语音识别技术分享
金翅创客一
语音的识别过程
1
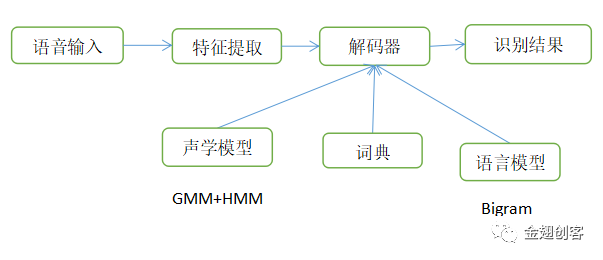
语音识别基本流程
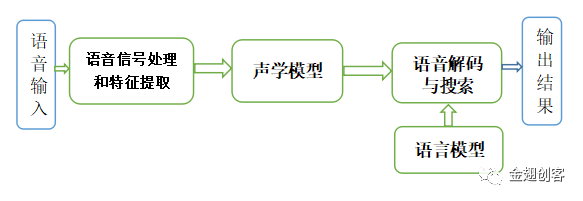
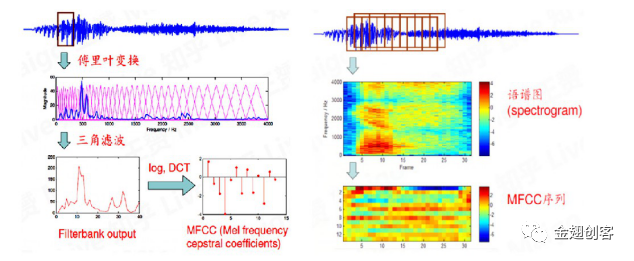
语音信号的特征提取:在开始语音识别之前,有时需要把首尾端的静音切除。接着对音频进行分帧。在语音识别中,常用25ms作为帧长。为了捕捉语音信号的连续变幻,避免帧之间的特征突变,每隔10ms取一帧,即帧移为10ms。工程上通常使用移动窗函数对语音进行分帧。对每一帧进行傅里叶变换转化成为语谱图。语谱图经过三角滤波器和MFCC变换,形成MFCC图。多帧的MFCC组合形成MFCC序列,这就是经过特征提取的特征序列。语音特征提取如下图所示。
2
语音识别的一般简单原理(基于贝叶斯定理)
(1) 假设Y是输入的音频信号,W是单词序列,在概率模型下公式表示为:
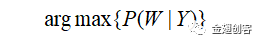
这就语音识别的目的公式。正常情况下,这个概率执行相当困难。我们可以采用贝叶斯定理对上述公式进行转换:
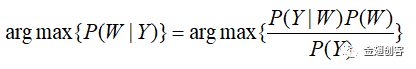
因为 P(Y)不会影响最终概率最大化,因此概率模型转变为arg max{P(Y|W)P(W)}。其中概率P(Y|W)的含义是,给定单词序列W,得到特定音频信号Y的概率,在语音识别系统中一般被称作声学模型。概率P(W)的含义是,给定单词序列W的概率,在语音识别系统中一般被称作语言模型。
(2) 对于声学特性来说,单词是一个比较大的建模单元,因此声学模型P(Y|W)中的单词序列W会进一步拆分成一个音素序列。通常情况下,一个音素包含很多帧。
二
经典的GMM-HMM模型
1
GMM-HMM产生过程
(1) 每一句话包含多个字或词,每一个字包含多个音素。一般情况下,英语的音素是辅音,元音等;汉语的音素是声母,韵母,声调。
(2) 初始,每一个特征序列都由许多帧构成。待识别语音的特征序列与已有模板的特征序列相匹配。帧与帧之间依据相似度进行对齐,然后使用DTW算法进行对齐即相似度匹配。例如下图所示。
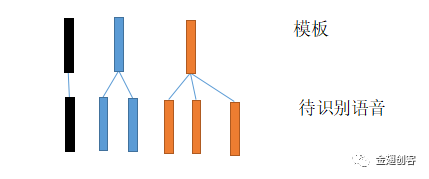
(1) 通常情况下,同一个字或词会依据人,环境等情况有多种声音波形,进而造成多种特征序列即模板。多个模板根据帧的相似性组成一个又一个的状态。然后使用混合高斯模型来拟合每一个状态的特征向量,通过计算概率密度来判断相似性,这就是观察概率。如下图所示,每一个圆圈所代表的就是一个状态,一个状态包含多个帧。混合高斯模型就是多个有不同均值和协方差的多元高斯模型混合在一起。

(2) 通常情况下,我们对音素进行建模。多个状态对应一个音素,多个音素对应一个字。对音素持续时间进行建模,增加了状态间的转移概率即该状态变为下一个状态的概率的大小。然后就形成了如下的GMM-HMM示意图。基本流程也同样会发生变化。
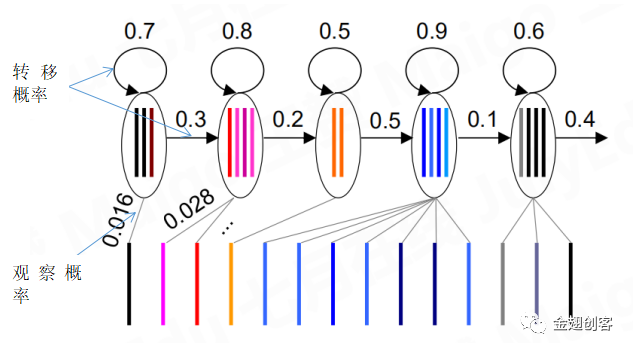
(3) 转移概率=转移到下一个状态+转移到自身的概率=1。最终声学模型概率的计算w = 观察概率*转移到下一个状态的概率*转移到自身状态的概率。每一个状态的转移概率和观察概率都由该状态自身决定。对于GMM-HMM模型的训练参数就是转移概率和观察概率的相关参数求解。待识别语音特征序列需要与状态进行对齐匹配。对齐匹配方式有很多种,优化参数的目的就是找到一种最恰当的对齐方式,使其计算概率最大。
(4) 优化参数的思路:先假设一种对齐方式,由此求出模型参数,然后更新对齐方式,循环直至收敛。
2
GMM-HMM基本模型
基本模型如下图所示。
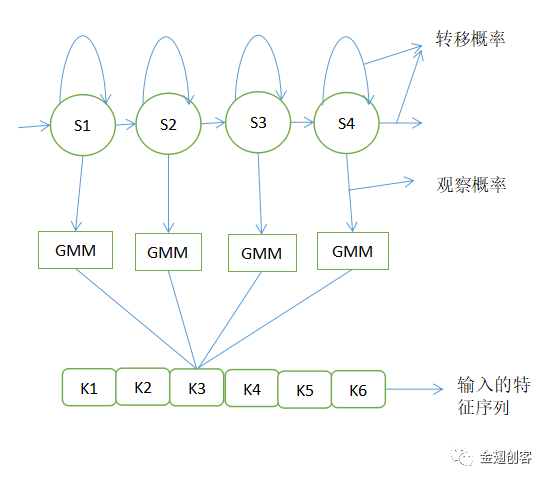
(1) GMM-HMM模型就组成了语音识别的声学模型。语言模型基于语料库使用马尔可夫模型进行建模。例如求句子“西安电子科技大学”的概率。

这就是语音模型的先验概率。语言模型的搭建依赖于语料库的字词句的丰富性。语料库越丰富,求出的概率越精确。这述所示例子使用了最常用的Bigram即每一个字只与前一个字有关。当然马尔可夫模型看似不精确,但是在实际实验还是很好用的。
(2) 图中S1,S2,S3,S4代表的是每一个HMM状态。上图只是一个HMM模型。一个HMM状态的参数由初始概率、转移概率和观察概率三部分构成。。初始概率对识别结果的影响很小,甚至有时可以忽略,且模型是单向的,所以初始概率不必考虑。声学模型包含的信息主要是状态定义和各状态的观察概率分布。对观察概率分布使用GMM建模就形成了GMM-HMM模型。基于神经网络的语音识别一般就是使用DNN模型取代GMM模型,进而形成DNN-HMM模型。
(3) 对每一个音素建立一个HMM模型。音素HMM按词典拼接成单词HMM,单词HMM与语言模型复合成语言HMM。通常情况下,单词的训练样本都是提前标注好的。当有了这些训练样本,就可以使用EM算法来训练GMM-HMM模型的全部参数。最终概率的计算依据arg max{P(Y|W)P(W)},识别结果 = 观测概率*转移概率*语言模型的先验概率。
(4) 解码的过程就是选择最佳的对齐方式。多个HMM状态组合成概率最大的音素、音素组成字、字组成句子,然后根据语言模型选择概率最大的字、词和句子。
三
端到端的语音识别
1
神经网络入局语音识别
神经网络开始进入到语音识别中。2012年,DNN取代了如人工特征提取方法MFCC,神经网络可以更好地提取特征。随着神经网络的发展,DNN取代了GMM模型,神经网络进一步发展。随着深度学习的发展,HMM模型被循环神经网络RNN取代。至此,GMM-HMM模型被取代,但是系统训练过程仍然需要GMM-HMM模型提供音素起止时间和标准答案。直至CTC、Transducer和注意力转移机制出现。
2
端到端语音识别框架
端到端语音识别框架是一种将输入的声学特征序列直接映射为字或词序列的系统。端到端语音识别技术目前主要分为:连接时序分类算法 (Connectionist Temporal Classification,CTC)、循环神经网络转换器算法 (Recurrent Neural Network Transducer,RNN-T) 和基于注意力 (Attention) 机制的编码-解码方法 (Encoder-Decoder)。
3
CTC、Transducer和注意力转移机制
(1) CTC解决的核心问题是输入序列与输出序列的对齐。对于语音识别,我们有一个声音片段和对应校正后的转写文本数据集。我们不知道如何将文字记录中的字符与音频对齐,这使得训练语音识别器比最开始想的看起来更难。连接时序分类(CTC)是一种不知道输入和输出之间的对齐方式。CTC模型引入了一种空符号,对于音素的输入只需要按顺序输出即可。实际上,大部分帧的输出都是空。基于CTC模型实现了端到端的输出。通俗来看,CTC就是一个目标函数。

