计算机视觉研究人员必备的Linux命令行技巧
磐创AI介绍
Jeroen Janssens在《命令行的数据科学》一书中对命令行优势进行了很好的分类:
命令行是灵活的:这个特性使它非常适合数据科学的探索性质。因为你想要及时得到结果。
命令行可以扩展:与其他技术很好地集成。(例如Jupyter笔记本、Colab等)
命令行是可伸缩的:因为你不使用GUI,你实际上输入命令,每个命令都有许多参数,所以它可以很容易地满足你的需要。
命令行是可扩展的:命令行本身与语言无关。因此,你可以开发和扩展它的功能,而不用担心语言。
命令行无处不在:命令行与任何类似Unix的操作系统一起提供。大多数超级计算机、嵌入式系统、服务器、笔记本电脑和云基础设施都使用Linux。
在这篇文章中,想介绍一些关于我经常用于项目的Linux命令
将命令分为两大类:
第一类包括在使用远程服务器和文件时有用
第二类命令包括有助于图像/视频操作。
使用远程服务器和文件
1.检查图像的尺寸
有时在远程服务器上,你正在处理数据,没有任何GUI来查看图像维度。可以使用以下命令检查图像尺寸:
linux@user-pc:~/some/path$ identify image_name.png
>>> image_name.png PNG 1920x1080 8bit sRGB 805918B 0.000u 0:00.000
如果你想将其用于目录中的多个图像(可能你想将它们合并为一个片段,但其中一些图像的维度与其他图像不同!),使用*.png而不是image_name.png
脚本:
import cv2
from pathlib import Path
images = Path('path').rglob('*.png')
for img_path in images:
img = cv2.imread(img_path
print(img_path, img.shape)
2.清点目录上的图像
在一些目录中创建数据集之后,我经常检查图像和标签的数量是否相等。(由于我使用jupyter notebook,有时会有一个名为.ipynotebook的隐藏目录,在使用ls命令时不会出现,当数据生成器开始从该目录获取数据时,会出现问题)。
要统计所有图像,请执行以下操作:
ls path/to/images | wc -l
要仅检查png格式文件,请执行以下操作:
find -name *.png -type | wc -l
要使用存储大小检查目录,请执行以下操作:
du -lh --max-depth=1
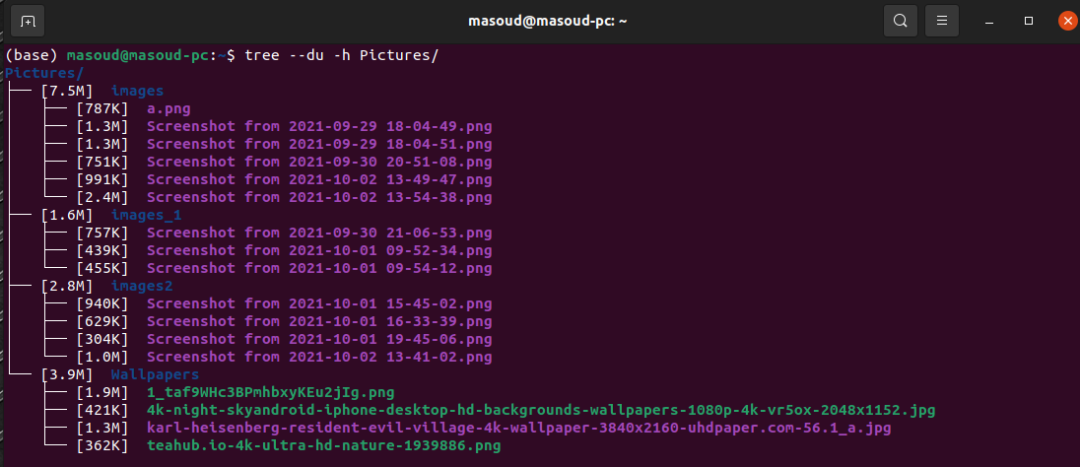
你还可以使用tree -du -h Path/to/images来检查映像及其占用的磁盘存储空间。命令树的输出更加直观,如下所示:
3.将文件从本地PC复制到远程服务器
我们经常需要将数据上传到远程服务器(或从远程服务器下载)。要做到这一点,你应该以以下方式使用scp命令:
首先,我建议你使用以下命令压缩文件夹:
zip -r output.zip path/to/images path/to/labels
要下载,你应该在本地PC上使用以下命令:
scp remote_user@remote_host:remote_path local_path
例如:
scp user_1@111.222.333.444:/home/user_1/path /home/local_user/path
要上传,请切换源和目标:
scp /home/local_user/path user_1@111.222.333.444:/home/user_1/path
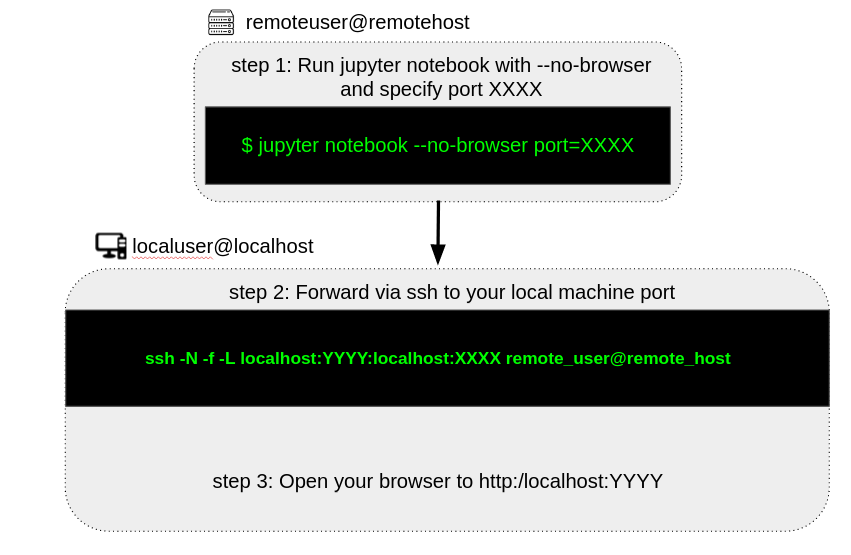
4.在远程服务器上运行jupyter notebook
jupyter notebook帮助研究人员编写脚本和可视化。为了在本地PC上使用它,同时在远程主机上运行,我们在本地计算机和远程主机上使用以下命令,将jupyter notebook转发到本地:
在远程服务器上运行jupyter notebook:
jupyter notebook --no-browser --port=XXXX
端口将本地端口转发到远程端口:
ssh -N -f -L localhost:YYYY:localhost:XXXX remote_user@remote_host
5.使用TMUX运行ML模型训练/评估
在ML模型训练中,我经常遭受网络断开的痛苦,这有时会让我回到原点,重新开始训练模型!
因此,我发现tmux程序是一个非常好的解决方案,你可以将进程与其控制终端分离,从而允许远程会话在不可见的情况下保持活动状态。
使用tmux过程。
· 要启动tmux会话,只需键入tmux。
· 要重命名会话,请键入rename-session -t some_random_name(仅当你已激活会话时)。
· 然后你可以运行你的进程,按CTRL+B,然后按D,从中分离出来。
· 要附加会话,可以使用tmux attach -t some_random_name。
· 要终止会话,请执行tmux kill-session -t yolo
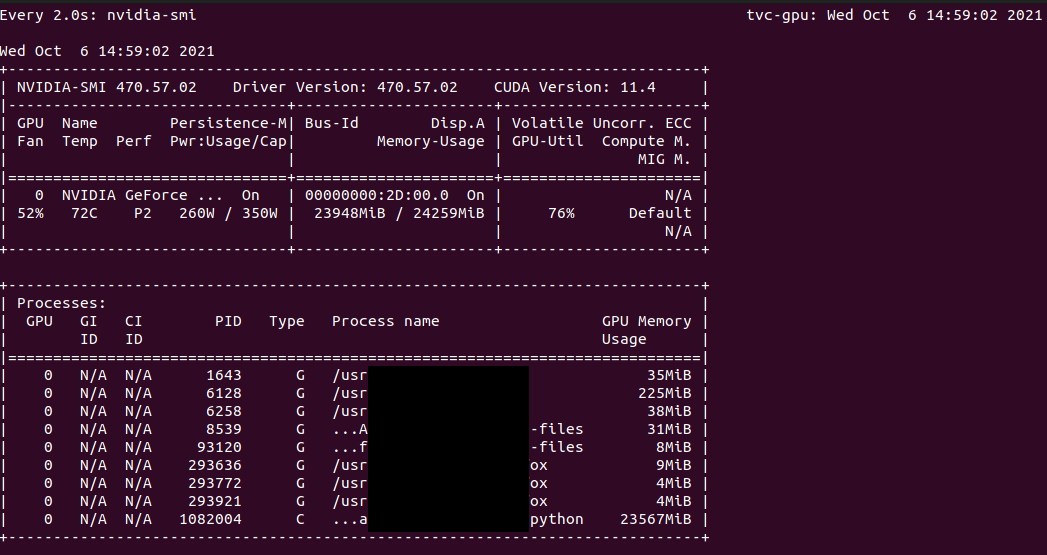
6. 查看GPU资源
如果你在一个团队中工作,你可能会和同事一起经历GPU资源的竞争!!要了解GPU的使用情况(了解其他人何时不使用GPU),请使用以下命令:
watch -n nvidia-smi
nvtop(更好的可视化):
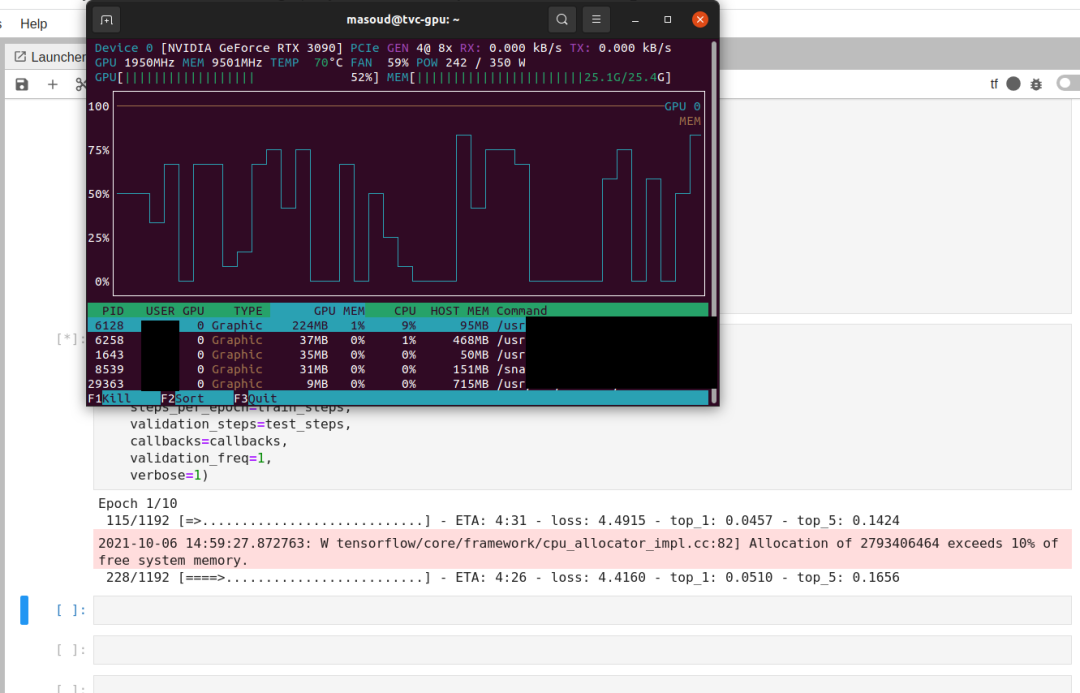
gpustat(管理员更适合同时观看多个GPU)

有时,当你开始训练你的ML模型时,你会将结果记录在一些文本文件中。例如,Detectron2框架或YOLOV5记录度量(准确性、损失等)。
因此,如果我无法访问tensorboard,我将使用此命令检查最后5行的结果,每100秒更新一次:
watch -n 100 tail -n 5
我根据损失和准确度值保存检查点,并用相应的损失和准确度命名权重。因此,我可以在命令行中对它们进行排序,并使用以下命令检查最后一个检查点的准确度:
ls checkpoints | sort | tail -n 1
6.创建gif绘图以显示时间序列图像
我使用GradCam算法,使用tf-explain模块在测试图像上可视化激活层特征提取热图。我经常从图中生成gif,以了解训练过程如何影响模型的准确性。要将目录中的图像转换为绘图,可以使用以下命令:
convert -delay 10 -loop 0 *.png animation.gif
结果是:

如果要将视频转换为gif,可能会注意到输出的gif会变得非常大。因此,减少gif大小的最佳方法是从视频中采样。为此,请使用-r,即采样FPS:
ffmpeg -i video.mp4 -r 10 output.gif
视频/图像处理
ffmpeg是计算机视觉工程师的必备技能,因为她/他必须处理视频/图像数据。ffmpeg有很多技巧,在这里只分享其中的几个。
1.检查视频持续时间
使用以下命令:
ffmpeg -i file.mp4 2>&1 | grep “Duration”
输出结果如下:Duration: 00:05:03.05, start: 0.00000, bitrate:201 kb/s
2.转换视频格式:
为此:
ffmpeg -i video.mp4 video.avi
如果你只需要视频中的音频:
ffmpeg -i input.mp4 -vn output.mp3
3.从视频生成数据集
有时我们可能需要从视频中生成一个数据集,其中一些动作很少发生,比如检测罕见动作或罕见对象,这可以称为“异常检测”。为此,我们需要播放长达数小时的视频。我使用此命令剪切视频的某些部分:
ffmpeg -ss 00:10:00 -i input_video.mp4 -to 00:02:00 -c copy output.mp4
在该命令中:
-ss:开始时间
-i:输入视频
-to:大约2分钟。
-c:输出编解码器
如果你想要没有音频的视频:
ffmpeg -i input_video.mp4 -an -c:v copy output.mp4
-an:用于在没有音频的情况下进行输出。
4.为CONVLSM或3d CNN生成一系列帧
CONVLSM和3d CNN网络用于提取视频序列的时序特征。因此,为了使用这些网络,我们必须为它们的输入张量生成一系列帧。使用此命令从视频生成20秒的图像:
ffmpeg -ss 00:32:15 -t 20 -i videos.ts ~/frames/frame%06d.png
可以添加比例来重新缩放图像尺寸。我大部分的视频都是1028x540,它的宽度必须减半。这是执行此操作的命令:
ffmpeg -ss 00:10:00 -t 20 -i video.ts -vf scale=iw/2:ih output_path/frame%06d.png
或者你可以简单地输入尺寸:
ffmpeg -ss 00:10:00 -t 20 -i video.ts -vf scale=960x540 output_path/frame%06d.png
5.裁剪视频边框
裁剪视频边框:
ffmpeg -i input.mp4 -filter:v "crop=w:h:x:y" output.mp4
6.堆叠视频
在TVConal初创公司,我从事体育分析项目,有时我们想检查不同的视频源是否同步。
视频名称为a.mp4-b.mp4 c.mp4 d.mp4。




6.1-水平堆叠视频:
要沿水平堆叠,我们使用以下命令:
ffmpeg -i a.mp4 -i b.mp4 -filter_complex hstack output.mp4

6.2-垂直堆叠视频:
要沿垂直堆叠,我们使用以下命令:
ffmpeg -i a.mp4 -i b.mp4 -filter_complex vstack=inputs=2 end_vstack.mp4

6.3 2x2网格堆叠
现在让我们尝试更复杂的方法:
ffmpeg -i a.mp4 -i b.mp4 -i c.mp4 -i d.mp4 -filter_complex "[0:v][1:v][2:v][3:v]xstack=inputs=4:layout=0_0|w0_0|0_h0|w0_h0[v]" -map "[v]" 2x2.mp4

结论
相信命令行和python将为数据科学界提供一套强大的工具。因此,使用这些功能强大的工具,我们可以减少在简单任务上的时间浪费。
感谢阅读!
参考引用