科普 | 联邦学习这件小事
趣链科技背 ?景
计算机学院的学生小A意图使用大数据及人工智能的相关技术完成自己的一个课题《大学生男生生活费消费行为的偏好分析》,然而苦于数据量不够,便寄希望于身边的朋友以及学校的广大男性同学,原本以为是一件轻而易举的事,然而…

由于个人隐私易泄露,数据交易难定价,合作者激励制度不健全,以及恶意提供无用或者虚假数据等问题,收集真实且有价值的的数据远比想象中难。
而近两年来,“联邦学习”被学术界和工业界经常提及,联邦学习究竟是什么,为何能解决以上问题,我们从它的前世今生开始慢慢揭开面纱。
▲?人工智能(AI)是什么
人工智能是人为制造出来的智能,可以让机器“智能”地完成一些通常认为只能由人来完成的简单工作。其研究目的是促使智能机器会“听”(语音识别、机器翻译等)、会“看”(图像识别、文字识别等)、会“说”(语音合成、人机对话等)、会“思考”(人机对弈、定理证明等)、会“学习”(机器学习、知识表示等)、会“行动”(机器人、自动驾驶汽车等)。
自1956年人工智能的概念被提出至今,有了飞速的发展。从早期的电子游戏AI(娱乐)等,到现阶段的智能家居(室内生活)、围棋新星阿尔法狗(竞技运动)等,到未来的无人驾驶工具(交通运输)以及毁天灭地的终结者(战争)都是人工智能应用的产物。
人工智能已经改变了我们的生活,从遥不可及的实验室科技转变成为我们身边随处可见的工具,甚至改变世界的重要伙伴。人工智能中的“学习”能力是人工智能发展的核心,方法也层出不穷,机器学习、深度学习、强化学习……可以统称为机器学习。发展至今,我们也逐渐发现了制约机器学习和人工智能进一步发展的瓶颈。
▲?机器学习的瓶颈
1. 算法瓶颈
目前的机器学习存在着鲁棒性较差以及算法的不可解释性两大问题。
虽然人工智能领域依靠深度学习在图像识别上取得了巨大的突破,然而在加入“噪声”后将图片内容完全识别错误的“人工智障”行为依旧屡见不鲜;其次,在引入神经网络的机器学习中,“黑盒子”状态的算法虽然提升了算法的效果,但因缺乏严格的数学理论证明以及算法的解释性,从而一直为学业界的人士所诟病。
2. 数据瓶颈
2.1?数据需求量大
计算能力和计算成本是首当其冲需解决的问题,而一个好的机器学习算法背后,是大量数据多轮次的重复性计算的结果,需要大量算力成本。
2.2?数据供给稀缺
云计算、AI技术发展至今,我们发现制约AI应用落地的是没有足够的数据支撑算法的训练和验证。巧妇难为无米之炊,缺少数据的机器学习算法犹如空油的F1赛车,无法施展它最强的性能。
联邦学习的前世今生
▲?数据隐私问题
数据是机器学习的原油,伴随机器学习的兴起和大数据的浪潮,数据的收集成为业内的产业之一。因为产业的暴利和法制的不健全,用户的信息被大肆的爬取、收集、贩卖,导致很长一段时间我们的生活不堪其扰。
APP上的信息爬取,电话与身份信息泄露让我们总是能接收到各种广告推销电话。更有甚者,“裸贷”风波和Facebook用户信息泄露,让大众在信息化时代对于个人信息安全更加谨慎小心。2018年的欧洲隐私和数据保护法案GDPR的出台虽然一定程度上保障信息隐私安全并规范了数据收集方式,但无形中加剧了优质数据整合的难度,对机器学习与人工智能领域都是一次重大的挑战。
▲?联邦学习的前世
伴随着以上涉及到的问题,Google公司早在2016年提出联邦学习的概念,这一概念原本用于解决安卓手机终端用户在本地更新模型的问题,具体如下:
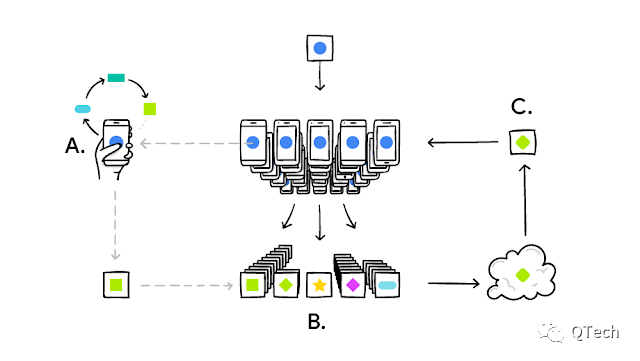
Step1. ?手机下载现有模型;
Step2. ?用手机的本地数据来训练模型;
Step3. ?训练好后,迭代更新,并将更新的额内容加密上传到云端;?
Step4. ?与其它用户的更新进行整合,作为对共享模型的改进;
Step5. ?该过程不断重复,改进后的共享模型也会不断地被下载到本地。
值得注意的是,在执行的过程中有两个特别的点:?
- 每个设备端在更新己方模型时都是依赖于自己数据的个性化更新;
- 该场景中的共享模型可能不是完整的机器学习模型/神经网络模型,可能是经过压缩的模型。
联邦学习的正式诞生是在2017年,Google的AI?blog中提出的一种分布式机器学习框架,目标是在保证数据隐私安全及合法合规的基础上,实现多方共同建模,并提升AI模型的效果。当完成训练后,根据联邦学习特有的激励机制,会给予所有的参与方一定的激励作为共同参与训练的奖励。随后以杨强教授为首的团队进一步推进联邦学习框架,直至我们现在所看的样子。
联邦学习的分类
▲?联邦学习的精髓
国际人工智能联合会主席杨强教授曾经举过一个联邦学习的例子:
我们每个人的大脑里都有数据,当两个人在一起做作业或者一起写书的时候,我们并没有把两个脑袋物理性合在一起,而是两个人用语言交流。所以我们写书的时候,一个人写一部分,通过语言的交流最后把合作的文章或者书写出来。
我们交流的是参数,在交流参数的过程中有没有办法保护我们大脑里的隐私呢?是有办法的,这个办法是让不同的机构互相之间传递加密后的参数,以建立共享的模型,数据可以不出本地。
故而,在本地数据不出库的情况下,通过对中间加密数据的流通与处理来完成多方对共享模型的机器学习训练,便是联邦学习的精髓所在。
▲?横向联邦学习
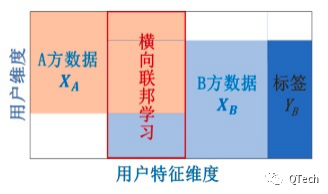
横向联邦学习是指,在不同数据集之间数据特征重叠较多而用户重叠较少的情况下,按照用户维度对数据集进行切分,并取出双方数据特征相同而用户不完全相同的那部分数据进行训练。
横向联邦学习的本质是样本的联合,适用于参与者间业态相同但触达客户不同,即特征重叠多、用户重叠少时的场景,比如不同地区的银行间,他们的业务相似(特征相似),但用户不同(样本不同)。
▲?纵向联邦学习
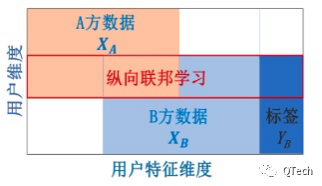
纵向联邦学习是指,在不同数据集之间用户重叠较多而数据特征重叠较少的情况下,?按照数据特征维度对数据集进行切分,并取出双方针对相同用户而数据特征不完全相同的那部分数据进行训练。
纵向联邦学习的本质是特征的联合,适用于用户重叠多,特征重叠少的场景,比如同一地区的商超和银行,他们触达的用户都为该地区的居民(样本相同),但业务不同(特征不同)。
▲?迁移联邦学习
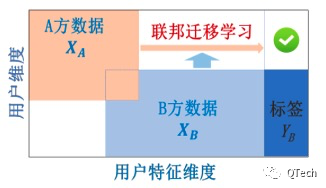
联邦迁移学习是指,在多个数据集的用户与数据特征重叠都较少的情况下,不对数据进行切分,而是利用迁移学习来克服数据或标签不足的情况。
当参与者间特征和样本重叠都很少时可以考虑使用联邦迁移学习,如不同地区的银行和商场间的联合。主要适用于以深度神经网络为基模型的场景
小结
本次带大家走进“联邦学习的大门”,简要介绍了联邦学习的「前世今生」及「不同分类」,下一篇将会详细讲解「不同分类下的联邦学习」,敬请期待!
作者简介
严杨
来自数据网格实验室BitXMesh团队
?PirvAIの修道者


