谷歌 VS OpenAI,大模型Gemini有多拼?
Ai芯天下前言:
为了与OpenAI和微软在人工智能领域展开竞争,谷歌采取了果断的措施。
他们从PaLM 2切换到了Gemini上,并决定将谷歌大脑和DeepMind合并,以进一步加强对大模型的研发能力。
合并后的Google DeepMind将集两个实验室的力量,全力攻关Gemini。这充分展示了谷歌在大模型军备竞赛中孤注一掷的心态。
作者 | 方文三
图片来源 | 网 络
谷歌大模型Gemini正式发布
近日,谷歌公司宣布推出新型大型语言模型Gemini。
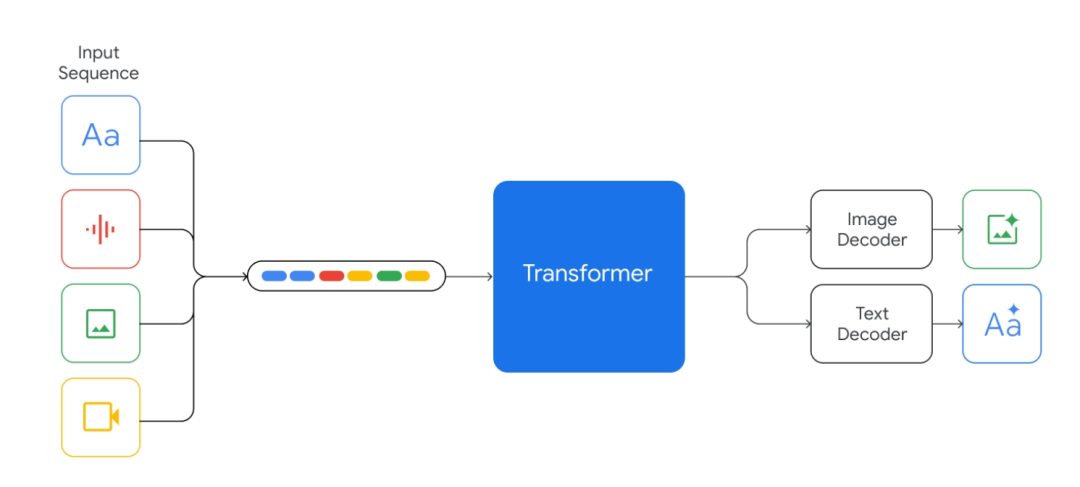
Gemini是一个多模态大模型,意味着它可以泛化并无缝地理解、操作和组合不同类型的信息,包括文本、代码、音频、图像和视频。
谷歌表示,Gemini还是他们迄今为止最灵活的模型,能够高效地运行在数据中心和移动设备等多类型平台上。
Gemini提供的SOTA能力将显著增强开发人员和企业客户构建和扩展AI的方式。
Gemini将作为首个直接在手机上运行的大型模型,应用于谷歌Pixel 8 Pro智能手机和聊天机器人Bard。
谷歌计划通过谷歌云向客户提供Gemini授权,并将在未来几个月内将其与其他谷歌服务产品进行集成。
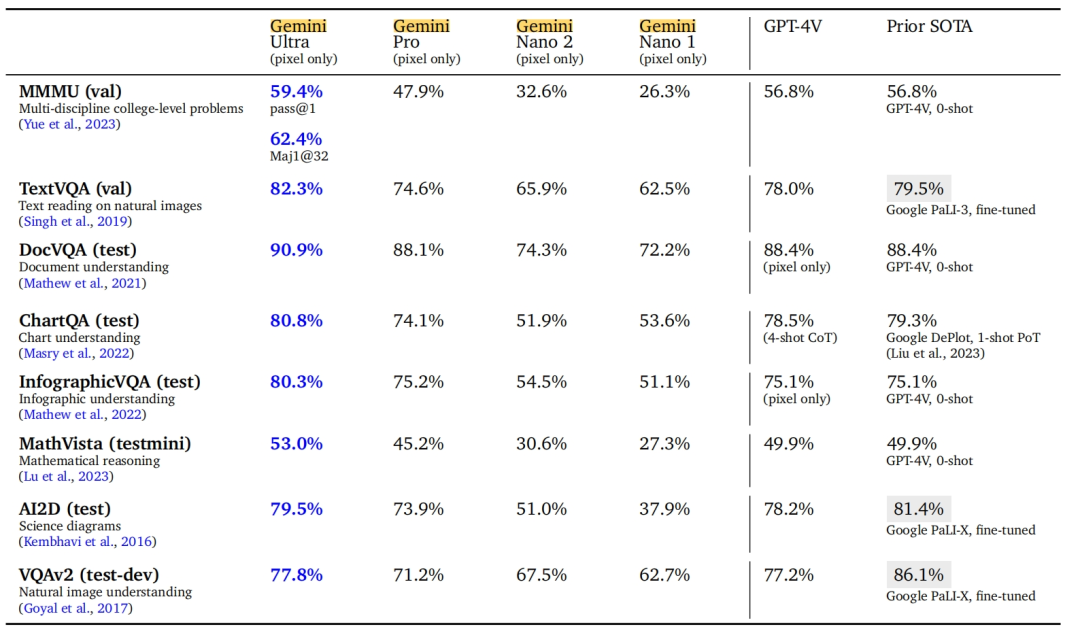
为了比较Gemini与OpenAI的GPT-4的性能,谷歌运行了32个完善的多模态基准测试,结果显示Gemini在32项基准测试中的30项中均领先于GPT-4。
在MMLU(大规模多任务语言理解)测试中,Gemini首次在MMLU得分率达到90.0%,成为第一个在MMLU测试中超越人类专家的模型。
Gemini包括了三种不同规模的模型:
①Gemini Ultra为最大、功能最强大的类别,定位为GPT-4的竞争对手;
②Gemini Pro为中端型号,性能优于GPT-3.5,可扩展多种任务;
③Gemini Nano则适用于特定任务和移动设备。
利用移动手机的算力来运行生成式AI,而不是通过由大型科技公司运营的云端服务器,这将大大降低运营这类系统的成本。
对于那些希望将私人数据限制在设备上的人来说,这也提供了一层保障。
然后,在面临有关宣传方面可能存在夸大的质疑下,谷歌在一篇官方博客文章中,谷歌的回应基本上承认了。
在实现演示视频中所展示的效果时,必须依赖于使用静态图片以及多段提示词的组合。
以视频为例,其中展示了向Gemini系统轮流展示拳头、剪刀手和张开的手掌,而Gemini系统能够立刻理解这是在玩猜拳游戏。
然而,谷歌在文章中明确指出,只有当同时向Gemini系统展示这三个手势,并给予提示这是游戏时,系统才会得出猜拳游戏的结论。
从投资者角度来看,至少这是一个积极的开端。上周四,谷歌的股价出现了暴涨,市值增加了800亿美元。
谷歌 VS OpenAI:从失利的首败走出来
在今年2月的巴黎活动中,谷歌因聊天机器人Bard的一次失误,导致市值蒸发了1000亿美元,引发了外界对Bard准确性的担忧。
同时,随着竞争对手OpenAI推出的ChatGPT以及在必应搜索中整合的GPT技术,谷歌在应用程序下载量上被超越,人们开始质疑谷歌是否在人工智能领域落后于竞争对手。
其实谷歌才是提出2017年Transformer模型、为当今人工智能领域制定规则的先行者。
2021年,谷歌推出了1.6万亿参数的Switch Transformer,强调稀疏多模态结构的潜力。
此外,谷歌还提出了Flan-T5模型,通过更多监督数据降低了模型规模,比GPT-3模型参数更少但性能更佳。
测试结果显示,谷歌AI在数学问题上表现更佳,但ChatGPT在常识问题上更准确。
谷歌在AI领域取得了不少研究进展,但尚未将这些成果部署和变现,类似于微软在过去的某些时期。
这可能是因为谷歌低估了微软和OpenAI的竞争实力,或者过于自信于自己在搜索引擎领域的主导地位。
在Sam Altman领导下的OpenAI专注于产品为导向的工作,致力于扩展和优化模型,主要关注细节精调方法。
而谷歌则在技术发展的方向上始终保持着积极和前瞻的态度,不过在整体战略规划上却屡次调整。
在谷歌[选择困难症]期间,OpenAI已经完成了对ChatGPT的训练。
GPT-4 VS Gemini:多模态的性能优势凸显
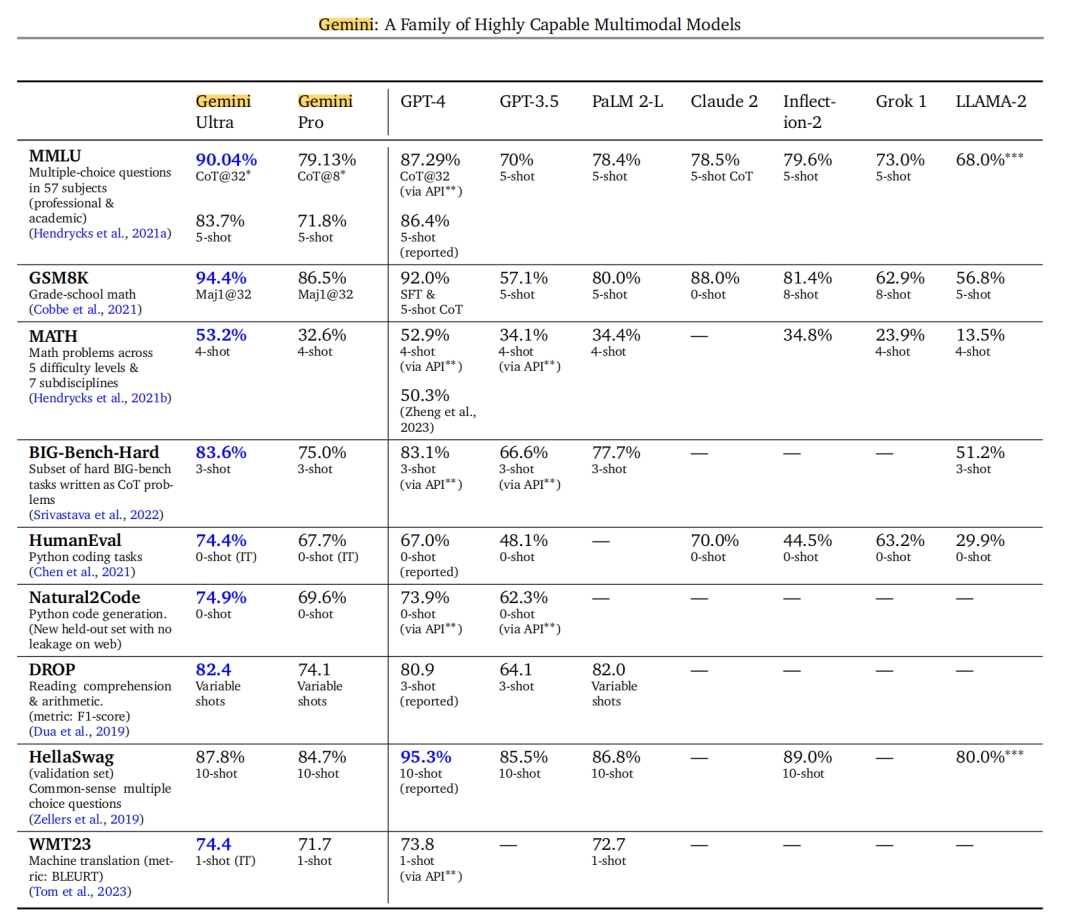
作为谷歌应对GPT-4的[重要武器],Gemini在32个多模态基准测试中取得了30个SOTA(即当前最优效果)的记录,凸显了其在多模态任务中的卓越性能。
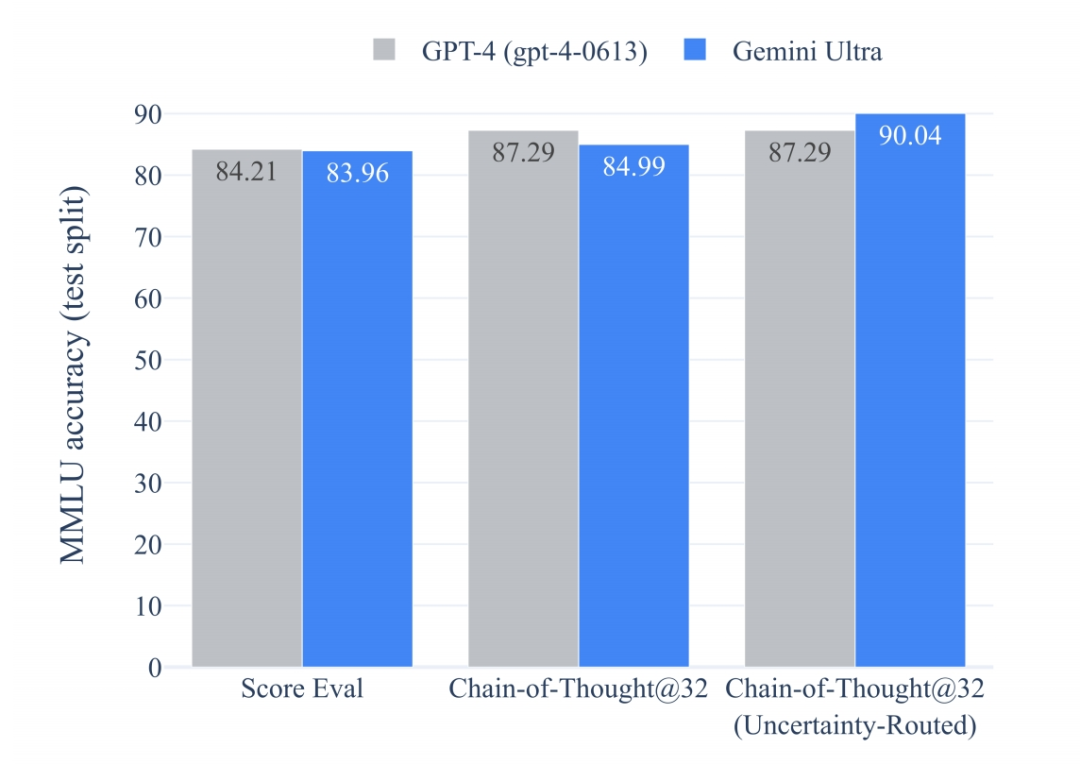
它是第一个在MMLU(大规模多任务语言理解)测评上超越人类专家的模型,其成绩达到了90.0%,相比之下,人类专家的成绩为89.8%,GPT-4的成绩为86.4%。
在多选问题、数学问题、Python代码任务、阅读等方面,Gemini的性能都超过了此前最先进的水平。
与GPT-4相比,谷歌提供的数据显示Gemini Ultra全面超越GPT-4,而Gemini Pro在大多数指标上超越了GPT-3.5。
总体来说,Gemini在运算效能和任务性能方面都展现出了卓越的表现,成功应对了GPT-4的挑战。
Gemini模型最初强调了其生成文本和图像的能力,以与GPT-4区分开来。
具体而言,Gemini可以理解正式和非正式语言之间的差异,捕捉文本的语气和情感,并识别其他文本或来源的引用和暗示。
现在,两者之间的关键差异可能在于谷歌丰富的专有训练数据集。
Gemini能够处理来自各种服务(包括Google搜索、YouTube、Google Books和Google Scholar等)的数据。
这些服务包含了来自不同领域和语言的大量丰富信息,有助于Gemini从各种来源和语境中学习。
Gemini的培训数据量是GPT-4的两倍,这可能使其在从数据集中产生更复杂的见解和推断方面具有优势。
当然GPT-4也有其独特的优势,GPT-4作为OpenAI开发的大语言模型,在语言理解和生成方面具有很强的能力。
GPT-4采用Transformer架构和无监督学习技术,能捕捉长距离依赖关系和上下文信息,展现出卓越的语言理解和生成能力。
此外,GPT-4还具有强大的推理能力,适应各种复杂场景并提供更智能高效的服务。
结尾:
与OpenAI的方法不同,谷歌从一开始就构建了一个多感官模型。
多模态是生成式AI下一步的重点方向,有待继续探索的应用场景非常广泛。
下一阶段的重点攻克方向是多模态技术。
短期来看,Gemini的发布将进一步激发市场对多模态模型的期待,对产业而言,多模态将带动算力需求的提升。
中长期来看,预计多模态模型的升级将丰富相关产品的使用场景,叠加硬件升级、算法优化带来的成本优化,2C产品的进展值得期待。
部分资料参考:机器之心:《谷歌大杀器终于来了,最大规模Gemini震撼发布》,甲子光年:《优等生归来,谷歌最强大模型Gemini能否打败GPT4?》,财经E法:《Gemini发布仅一天就遭质疑,谷歌追赶OpenAI太过心急?》
