计算机视觉检测车牌号
磐创AI介绍
在这个技术飞速发展的时代,在寻找一辆犯罪汽车的时候,要停下路上的每一辆车并检查其车牌是非常困难的。随着道路欺诈的增加,警察也变得越来越聪明。他们正在使用深度学习和计算机视觉来检测车牌并从中提取车牌号。今天,我们将建立一个这样的项目,使用计算机视觉来检测车牌,这有助于电子挑战和安全监控。在本博客中,我们将学习如何使用计算机视觉检测汽车的车牌并提取其值。我们将使用计算机视觉的 OpenCV 库来检测汽车的车牌,使用深度学习的 pytesseract 库来读取图像类型并从车牌中获取字符和数字。最后,我们使用 Tkinter 构建一个图形用户界面来显示我们的项目。
计算机视觉的先决条件
首先,安装库:
pip3 install OpenCV-python
pip3 install pytesseract
什么是 OpenCV?
OpenCV 是一个巨大的开源跨平台库,它使计算机视觉能够执行自动驾驶、图像注释、基于无人机的作物监测等实际应用。它主要专注于捕获图像和视频以分析重要特征,例如物体检测、人脸检测、情绪检测等,在基于图像处理的人工智能应用中也发挥着重要作用。
在这里,我们只是使用 openCV 的一些基本特征/功能来识别输入的汽车图像中的车牌号。
· 轮廓:轮廓通常被视为边界像素,因为它们只是简单的曲线,将边界中具有相同强度和颜色的所有连续点组合在一起。轮廓的使用在形状分析、对象检测和识别、运动检测以及背景/前景图像分割中更加清晰。为了减少轮廓检测的任务,OpenCV 为此提供了内置的 cv2.findContours() 函数。
cv2.findContours(morph_img_threshold,mode=cv2.RETR_EXTERNAL,method=cv2.CHAIN_APPROX_NONE)
我们的 cv.find contours()函数采用三个参数,包括输入图像、轮廓检索模式,最后是轮廓逼近方法。该函数以 Python 列表的形式生成修改后的图像、层次结构和轮廓。
· 形态变换:是指只对二值图像进行的一些简单的操作,并依赖于图像的形状。一些常见的形态学操作是 Opening、Closing、Erosion、Dilation。每个函数都有两个参数,包括输入图像和结构元素或内核来决定操作的性质。OpenCV 提供了一些内置函数来执行这些操作:
· cv2.erode()
· cv2.dilate()
· cv2.morphologyEx()
· **高斯模糊:**高斯函数用于对输入图像进行模糊和平滑处理,并输出高斯模糊图像。它被广泛用于减少图像噪声效果。OpenCV 为此提供了一个内置函数 cv2.GaussianBlur()。
· **Sobel:**此函数用于计算图像导数,这反过来有助于梯度的计算。OpenCV 为此提供了一个内置函数 cv2.Sobel()。
使用计算机视觉构建车牌的步骤步骤
1. 导入必要的库
import numpy as np
import cv2
from PIL import Image
import pytesseract as pytess
步骤 2. 识别不必要的轮廓
现在我们将专注于识别图片中存在的一些不必要的轮廓,这些轮廓可能会被 OpenCV 错误识别,因为它是车牌的可能性很小。
我们将定义三个不同的函数来找到这些轮廓。
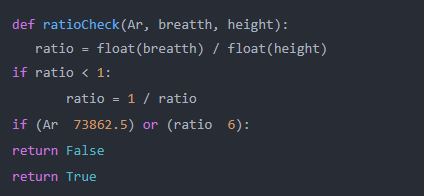
1. 首先,我们创建一个名为“ratioCheck”的函数来识别面积范围和宽高比。
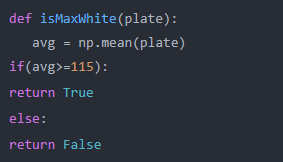
2. 其次,我们创建一个名为“isMaxWhite”的函数来识别图像矩阵的平均值:
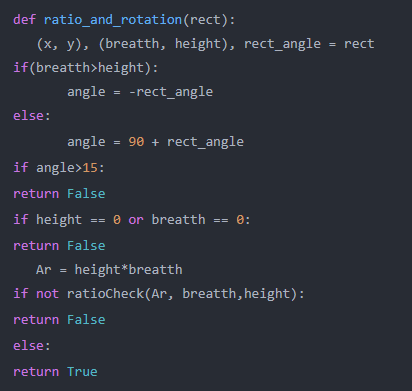
3. 最后,我们创建一个名为“ratio_and_rotation”的函数来查找轮廓的旋转:
步骤 3 清理识别的车牌
现在我们的任务是创建一个函数,通过删除所有不必要的元素来准备用于预处理的车牌,并使图像准备好提供给 pytesseract:
def clean2_plate(plate):
gray_img = cv2.cvtColor(plate, cv2.COLOR_BGR2GRAY)
_, thresh_val = cv2.threshold(gray_img, 110, 255, cv2.THRESH_BINARY)
if cv2.waitKey(0) & 0xff == ord('q'):
pass
num_contours,hierarchy = cv2.findContours(thresh_val.copy(),cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
if num_contours:
conto_ar = [cv2.contourArea(c) for c in num_contours]
max_cntr_index = np.argmax(conto_ar)
max_cnt = num_contours[max_cntr_index]
max_cntArea = conto_ar[max_cntr_index]
x,y,w,h = cv2.boundingRect(max_cnt)
if not ratioCheck(max_cntArea,w,h):
return plate,None
final_img = thresh_val[y:y+h, x:x+w]
return final_img,[x,y,w,h]
else:
return plate, None
第 4 步识别数字和字符
现在我们的任务是以图像的形式获取用户输入。然后,我们将执行三个讨论过的 cv2 函数:Gaussian Blur、Sobel 和形态学运算并识别图像轮廓,并从每个轮廓中找到循环来识别车牌。最后,将使用 pytesseract 库并为其提供图像以提取数字和字符。
img = cv2.imread("testData/img1.jpg")
print("Number input image...",)
cv2.imshow("input",img)
if cv2.waitKey(0) & 0xff == ord('q'):
pass
img2 = cv2.GaussianBlur(img, (3,3), 0)
img2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
img2 = cv2.Sobel(img2,cv2.CV_8U,1,0,ksize=3)
_,img2 = cv2.threshold(img2,0,255,cv2.THRESH_BINARY+cv2.THRESH_OTSU)
element = cv2.getStructuringElement(shape=cv2.MORPH_RECT, ksize=(17, 3))
morph_img_threshold = img2.copy()
cv2.morphologyEx(src=img2, op=cv2.MORPH_CLOSE, kernel=element, dst=morph_img_threshold)
num_contours, hierarchy= cv2.findContours(morph_img_threshold,mode=cv2.RETR_EXTERNAL,method=cv2.CHAIN_APPROX_NONE)
cv2.drawContours(img2, num_contours, -1, (0,255,0), 1)
for i,cnt in enumerate(num_contours):
min_rect = cv2.minAreaRect(cnt)
if ratio_and_rotation(min_rect):
x,y,w,h = cv2.boundingRect(cnt)
plate_img = img[y:y+h,x:x+w]
print("Number identified number plate...")
cv2.imshow("num plate image",plate_img)
if cv2.waitKey(0) & 0xff == ord('q'):
pass
if(isMaxWhite(plate_img)):
clean_plate, rect = clean2_plate(plate_img)
if rect:
fg=0
x1,y1,w1,h1 = rect
x,y,w,h = x+x1,y+y1,w1,h1
# cv2.imwrite("clena.png",clean_plate)
plate_im = Image.fromarray(clean_plate)
text = tess.image_to_string(plate_im, lang='eng')
print("Number Detected Plate Text : ",text)
项目 GUI 代码
现在我们将为图形用户界面创建一个名为“gui.py”的 python 文件,以创建一个接受图像作为输入并在屏幕上输出车牌号的web表单。
import tkinter as tk #python library for GUI
from tkinter import filedialog
from tkinter import *
from PIL import ImageTk, Image
from tkinter import PhotoImage
import numpy as np
import cv2
import pytesseract as tess
def clean2_plate(plate):#to clean the identified number plate using above discussed openCV methods
gray_img = cv2.cvtColor(plate, cv2.COLOR_BGR2GRAY)
_, thresh_val = cv2.threshold(gray_img, 110, 255, cv2.THRESH_BINARY)
num_contours,hierarchy = cv2.findContours(thresh_val.copy(),cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
if num_contours:
conto_ar = [cv2.contourArea(c) for c in num_contours]
max_cntr_index = np.argmax(conto_ar)
max_cnt = num_contours[max_cntr_index]
max_cntArea = conto_ar[max_cntr_index]
x,y,w,h = cv2.boundingRect(max_cnt)
if not ratioCheck(max_cntArea,w,h):
return plate,None
final_img = thresh_val[y:y+h, x:x+w]
return final_img,[x,y,w,h]
else:
return plate,None
#method to identify the range of area and ratio between width and height
def ratioCheck(Ar, breatth, height):
ratio = float(breatth) / float(height)
if ratio < 1:
ratio = 1 / ratio
if (Ar 73862.5) or (ratio 6):
return False
return True
#method to identify average of image matrix:
def isMaxWhite(plate):
avg = np.mean(plate)
if(avg>=115):
return True
else:
return False
# to find the rotation of contours:
def ratio_and_rotation(rect):
(x, y), (breatth, height), rect_angle = rect
if(breatth>height):
angle = -rect_angle
else:
angle = 90 + rect_angle
if angle>15:
return False
if height == 0 or breatth == 0:
return False
Ar = height*breatth#area calculation
if not ratioCheck(Ar,breatth,height):
return False
else:
return True
top=tk.Tk()
top.geometry('900x700')#window size
top.title('Number Plate Recognition')#title of GUI
top.iconphoto(True, PhotoImage(file="/home/shikha/GUI/logo.png"))#give the path of folder where your test image is available
img = ImageTk.PhotoImage(Image.open("logo.png"))#to open your image
top.configure(background='#CDCDCD')#background color
label=Label(top,background='#CDCDCD', font=('arial',35,'bold'))#to set background,font,and size of the label
sign_image = Label(top,bd=10)
plate_image=Label(top,bd=10)
def classify(file_path):
res_text=[0]
res_img=[0]
img = cv2.imread(file_path)
img2 = cv2.GaussianBlur(img, (3,3), 0)
img2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
img2 = cv2.Sobel(img2,cv2.CV_8U,1,0,ksize=3)
_,img2 = cv2.threshold(img2,0,255,cv2.THRESH_BINARY+cv2.THRESH_OTSU)
element = cv2.getStructuringElement(shape=cv2.MORPH_RECT, ksize=(17, 3))
morph_img_threshold = img2.copy()
cv2.morphologyEx(src=img2, op=cv2.MORPH_CLOSE, kernel=element, dst=morph_img_threshold)
num_contours, hierarchy= cv2.findContours(morph_img_threshold,mode=cv2.RETR_EXTERNAL,method=cv2.CHAIN_APPROX_NONE)
cv2.drawContours(img2, num_contours, -1, (0,255,0), 1)
for i,cnt in enumerate(num_contours):
min_rect = cv2.minAreaRect(cnt)
if ratio_and_rotation(min_rect):
x,y,w,h = cv2.boundingRect(cnt)
plate_img = img[y:y+h,x:x+w]
print("Number identified number plate...")
res_img[0]=plate_img
cv2.imwrite("result.png",plate_img)
#method to identify average of image matrix:
if(isMaxWhite(plate_img)):
clean_plate, rect = clean2_plate(plate_img)
if rect:
fg=0
x1,y1,w1,h1 = rect
x,y,w,h = x+x1,y+y1,w1,h1
plate_im = Image.fromarray(clean_plate)
text = tess.image_to_string(plate_im, lang='eng')
res_text[0]=text
if text:
break
label.configure(foreground='#011638', text=res_text[0])
uploaded=Image.open("result.png")
im=ImageTk.PhotoImage(uploaded)
plate_image.configure(image=im)
plate_image.image=im
plate_image.pack()
plate_image.place(x=560,y=320)
def show_classify_button(file_path):
classify_b=Button(top,text="Classify Image",command=lambda: classify(file_path),padx=10,pady=5)
classify_b.configure(background='#364156', foreground='white',font=('arial',15,'bold'))
classify_b.place(x=490,y=550)
def upload_image():
try:
file_path=filedialog.askopenfilename()
uploaded=Image.open(file_path)
uploaded.thumbnail(((top.winfo_width()/2.25),(top.winfo_height()/2.25)))
im=ImageTk.PhotoImage(uploaded)
sign_image.configure(image=im)
sign_image.image=im
label.configure(text='')
show_classify_button(file_path)
except:
pass
upload=Button(top,text="Upload an image",command=upload_image,padx=10,pady=5)
upload.configure(background='#364156', foreground='white',font=('arial',15,'bold'))
upload.pack()
upload.place(x=210,y=550)
sign_image.pack()
sign_image.place(x=70,y=200)
label.pack()
label.place(x=500,y=220)
heading = Label(top,image=img)
heading.configure(background='#CDCDCD',foreground='#364156')
heading.pack()
top.mainloop()
计算机视觉输出


结论在这篇博客中,我们使用计算机视觉和深度学习来创建一个车牌识别和牌照号码提取系统。在这里,我们创建了一个 GUI 来上传车辆的图像并识别编号。我们主要关注两个库:OpenCV 来清理车牌, pytesseract 识别车牌数字和字符。我们还学习了 OpenCV 的一些特殊功能,即形态变换、高斯模糊和 Sobel 算子。
