOR_RGB2HLS)
low_threshold = np.array([0, 200, 0], dtype=np.uint8)
high_threshold = np.array([180, 255, 255], dtype=np.uint8)
mask = cv2.inRange(hsl_img, low_threshold, high_threshold)
white_parts = cv2.bitwise_and(img, img, mask = mask)
blur = cv2.GaussianBlur(white_parts, (7,7), 0)
print(img.shape)
clf = InceptionV3(weights='imagenet', include_top=False, input_shape=white_parts.shape)
bottle_neck_features_predict = clf.predict(np.array([white_parts]))[0]
np.savez('inception_features_prediction', features=bottle_neck_features_predict)
prediction_data = np.load('inception_features_prediction.npz')['features']
q = model.predict( np.array( [prediction_data,] ) )
prediction = q[0]
prediction = int(prediction)
print(prediction)
下一步在进行预测之前我们需要准备以下东西:有效的预测模型。保存的模型值。用于预测的图像。准备进行预测的功能。现在,我们可以对图像进行预测了。我们需要做的就是调用predict函数并将路径传递给图像作为参数。predict("./train/Coke Bottles/Coke1.png")
这应该提供1作为输出,因为我们的可乐瓶图像标记为1。保存模型如果这在软件中完全适用,例如使用OpenCV模块查看图像或视频并进行预测的实时应用程序,那么我们就不能期望每次打开程序时都训练我们的模型。更为合理的做法是保存模型并在程序打开后将其加载,这意味着我们需要利用Keras的load_model和save_model,我们将其导入如下。from tensorflow.keras.models import Sequential, save_model, load_model
现在,我们可以通过调用save_model() 并输入文件夹名称作为参数来保存模型。save_model(save_model)
最后,我们可以简单地使用 load_model 加载模型,而不用输入代码来重新训练模型,从而整理所有程序。load_model("./save_model")
