一文了解CUDA优化
计算机视觉编者荐语
CUDA 优化的最终目的是:在最短的时间内,在允许的误差范围内完成给定的计算任务。在这里,“最短的时间”是指整个程序运行的时间,更侧重于计算的吞吐量,而不是单个数据的延迟。在开始考虑使用 GPU 和 CPU 协同计算之前,应该先粗略的评估使用 CUDA 是否能达到预想的效果。
前言:
几个月前,我根据 Simoncelli 2016 年的论文编写了自己的自动编码器,用于研究目的。一开始,我想使用一些流行的深度学习框架(例如 Tensor Flow、Caffe2 或 MXNet)来做我的实验。然而,在对所有这些框架进行了几周的调查之后,我发现了一个非常令人头疼的问题——可扩展性。我不是说这些框架设计得不好,而是不允许用户开发第三方算子,就像写一个插件一样,你给我一个没有任何参数的函数。那么改变函数行为的唯一方法就是修改源代码,由于文档组织不善,这无疑是一个巨大的工程。(这似乎是开源软件的通病。)因此,由于不常见的算子 GDN 并未包含在所有这些框架中,因此设计一个新框架似乎是唯一的解决方案。
GDN
这个算子是这个理论中的核心非线性函数,表达式如下(公式不重要,如果你不喜欢这些该死的符号,你可以直接跳过这一节。):
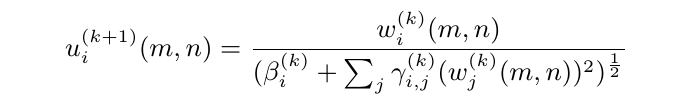
上标(k)和(k+1)表示层数,w和u是多通道图像的输入和输出,下标i是通道数。β 和 γ 是我要训练的参数。假设我们有 N 个通道,那么 γ 是一个 N × N 矩阵,β 是一个 N × 1 向量。乍一看,这个功能与 cudnn 和所有深度学习框架都很好地支持的批量归一化 (BN) 或局部响应归一化 (LRN) 非常相似。但相信我,不要让你的眼睛欺骗你。这是非常不同的。(注意大除法是元素除法。)
前向不会消耗太多计算能力,而后向会消耗我 GPU 的大部分能量。现在让我们看看后面。我需要计算 3 个梯度,?β、?γ 和 ?u。
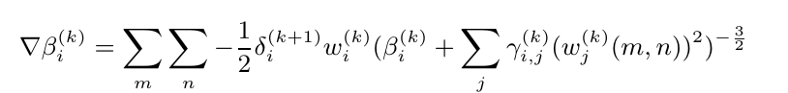
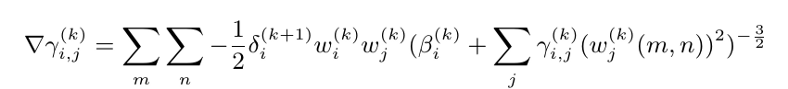
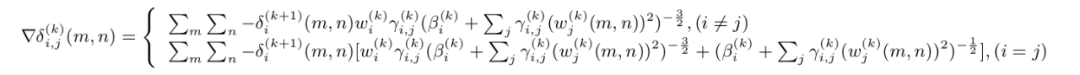
我知道人们第一次看到这个的感觉,因为我第一次看到这个怪物时也想自杀。 但如果我能为所有这些狗屎画一幅画,你会感觉更舒服。
首先,我们可以很容易地注意到输入可以看作是一个长度为 m x n 的向量。其次,(blabla...)^(-3/2) 出现在所有这些梯度中。这意味着我们可以只计算该术语 1 次,并将它们缓存以备后用。我们称其为“(blabla...)^(-1/2)”矩阵 D 。最后,δ 是传播到前一层的误差。
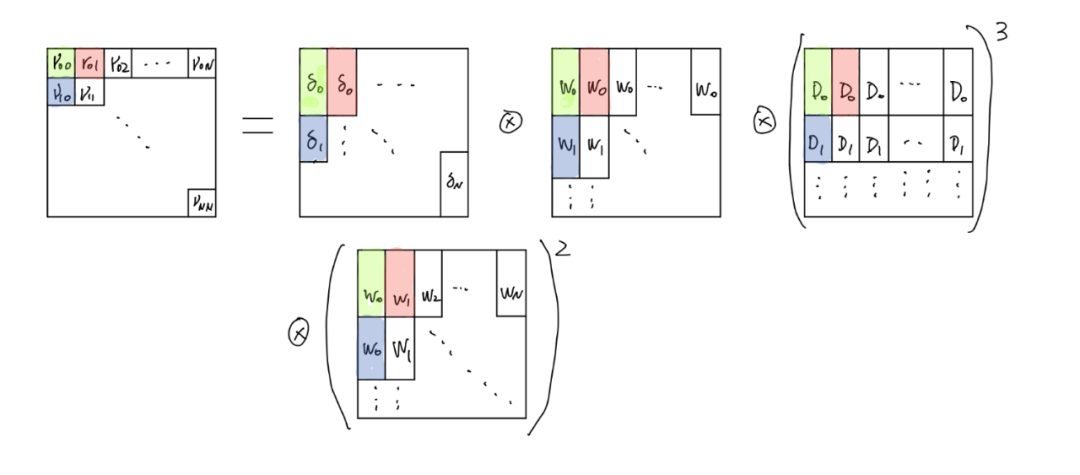
Fig 1. Computation of γ
经过一些简化,它更清楚了,对吧? 我知道仍然需要一些解释。 对于等式的右侧,每个矩形都是由我们上面提到的矩阵堆叠而成的向量。 D 是 GDN 公式中的分母项,还记得我们刚刚提到的“(blabla...)^(-1/2)”吗?
与一些高级算法不同,这种计算对大多数人来说非常直观,我们可以轻松编写 CPU 程序来处理它。只要稍微了解一下 CUDA,每个人都可以将他们的 CPU 代码移植到 GPU。但是,如果您可以选择不同的组织来启动内核,则速度会有很大的不同。
1. 不仅仅是天真的算法。
我称这种方法“不只是天真”是因为这是我用过的第一种方法。即使使用小尺寸图像作为输入,它也几乎耗尽了我所有的 GPU 内存,并实现了最慢的性能。没有利用任何内存重用,我只是垂直和水平复制所有这些小矩形以获得更大的矩阵,如下图所示,并启动许多一维组织的内核。然后将它们相加。
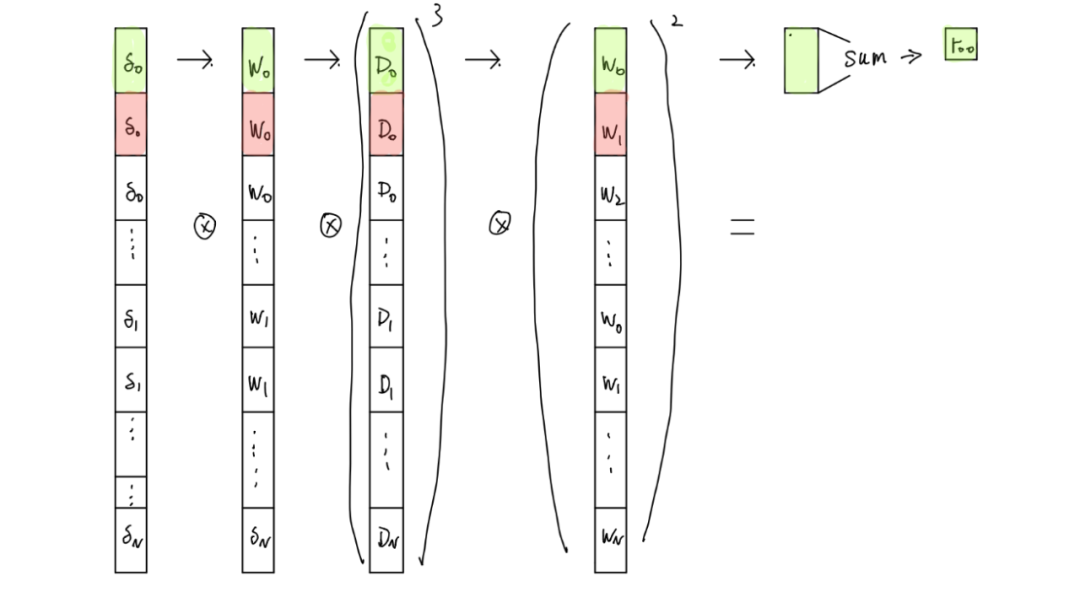
Fig 2. Less than naive Algo.
该算法唯一的优点是不需要在每个CUDA线程中计算索引,因为线程id只是唯一对应的内存索引。所以你需要做的就是一些乘法,然后使用 cublas 将每个小彩色矩形与 1 向量(一个充满所有 1 的向量)的点积相加。但是正如你所看到的,矩形的大小并不像我这里画的那么小,大小和图像一样。对于这张图片中的每个向量,大小将为 N x N x imageSize x batchSize。很明显,我们浪费了 (N-1) x N x imageSize x batchSize x 4 个字节,更不用说浪费在访问所有这些冗余全局内存上的时间了。
2. 朴素算法。
对于第一种算法,我每次迭代只能在我的网络中训练不到 4 张大小为 128 x 128 的图像,时间几乎为 2 秒。(我的 GPU 是 GTX 1080。)这个现实迫使我改进我的算法,否则,我必须等待近 2 个月才能得到我的结果。
因为我需要启动的内核数量肯定比我GPU中的CUDA内核多很多,所以不管我用什么方法,cuda驱动都会把这些任务序列化。然后我决定不复制所有这些记忆。相反,我将启动 N x 一维组织的 N x imageSize 内核 N 次(N 是通道总数)。
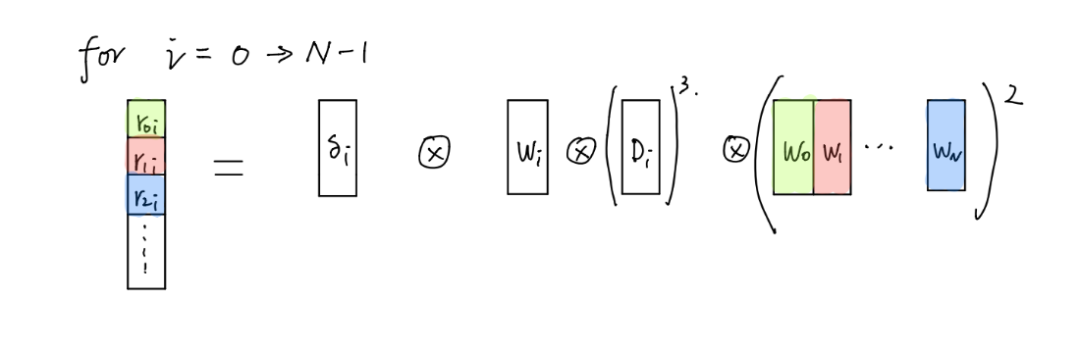
Fig 3. Without memory replication
可以看出,改进是显而易见的。因为,我们不再需要大量复制数据。 GPU 中的全局内存访问非常昂贵。内存访问模式也很简单,因为当您获得线程 id 时,只需使用一个 mod 操作就可以获得内存索引(内存索引 = 线程 id % imageSize)。但是,在这种方法中,由于内核仍然是一维组织的,并且我们使用for循环来启动所有这些内核,那么我们可能无法从GPU更智能的调度算法中受益,尽管我已经尝到了血的滋味.现在,通过这个小小的改变,2 个月的训练时间可以缩短到将近 2 周。
3. 更智能的组织算法。
到目前为止,我还没有考虑过共享内存的威力,因为对我来说,通常设计一个好的内核模式是枯燥和头痛的。显然,一维内核模式是最容易编写的代码。然而,更好的性能值得更仔细的设计。令我惊讶的是,本节中的算法实现了第二个算法的 3 倍速度。
回到图 1,可以看到前 3 个右侧矩阵的第一行 δ0、w0 和 D0 是相同的。因此,我们可以在一个块中计算一行 γ,对于每个块我们可以启动 imageSize 个线程,并且对于每个线程我们可以使用 for 循环计算所有通道。
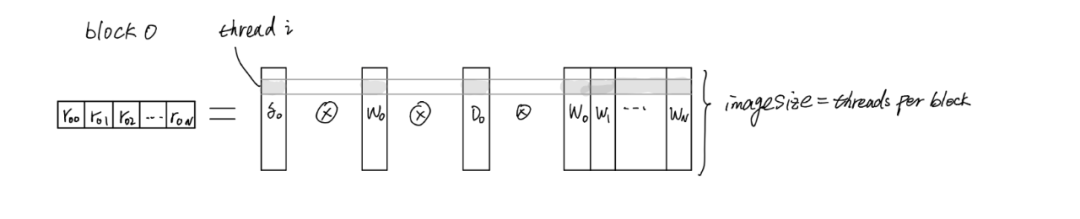
Fig 5. Computation in one block
所以从图 5 来看,将 δ0、w0 和 D0 放在共享内存中是非常直观的,而对于线程 i,它从 0 到 N-1 读取 N 个通道中的一个像素与 δ0、w0 和 D0 相乘 分享回忆。伪代码如下:
blockId = blockIdx.x;
threadId = threadIdx.x;shareDelta <- delta[blockId];
shareW <- W[blockId];
shareD <- D[blockId];
_synchronize();for(i = 0; i < N-1; i++)
{
result[threadIdx i*imgSize] = shareDelta[threadId] *
shareW[threadId] *
shareD[threadId] *
W[threadId + i*imgSize];
}
Algo 2 选择行主计算而不是列主计算是因为在一个网格中计算一行,我们可以共享 3 个向量 δ0、w0 和 D0。但是如果我们像在 Algo 中那样计算一列,我们只能共享 1 个向量 w0。(再次参见图 1。)。
在这段代码片段中,没有 if ... else ... 块。这在并行计算中非常重要。因为所有线程都是并行运行的,理想的情况是所有这些线程同时完成它们的工作。但是如果有 if ... else ... 阻塞,分支会让这些线程做不同的任务,以便它们在不同的时间完成。然后计算时间将由最慢的线程决定。
无索引计算也是一个优势。通过设计一维模式,我们必须使用线程id来计算内存索引,但这里不需要将blockId和threadId转换为一维内存索引来访问数据。
最后,因为我的数据存储在列major中,这意味着,像向量δ0一样,这个向量中的所有元素都是连续存储的。所以它受益于全局内存合并机制。全局内存也是cuda中的一个重要概念。
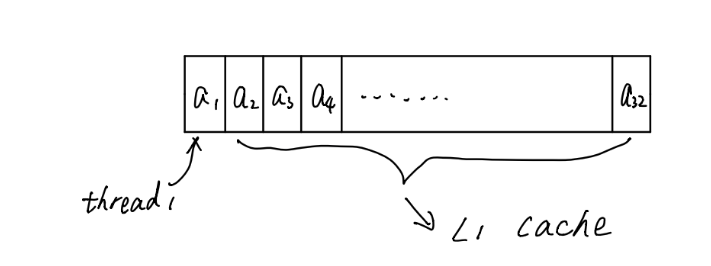
在硬件方面,16个cuda内核被组织在一个warp中。当其中一个线程访问数据时,例如上图中的 a1,数据总线不仅会传输 a1,还会将 a1~a32 传输到缓存中,以加速其他 15 个内核的数据访问。因此,当我读取全局数据以共享内存时,每 32 个字节我只读取一次,所有其他字节都从缓存中读取,速度快了数百。多亏了时空局域性理论。
4. 多一点改进
今天突然发现其实我不需要共享内存,但是可以使用const内存。因为对于向量δ0、w0和D0,一个block中的每个线程只需要访问一次。所以在for循环之前,我们实际上可以将元素缓存在const内存中。另一个糖是因为每个线程只访问一个元素,不需要线程同步。
代码如下:
blockId = blockIdx.x;
threadId = threadIdx.x;const float constDelta = delta[blockId * imgSize + threadId];
const float constW = W[blockId * imgSize + threadId];
const float constD = D[blockId * imgSize + threadId];for(i = 0; i < N-1; i++)
{
result[threadIdx + i*imgSize] = constDelta * constW *
constD *
W[threadId + i*imgSize];
}
从上面的代码可以看出,constDelta、constW、constD可以从本地内存中重复使用N次,本地内存总是存储在本地寄存器中。因此,带宽大于共享内存。
Reduce Operation
我讲的所有算法都没有完成,因为我从上述算法中得到的实际上都是原始γ,如下所示:
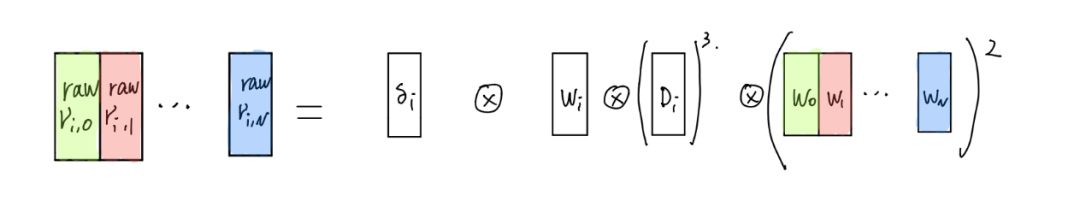
我需要在左侧累积每个向量以获得一个元素。第一个选择是 cublas API,cublasSsbmv。此函数将进行矩阵向量乘法。所以我们可以把左边的向量看成一个矩阵,将它与一个全1向量相乘,得到γ的一行梯度。并重复N次以获得最终结果。但我注意到还有其他 API cublasSgemmBatched。此函数可以进行批量矩阵向量乘法。然后我做了一个实验来测试哪个更快:
N 个矩阵向量乘法 VS 批处理矩阵向量乘法的 for 循环。
结果表明for循环要快得多。但是我不知道原因,也许是因为我这里的 N 太小(N = 256)。
我不会展示如何计算 ?β 和 ?u,因为它们类似于 ?γ。我知道必须有比我更进一步的优化或更好的设计。CUDA 优化对于不深入了解 GPU 组织的人来说通常是困难的。熟悉 CPU 的程序员总是受益于现代操作系统和强大的编译器。然而,GPU 在编写足够的代码方面与 CPU 有很大不同和复杂性,尽管它比以前使用图形着色器进行计算要方便得多。生态环境的完善还需要几年时间。
