人脸识别技术哪家强?OPPO专利解读:多帧超分与深度学习结合提升精度
德高行知情郎
知情郎·眼|
侃透天下专利事儿
聊过指纹识别、虹膜识别。
今天说人脸识别技术哪家强!
国内做人脸识别的科技公司不少。
在市场上名气比较大的如炒作了N年的AI四小龙商汤科技、旷视科技、依图科技、云从科技。
当年都打出过人脸识别国内第一的技术营销牌!
百度智能云、阿里云、腾讯云这些大平台就更不用说了,你点开阿里云,搜索人脸识别,就会跳出相关人脸识别服务,支持SDK调用,用起来很方便!
不过,从德高行全球专利数据库检索的结果看,国内跟人脸识别有关联度的专利量,OPPO排第一!
之后浅析下OPPO的人脸识别专利布局。
从指纹识别、虹膜识别到人脸识别,OPPO做的工作真不少,至少,从专利量角度而言,人家还真跟生物识别技术杠上了。

01科普人脸识别
人脸上的眼睛、鼻子、嘴巴、眉毛等,既是人们的共性,同时也是区分个体的关键(因为其大小、形状等不尽相同)。
我们经常用面部的特征来描述个体,机器同样也可以做这件事。

机器通过对图像处理,得到对这些图像的集合特征描述(比如根据你的鼻子的显著特点导出一组用于识别的特征度量如距离、角度等)
比较普遍的就是特征脸法,搜集大量的图像进行分析,寻找人脸图像分布的基本元素,即人脸图像样本集协方差矩阵的特征向量,以此近似地表征人脸图像。
简单解释下,通过机器人脸检测,可以从一幅幅图像中提取出人脸区域。
但是想进一步了解人脸的信息,就需要人脸特征点定位,每个人的脸型轮廓、五官特征点是不同的,所以大家的特征点连接起来后也是不同的。
哪怕是整容了,也很难改变连接起来的整体特征点。
人脸识别,就是基于人的脸部特征信息进行身份识别的一种生物识别技术。
02整容脸会否影响人脸识别?
很多网友会问?一个人脸部多处整容,在机场人脸识别安检中会否过不去?
知情郎也很好奇答案。
自从韩国女子整容潮风靡国内后,电视机里都是蛇精脸~
从大V们在行业技术论坛的交流结果来看,确实会有影响。
如果只是脸部发福变胖,脸部特征对称点不变,没什么影响。
但如果对轮廓线做了改变,如削下巴、动眼睛、整鼻子就要小心。
尤其鼻子整容将鼻梁彻底变了,开眼角拉眼皮,尤其还只对一只眼睛做整形,这会让五官特征点大变样,两只眼还不对称,这些都会影响AI的人脸识别判断。
这些交流内容,也把知情郎看笑了。
人脸识别,最有意思的也是特征点定位。
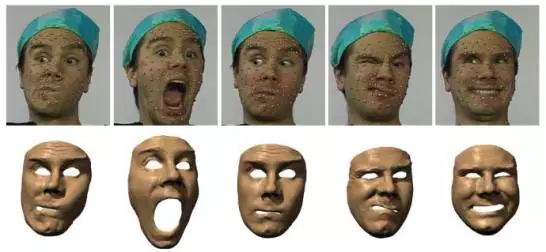
人脸特征点定位是一种利用计算机分析人脸图像,从而获得诸如眼睛、鼻尖、嘴角点、眉毛以及人脸各部件轮廓点等等一些重要的特征点位置的技术,如下图所示。

04人脸特征点定位的应用领域
人脸特征点定位应用在很多环节。
1、人脸检测:人脸特征点的位置信息可以在人脸检测中定位人脸、验证人脸检测的结果以及精确指明人脸位置。

2、人脸识别:即人脸特征点的结果。

3、姿态估计和凝视方向分析:在头部姿态及定位提供的几何特征等是人脸识别的重要信息,在人脸识别过程中一项重要工作就是人脸对齐,这主要依赖于人脸特征点定位人脸表情分析中,可以通过对五官的相对位置及形状进行分析确定,人脸特征定位是姿态估计和表情分析的前提。

4、疲劳度检测:人体的疲劳度会体现在人脸上,例如眨眼、打哈欠,通过人脸特征点定位可以进行分析。
5、三维人脸动画合成:比如微软开发的可供用户体验的基于正面人脸特征点定位的卡通画生成系统CartoonMaker。
上述都是技术论坛行业工程师日常讨论的东西,且现在美颜相机那么厉害,P图狂人能活活把任何一女子照片美化成绝世美人,所以不是摄像头实时视频拍摄的图片,经常出现识别错误的情况。
05技术发展历史
传统的人脸识别技术主要是基于可见光图像的人脸识别,这也是人们熟悉的识别方式,已有30多年的研发历史。
但这种方式有着难以克服的缺陷,尤其在环境光照发生变化时,识别效果会急剧下降,无法满足实际系统的需要。
解决光照问题的方案有三维图像人脸识别,和热成像人脸识别。但这两种技术还远不成熟,识别效果不尽人意。
迅速发展起来的一种解决方案是基于主动近红外图像的多光源人脸识别技术。
它可以克服光线变化的影响,已经取得了卓越的识别性能,在精度、稳定性和速度方面的整体系统性能超过三维图像人脸识别。
这项技术使人脸识别技术逐渐走向实用化。
06人脸识别算法分类
人脸识别技术的核心是算法,比较知名的基础性算法有三种。
1 特征脸法(Eigenface)
特征脸技术是近期发展起来的用于人脸或者一般性刚体识别以及其它涉及到人脸处理的一种方法。
该方法首先由Sirovich和Kirby(1987)提出(《Low dimensional procedure for the characterization of human faces》),并由MatthewTurk和AlexPentland用于人脸分类(《Eigen faces for recognition》)。
首先把一批人脸图像转换成一个特征向量集,称为“Eigenfaces”,即“特征脸”,它们是最初训练图像集的基本组件。识别的过程是把一副新的图像投影到特征脸子空间,并通过它的投影点在子空间的位置以及投影线的长度来进行判定和识别。
将图像变换到另一个空间后,同一个类别的图像会聚到一起,不同类别的图像会聚力比较远,在原像素空间中不同类别的图像在分布上很难用简单的线或者面切分,变换到另一个空间,就可以很好的把他们分开了。
Eigenfaces选择的空间变换方法是PCA(主成分分析),利用PCA得到人脸分布的主要成分,具体实现是对训练集中所有人脸图像的协方差矩阵进行本征值分解,得到对应的本征向量,这些本征向量就是“特征脸”。
每个特征向量或者特征脸相当于捕捉或者描述人脸之间的一种变化或者特性。这就意味着每个人脸都可以表示为这些特征脸的线性组合。
2 局部二值模式(Local Binary Patterns,LBP)
局部二值模式是计算机视觉领域里用于分类的视觉算子。
LBP一种用来描述图像纹理特征的算子,该算子由芬兰奥卢大学的T.Ojala等人在1996年提出(《A comparative study of texture measures with classification based on featured distributions》)。
2002年,T.Ojala等人在PAMI上又发表了一篇关于LBP的文章(《Multi resolution gray-scale and rotation in variant texture classification with local binary patterns》)。
这一文章非常清楚的阐述了多分辨率、灰度尺度不变和旋转不变、等价模式的改进的LBP特征。
LBP的核心思想就是:以中心像素的灰度值作为阈值,与他的领域相比较得到相对应的二进制码来表示局部纹理特征。
LBP是提取局部特征作为判别依据的。LBP方法显著的优点是对光照不敏感,但是依然没有解决姿态和表情的问题。不过相比于特征脸方法,LBP的识别率已经有了很大的提升。
3 Fisherface
线性鉴别分析在降维的同时考虑类别信息,由统计学家SirR.A.Fisher1936年发明
(《THE USE OF MULTIPLE MEASUREMENTS IN TAXONOMIC PROBLEMS》)。
为了找到一种特征组合方式,达到最大的类间离散度和最小的类内离散度。
这个想法很简单:在低维表示下,相同的类应该紧紧的聚在一起,而不同的类别尽量距离越远。
1997年,Belhumer成功将Fisher判别准则应用于人脸分类,提出了基于线性判别分析的Fisherface方法(《Eigenfaces vs. Fisherfaces: Recognition Using Class Specific Linear Projection 》)。
知情郎就不展开具体的算法描述,网上技术论坛有大牛们的交流解读,一堆密密麻麻的数据公式,看的脑壳疼,也不看懂。
整体来说,目前人脸识别的算法分为以下几种:
1、基于人脸特征点的识别算法(Feature-based recognition algorithms)。
2、基于整幅人脸图像的识别算法(Appearance-based recognition algorithms)。
3、基于模板的识别算法(Template-based recognition algorithms)。
4、利用神经网络进行识别的算法(Recognition algorithms using neural network)。
5、基于光照估计模型理论
提出了基于Gamma灰度矫正的光照预处理方法,并且在光照估计模型的基础上,进行相应的光照补偿和光照平衡策略。
6、优化的形变统计校正理论
基于统计形变的校正理论,优化人脸姿态;
7、强化迭代理论
强化迭代理论是对DLFA人脸检测算法的有效扩展;
8、实时特征识别理论
该理论侧重于人脸实时数据的中间值处理,从而可以在识别速率和识别效能之间,达到最佳的匹配效果。
07国内哪些玩家技术储备深?
以脸部识别为关键词,在德高行全球专利数据库检索得出,国内相关专利申请人排名如下
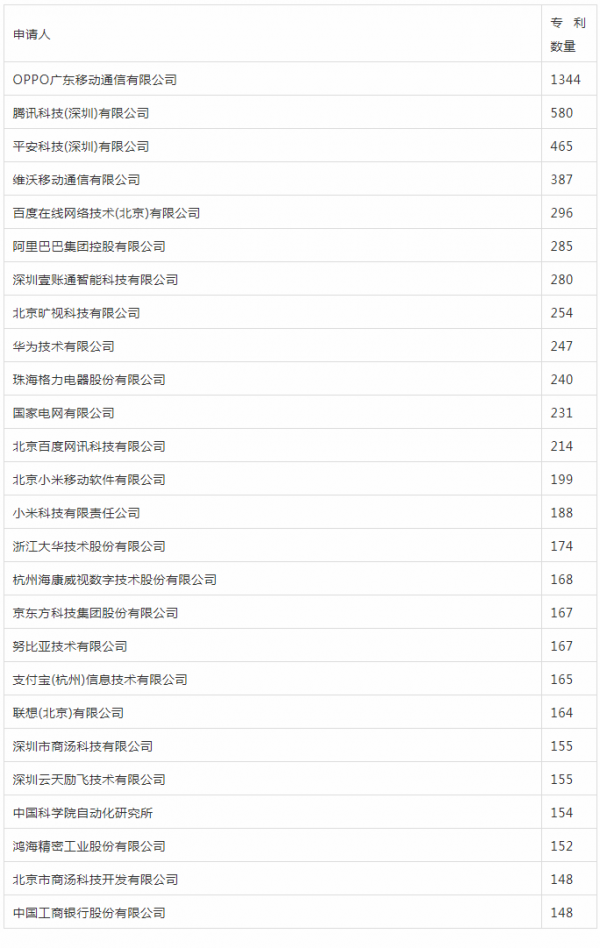
整体看,国内脸部识别专利主要分布在硬件、应用领域,至于脸部识别算法的反而不是最多的。
这也符合实际情况,行业经典算法都来自于国外大牛的研究。
OPPO在指纹识别、虹膜识别领域专利排第一,在脸部识别领域,专利量依然排第一。
这结果出乎知情郎意料之外,AI四小龙的旷视科技排第9,商汤科技不同企业主体分列22位、26位。
快速扫了上百个OPPO的脸部识别关联专利。
大量专利都围绕如何局性提高人脸识别效率展开,从环境采光、图片压缩方式、面部三维特征提取、特征匹配算法、硬件摄像头自拍、面部识别启动条件设置等多维度布局。
有意思的是,OPPO大量的人脸识别关联专利用在了滤镜美颜功能上,尤其在图像处理上,第一用处不是特征提取识别,而是为了美颜,祛除图像里的瑕疵斑点,让照片人的皮肤变美!
在基础性、根本性的算法上,没看到OPPO的贡献,至少,专利层面没看到类似讲述。
咋说呢?
OPPO的这些专利相对简单......
08OPPO人脸识别专利解读

技术背景介绍
人脸识别是基于人的脸部特征信息进行身份识别的一种生物识别技术,用摄像装置采集含有人脸的图像,并在图像中检测,进而对检测到的人脸进行脸部识别,也可以称之为人像识别、面部识别。
然而,在图像中人脸较小或成像质量较差时,会降低人脸识别精度。
OPPO工程师提供了一种人脸识别方法,以提高人脸识别精度。
09步骤一 双线性插值处理数字图像
不废话,看工程师的流程设计思路!
1、获取针对目标人脸的连续N帧初始图像。
N的取值范围为[3,16],在N的取值范围为[3,16]时,移动终端在人脸识别过程中的运算量增长程度与人脸识别精度提升程度较为经济。
即,连续N帧初始图N至少要连续3帧以上。
所以,要拿摄像头排自己,时间要稍长点。
2、获取所述N帧初始图像中每帧初始图像中所述目标人脸的人脸图像。
专利语言过于拗口,通俗点解释,获取每帧初始图像中目标人脸的人脸图像可以是指从每帧初始图像中裁切出目标人脸的人脸图像。
简单点说,获取每帧初始图像中目标人脸的中心点,将该中心点作为人脸图像的中心点,裁切出预设尺寸的人脸图像,该人脸图像包含整个目标人脸。
所述N帧初始图像对应N帧人脸图像,所述N帧人脸图像的尺寸相同,例如N帧人脸图像的尺寸均为W×H,W为人脸图像的宽度,H为人脸图像的高度。
3、对N帧人脸图像进行亚像素插值,获得第一人脸图像
对N帧人脸图像进行亚像素插值,用于实现多帧超分,可以增加人脸图像的真实细节数量,提升人脸图像的细节清晰度,降低噪声,获得分辨率较高的第一人脸图像。
在知情郎看来,OPPO的工程师实际在一帧帧修图,来提高第一人脸图像清晰度,只不过不是人工精修,而是通过算法润色图片细节清晰度。
解释下,流程非常复杂。
1)从所述N帧人脸图像中选取一帧人脸图像作为参考人脸图像;
2)对所述参考人脸图像进行双线性插值,获得第三人脸图像;
3)对剩余N-1帧人脸图像中第i帧人脸图像进行双线性插值,获得第四人脸图像,i为大于零且小于或等于N-1的整数;
4)将所述第三人脸图像与所述第四人脸图像进行图像匹配,获取所述第三人脸图像中第一像素以及所述第四人脸图像中与所述第一像素匹配的亚像素;
5)获取所述第四人脸图像中与所述亚像素相邻的四个像素的像素值;
6)根据所述第四人脸图像中与所述亚像素相邻的四个像素的像素值,获取所述第四人脸图像中所述亚像素的像素值;
7)将所述第三人脸图像中所述第一像素的像素值与所述第四人脸图像中所述亚像素的像素值相加求平均,并将平均值作为所述第三人脸图像中所述第一像素的像素值;
重复执行步骤3、4、5、6、7步骤,直到遍历完所述剩余N-1帧人脸图像,并确定处理后的所述第三人脸图像为所述第一人脸图像。
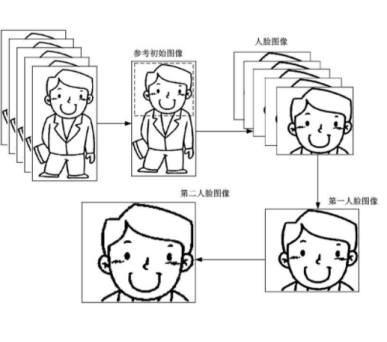
用图片理解下算法的意义
非图片处理领域人士大概率是看不懂上面流程的,尤其第三人脸图像、第四人脸图像的意义,知情郎也是看的一头雾水的。
不用纠结这些,第三人脸图像、第四人脸图像都是第一人脸图像服务的,他们都是在增强人脸图像的细节,提高分辨率。
一组连续N帧人脸图像,每一帧的图像总是有细微不同的。一帧帧的再提炼共同点,补足细节真实感。
亚像素的像素值如何计算的公式,OPPO工程师是这样的定义:
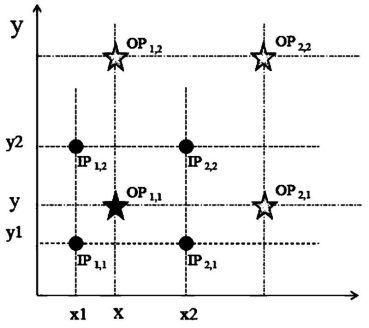
图中OP1,1、OP1,2、OP2,1、OP2,2为第三人脸图像中的像素;
OP1,1为第三人脸图像中的第一像素,也为第四人脸图像中的亚像素,IP1,1、IP1,2、IP2,1、IP2,2为第四人脸图像中与像素相邻的四个像素。
可利用下面这个公式计算第四人脸图像中亚像素的像素值:

公式中IP1,1、IP1,2、IP2,1、IP2,2分别为像素IP1,1的像素值、像素IP1,2的像素值、像素IP2,1的像素值、像素IP2,2的像素值,公式中使用的权重即为偏移量。
简单解释下,上面就是双线性插值算法在图像处理过程中的简单应用。
比如在图像的缩放中,在所有的扭曲算法中,都可以利用该算法改进处理的视觉效果。
看不懂不用纠结,简单科普,双线性插值充分利用了邻域像素的不同占比程度而计算得出最合适的插值像素,从而完成插值。
数学就是算法之源,数学不好,真的难混好!
10在提炼清晰度获得第二人脸图像
前面的动作都只是为了补足第一人脸图像的清晰图,当细节增强后的第一人脸图像确定时,将所述第一人脸图像输入至预设神经网络,获得第二人脸图像。
所述预设神经网络可以是指预先设置的用于提高第一人脸图像分辨率的神经网络,包括但不限于图像从深度重新排列为空间数据块depth-to-space层。在多帧超分之后加入深度学习超分网络(即预设神经网络),该深度学习超分模型可以去噪音、去模糊,在保证人脸特征不变的基础上,提高分辨率。
知情郎解释下,第二人脸的分辨率必然要比第一人脸高,因为这一步也是对第一人脸的进一步细节优化,形成第二人脸图像。
最后,系统识别第二人脸图像中的人脸。
整体来说,整个专利核心流程就是通过先获取针对目标人脸的连续N帧初始图像,再获取每帧初始图像中目标人脸的人脸图像,并对N帧人脸图像进行亚像素插值,获得尺寸和分辨率均放大的第一人脸图像,再将第一人脸图像输入至预设神经网络,对第一人脸图像进行图像增强,进一步放大第一人脸图像的尺寸和分辨率。
整个专利亮点就在于亚像素插值处理人物图像,通过将多帧超分与深度学习相结合,提升人脸图像中真实细节的数量,进而提高人脸识别精度。
对数字图像处理算法感兴趣的朋友可下载PDF,技术论坛里也有大量图像处理之双线性插值法心得体会。
学好数理化,走遍天下都不怕!不要搞嘴皮子弄话术,没价值~
