一文学会使用CNN进行人脸关键点识别
磐创AI项目概况
该项目的目标是预测面部图片上关键点的位置。这可以用作各种应用程序中的组件,包括:
图片和视频中的人脸识别。
面部表情的研究。
用于医学诊断,识别畸形面部症状。
识别面部关键点是一个很难解决的话题。人与人的面部特征差异很大,即使在一个人内,由于 3D 姿势、大小、位置、视角和照明环境,也会存在很多差异。尽管计算机视觉研究在解决这些问题方面取得了长足的进步,但仍有许多可以改进的领域。
目录
介绍
先决条件
程序和编程
面部关键点检测的有用应用
介绍
利用卷积神经网络和计算机视觉技术进行人脸关键点检测,对人脸的重要区域(如眼睛、嘴角和鼻子)进行标记,这些区域与各种任务(如人脸滤波、情感识别和姿势识别)相关。
它需要预测特定面部的面部关键点坐标,例如鼻尖、眼睛中心等。为了识别面部关键点,我们使用基于卷积神经网络的模型使用自动编码器。
卷积神经网络 (CNN) 具有深层结构,允许它们提取高级信息并在识别每个重要点时提供更好的精度。卷积网络旨在同时预测所有点。

先决条件
因为神经网络经常需要标准化的图片,所以它们应该有一个恒定的大小,颜色范围和坐标的标准化范围,并从 NumPy 列表和数组转换为 Tensor 和 Keras(用于 PyTorch)。因此,需要进行一些预处理。
程序和编程
我正在使用 Kaggle 数据集来训练模型,你可以通过运行 API 命令下载它kaggle competitions download -c facial-keypoints-detection
导入 NumPy 和 pandas 库:import numpy as np # linear algebra
import pandas as pd # data processing
import os
for directoryname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(directoryname, filename))
你写入当前目录的任何输出都会被存储。下一步是为训练和测试数据的每个文件设置路径,train_zip_path = "../input/facial-keypoints-detection/training.zip"
test_zip_path = "../input/facial-keypoints-detection/test.zip"
id_lookup_table = "../input/facial-keypoints-detection/IdLookupTable.csv"
sample_Submission = "../input/facial-keypoints-detection/SampleSubmission.csv"
让我们使用 zip 文件解压 zip 文件,然后加载数据集。import zipfile
with zipfile.ZipFile(train_zip_path,'r') as zip_ref:
zip_ref.extractall('')
with zipfile.ZipFile(test_zip_path,'r') as zip_ref:
zip_ref.extractall('')
train_df = pd.read_csv('training.csv')
test_df = pd.read_csv('test.csv')
idLookupTable = pd.read_csv(id_lookup_table)
sampleSumission = pd.read_csv(sample_Submission)
加载数据集后,我们可以使用pandas的库查看数据框,并列出数据集的头部。train_df.info()
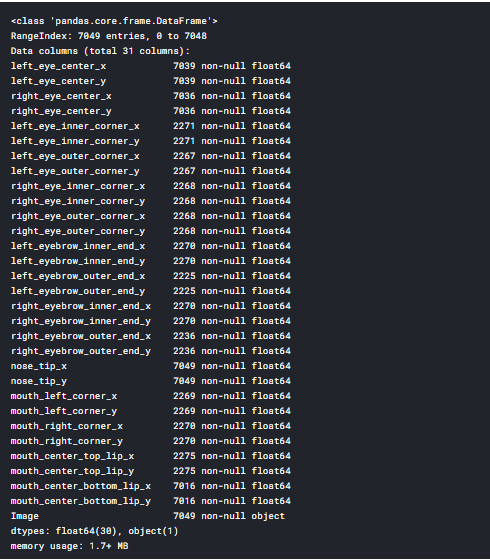
填充 Nan 值并分离和重塑输入值(x_train) train_df.fillna(method='ffill',inplace=True)
在训练数据集中分离和重塑输入值(x_train):使用图像创建一个数组,keypoints:关键点将是我们数据集的一个样本。我们的数据集将接受一个可选的参数转换,允许我们对样本执行任何必要的处理。image_df = train_df['Image']
imageArr = []
for i in range(0,len(image_df)):
img = image_df[i].split()
img = ['0' if x == '' else x for x in img]
imageArr.append(img)
x_train = np.array(imageArr,dtype='float')
x_train = x_train.reshape(-1,96,96,1)
print(x_train.shape)
创建一个以图片为输入输出关键点的CNN:输入图片大小为224*224px(由transform决定),输出类分数为136,即136/2 = 68。(我们想要的68个关键点)和分离目标值keypoints_df = train_df.drop('Image',axis = 1)
y_train = np.array(keypoints_df,dtype='float')
print(y_train.shape)
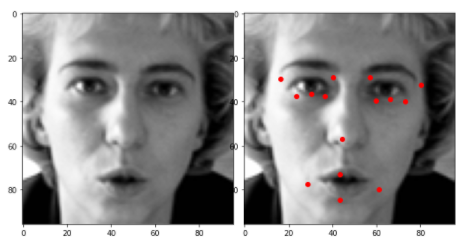
def visualizeWithNoKeypoints(index):
plt.imshow(x_train[index].reshape(96,96),cmap='gray')
def visualizeWithKeypoints(index):
plt.imshow(x_train[index].reshape(96,96),cmap='gray')
for i in range(1,31,2):
plt.plot(y_train[0][i-1],y_train[0][i],'ro')
在我们编写了可视化函数之后,接下来,我们可以使用函数调用来可视化每个图像import matplotlib.pyplot as plt
fig = plt.figure(figsize=(8,4))
fig.subplots_adjust(left=0,right=1,bottom=0,top=1,hspace=0.05,wspace=0.05)
plt.subplot(1,2,1)
visualizeWithNoKeypoints(1)
plt.subplot(1,2,2)
visualizeWithKeypoints(1)
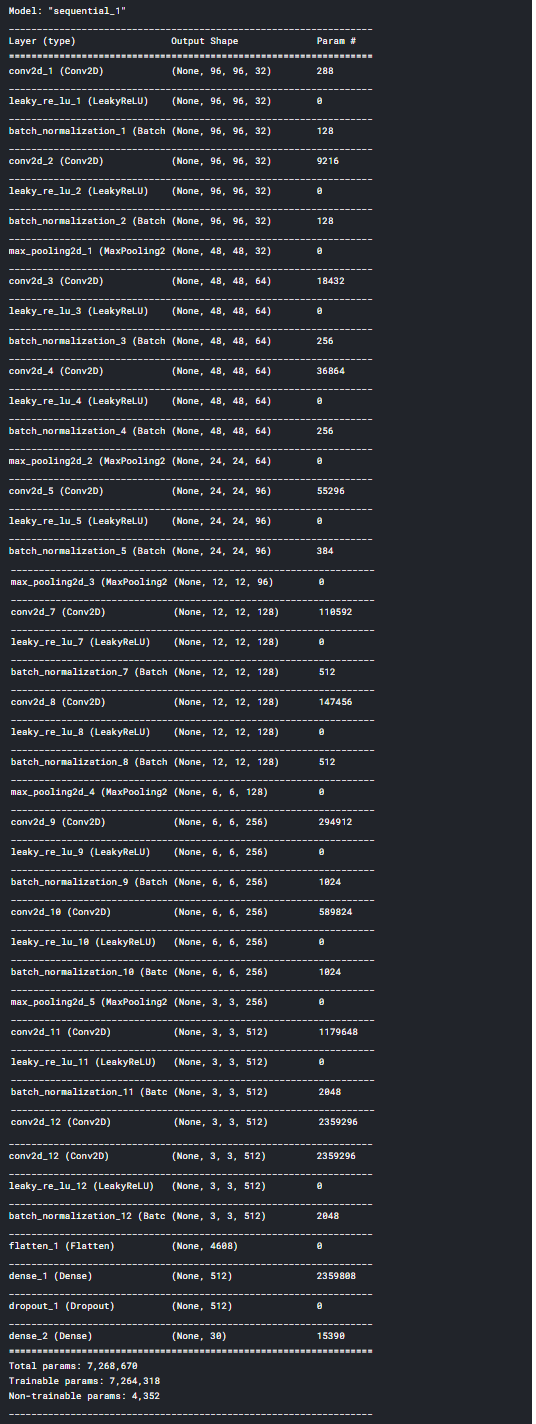
数据已经预处理完毕。现在是创建训练模型的时候了。为了创建我们的 CNN 模型,我们将使用 Keras 框架。from keras.models import Sequential, Model
from keras.layers import Activation, Convolution2D,MaxPooling2D,BatchNormalization, Flatten, Dense, Dropout
from keras.layers.advanced_activations import LeakyReLU
最初只从一两个 epoch 开始,以快速评估你的模型是如何训练的,并确定你是否应该改变其结构或超参数。在训练时跟踪模型的损失如何随时间变化:它是否首先快速减少,然后减速?在训练多个时期并创建最终模型之前,使用这些初始观察对模型进行更改并决定最佳架构。model = Sequential()
model.add(Convolution2D(32,(3,3),padding='same',use_bias=False, input_shape=(96,96,1)))
model.add(LeakyReLU(alpha = 0.1))
model.add(BatchNormalization())
model.add(Convolution2D(32,(3,3),padding='same',use_bias = False))
model.add(LeakyReLU(alpha=0.1))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Convolution2D(64,(3,3),padding='same',use_bias = False))
model.add(LeakyReLU(alpha=0.1))
model.add(BatchNormalization())
model.add(Convolution2D(64, (3,3), padding='same', use_bias=False))
model.add(LeakyReLU(alpha = 0.1))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(96, (3,3), padding='same', use_bias=False))
model.add(LeakyReLU(alpha = 0.1))
model.add(BatchNormalization())
model.add(Convolution2D(96, (3,3), padding='same', use_bias=False))
model.add(LeakyReLU(alpha = 0.1))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(128, (3,3),padding='same', use_bias=False))
# model.add(BatchNormalization())
model.add(LeakyReLU(alpha = 0.1))
model.add(BatchNormalization())
model.add(Convolution2D(128, (3,3),padding='same', use_bias=False))
model.add(LeakyReLU(alpha = 0.1))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(256, (3,3),padding='same',use_bias=False))
model.add(LeakyReLU(alpha = 0.1))
model.add(BatchNormalization())
model.add(Convolution2D(256, (3,3),padding='same',use_bias=False))
model.add(LeakyReLU(alpha = 0.1))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(512, (3,3), padding='same', use_bias=False))
model.add(LeakyReLU(alpha = 0.1))
model.add(BatchNormalization())
model.add(Convolution2D(512, (3,3), padding='same', use_bias=False))
model.add(LeakyReLU(alpha = 0.1))
model.add(BatchNormalization())
model.add(Flatten())
model.add(Dense(512,activation='relu'))
model.add(Dropout(0.1))
model.add(Dense(30))
model.summary()
下一步是配置模型:model.compile(optimizer='adam',loss='mean_squared_error',metrics=['mae','acc'])
model.fit(x_train,y_train,batch_size=256,epochs=45,validation_split=2.0)
示例输出:
在整个训练数据集中执行了总共 50 次迭代。我们已经学会了如何简单地使用 CNN 来训练深度学习模型。现在是时候使用我们的数据收集对模型进行测试了。我们必须首先准备我们的测试集。test_df.isnull().any()
x 测试:分离和重塑输入测试值image_df = test_df['Image']
keypoints_df = test_df.drop('Image',axis = 1)
imageArr = []
for i in range(0,len(image_df)):
img = image_df[i].split()
img = ['0' if x=='' else x for x in img]
imageArr.append(img)
x_test = np.array(imageArr,dtype='float')
x_test = x_test.reshape(-1,96,96,1)
print(x_test.shape)
我们知道要在测试数据集中分离目标值 (y_test)y_test = np.array(keypoints_df,dtype='float')
print(y_test.shape)
现在,是时候预测训练模型的结果了:pred = model.predict(x_test)
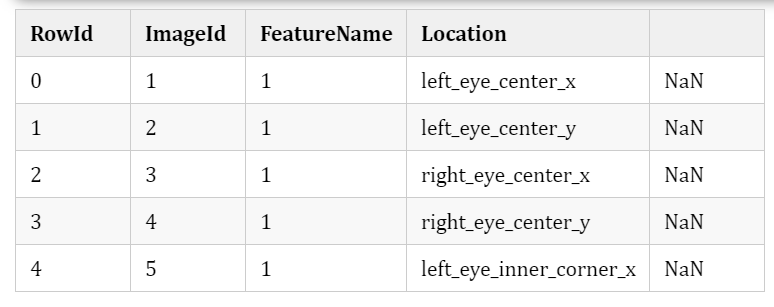
idLookupTable.head()
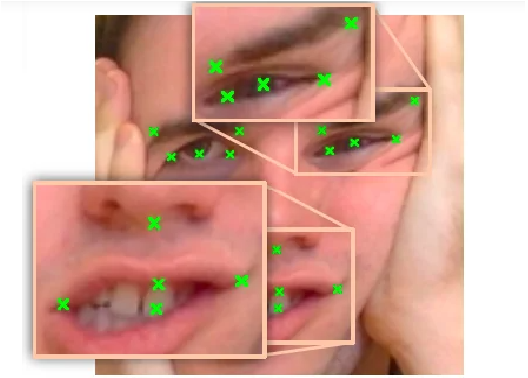
我们已经学习了如何简单地使用 CNN 构建深度学习面部关键点检测模型。
面部关键点检测的一些有用应用该技术的适用性是多种多样的。以下只是当今企业界中一些更有趣的面部识别应用。1) 使用 CNN 检测面部关键点并在带有面部过滤器的应用程序中使用它们用有趣的东西覆盖人脸照片的面部过滤器越来越受欢迎。它们通常出现在社交媒体平台上。此过滤器应用程序中使用了面部关键点(或“关键点”)检测技术。可以评估一个人的面部表情(以及情绪)的面部重要区域被称为面部关键点。它们对于开发实时应用程序以检测困倦、评估生物特征和读取人们的情绪至关重要。

2) 虚拟现实和增强现实 (AR)几个流行的智能手机应用程序中使用了面部关键点识别。Instagram、Snapchat 和 LINE 上的面部过滤器就是一些众所周知的例子。AR软件可以通过识别用户面部关键点,实时将图片滤镜正确叠加在用户面部上。
如果你是游戏或应用程序设计师,如果用户专注于将东西放置在靠近地板或桌子角落的地方,该算法的性能会好得多。由于这种架构,算法将始终在锚点附近发现足够多的关键点。3)Snap pay(无现金支付)

尽管在大多数国家/地区尚无法使用,但目前中国的大量零售商已接受面部识别支付。SnapPay 还宣布于 2019 年 10 月 16 日在北美推出面部识别支付技术。所有新兴国家都正在引入这种支付方式。4) 带面锁的防盗门安全门或门是该技术的另一个应用。面部识别技术可用于允许或拒绝进入你的公寓大楼、你公司的大堂,甚至火车站的检票口。虽然这项技术在其他国家没有广泛使用。