套壳的大模型,为何还活着?
阿尔法工场所谓的“套壳”,并不意味着国产大模型黑暗的前景。
国产大模型套壳,是个被吐槽已久的现象。
最近,前阿里巴巴副总裁、知名AI框架大牛贾扬清昨日发朋友圈,爆锤国内某大厂套壳大模型LLaMA。
大意是:要改就改吧,但别掩耳盗铃了,免得小公司做一些多余的适配工作……
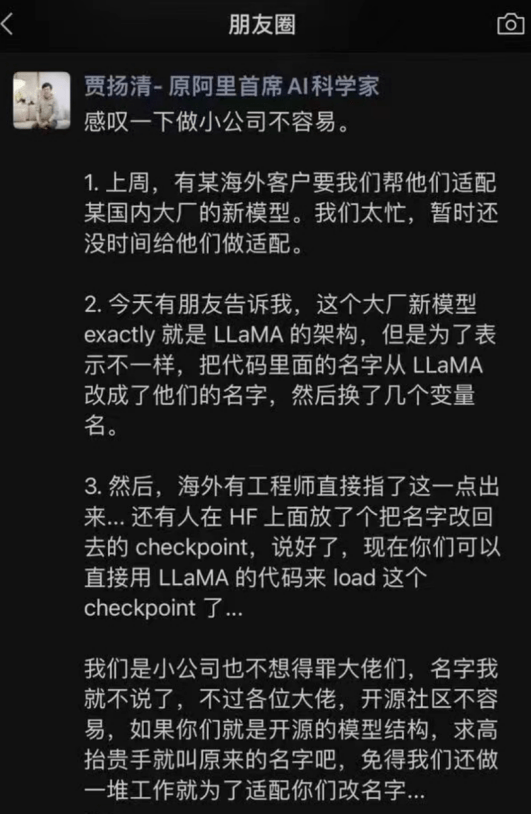
针对这条消息,业内不少人士纷纷猜测,贾扬清所说的那个“套壳大厂”,实际上就是前不久刚发布了Yi-34B大模型的零一万物。
作为李开复AI团队的第一个大模型,Yi-34B有34B个参数,也是基于GPT的架构,且在Hugging Face和C-Eval的两个开源模型排行榜上,都取得了第一的成绩。
然而,在模型发布后不久,Hugging Face社区就给零一万物留了条消息,要求其修改模型张量。
理由是:除了两个张量被重新命名外,Yi完全使用了Llama的架构。
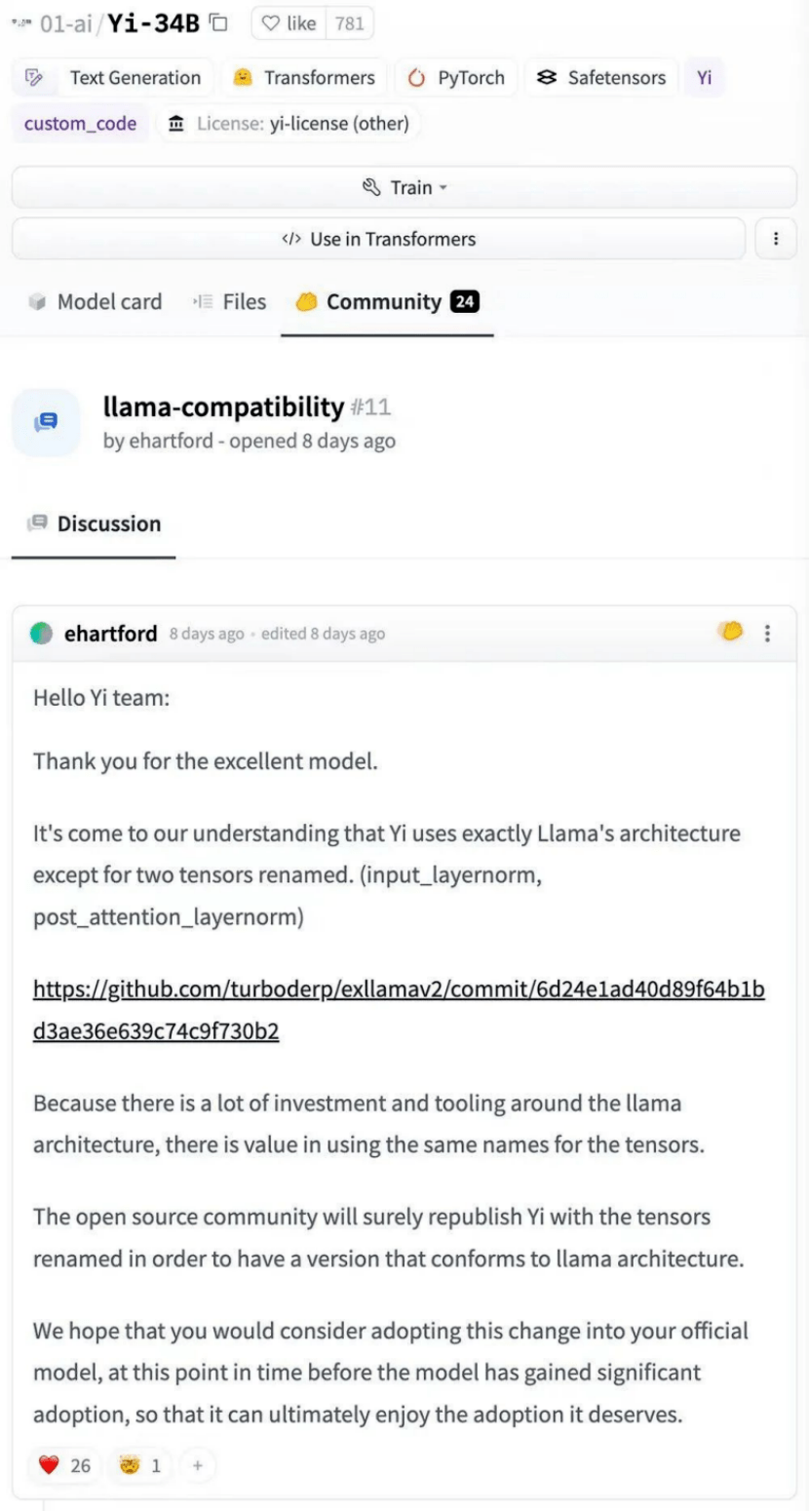
看到这儿,不少业内人士纷纷皱眉:这是赤裸裸的“套壳”吗?
如果是的话,为什么大模型浪潮都已经过去大半年了,这种“歪风邪气”还是层出不穷呢?
01 怎样才算“套壳”?
实际上,在该事件传出后不久,零一万物就做出了回应,他们承认Yi-34B的结构设计是基于GPT的成熟结构,借鉴了LLaMA的公开成果,但是这是为了与行业主流保持一致,更有利于适配和迭代。
不过,这种解释涉及到了个很重要的问题,那就是:到底该怎样泾渭分明地界定“套壳”和“借鉴”?
在开源模型的基础上进行修改、调整,究竟算不算一种“套壳”行为?
从技术层面上来说,判断一个项目是“借鉴”还是“套壳”,关键在于评估所做的改进或优化是否具有实质性和原创性。

在借鉴的过程中,开发者会在原有模型的基础上做出显著的增值,例如引入新的数据处理技术、优化算法性能,或者开发特定于某个行业或应用的功能。
同时,在借鉴时,开发者通常会明确指出,他们的改动是基于哪个开源模型,并说明他们所做的改进和创新。这种做法符合开源社区的原则和精神。
相反,如果改动仅限于表面层面,没有提供任何新的技术见解或实质性的性能改进,则就可以被视为套壳。
那这次零一万物的Yi-34B,算套壳吗?

从已经公布的信息来看,零一万物公司的做法似乎介于“套壳”和“借鉴”之间。
他们确实在一定程度上依赖了LLaMA的架构,但也在数据处理、训练方法等方面进行了自己的工作和创新。
例如,其使用了自建的数据管线,从3PB原始数据中精选到3T token的高质量数据,以及在在网络宽度和深度上测试了不同的Norm方法。
这些改进可能不那么容易从模型的架构或代码直接观察到,它们通常在模型的内部,而不是直接体现在模型的基础架构上。

这种情况下,将其完全归类为“套壳”可能有失公允。
但也不能完全视为独立的“借鉴”,原因在于其模型架构与LLaMA架构的高度相似性。
当一个新模型在核心架构上,与现有的开源模型高度相似或几乎一致时,即使在其他方面有所创新和改进,也很难被完全视为独立的“借鉴”。
02 时间压力
尽管零一万物此次的意外,或许算不上完全的“套壳”,但国产大模型“套壳”的情况,确实由来已久。
国产大模型,为何屡屡“套壳”?
除了算力、人才和资金方面的短缺,让部分团队“另辟蹊径”外,另一个重要的原因,就是当前大模型创业的时间窗口,已经收得越来越紧了。
毕竟,大模型这股热潮,已经燃烧了大半年之久,该入局的玩家早已入局,整个行业的格局已经基本形成。

头部大厂的地位撼动,国外同行又不断推陈出新,留给模型层团队的时间,真的不多了。
在市场上同类大模型越来越多的情况下,客户为什么要偏偏苦守着一个研发缓慢,前途又不甚明朗的大模型?
市场对于快速解决方案的需求迫在眉睫。客户的需求不能等。他们需要现在就能用的解决方案,而不是几年后。
在这样的压力下,部分团队做出了选择:使用开源模型作为基础,对其进行改进和定制,以适应市场的需求。
毕竟,即使拥有顶尖人才,创新和自主研发的过程也是漫长且充满不确定性的。因为人工智能领域正在快速发展和变化,市场和技术的不确定性意味着巨大的研发风险。
在今年10月之前,不少国内团队,都将GPT-4当成“对标”的目标。然而,殊不知你在进,你的对手也在进。
9月底,OpenAI推出了DALL-E3,紧接着又推出了GPT-4V和语音交互功能,在多模态层面更上了一层楼。
而11月初开发者大会的一系列“王炸”更新,则用更长的文本长度、全新的 Assistants API、以及文本转语音(TTS)技术,扼杀了想在“局部领域”进行突围的国产模型。
在技术迭代迅速的情况下,许多团队还在苦苦研发的大模型,也许还没发布,就已经过时。
对于创业团队来说,在保持技术创新的同时,也要考虑到商业模型的可行性和市场的接受度。
而有着成熟框架,且得到市场广泛认可的开源大模型,无疑成了一种可靠的,可以马上投入使用的方案。

并且,成熟的开源框架通常有一个庞大的社区支持,这意味着团队在遇到问题时可以获得更多的帮助。
同时,社区中的其他开发者可能已经解决了一些常见问题,团队可以直接借鉴这些解决方案,避免重复劳动。
03 套壳大模型,能投吗?
在国产大模型“套壳”已经成普遍现象,并且将来极有可能成为常态的情况下,所有投资人都不得不面对一个问题,那就是:
如果硬是要在这些“套壳”的大模型公司里,物色可投资的企业,那应该怎么选?
在考虑这个问题时,有一个非常重要的因素,即:
这些套壳的大模型公司,究竟是完全依赖于“套壳”,没有任何自主研发的努力和计划,还是以“套壳”作为妥协和过渡手段,但有明确的长期发展计划,有创新的愿景,有能力最终转向自主研发?

这两种情况,需要区别对待。
在对这两类企业进行考察时,一个十分重要的衡量标准,就是技术和产品路线图。
因为一个清晰、具有前瞻性的技术和产品路线图,直接反映了企业的长期战略意图和创新能力。它不仅显示了企业是否有计划从“套壳”转向自主研发,还表明了企业未来技术发展的方向和潜在的市场竞争力。
实际上,以类似“套壳”的方式进入市场,最后却依靠自研产品获得用户认可的案例,在商业上并不罕见。
例如移动互联网时代的小米,就是一个明显的例子。

起初,小米的智能手机在外界看来,似乎只是模仿了其他品牌(尤其是苹果)的设计和功能。其早期产品被批评为缺乏创新,更多地依赖于现有的设计和操作系统(基于Android的MIUI系统)。
然而,小米后来展示了对自身技术和产品路线图的长期坚持,其不仅在软件上(MIUI系统)进行了大量的自主创新,还在硬件设计、功能创新以及用户体验上进行了显著的研发。
例如其自主研发的手机芯片Surge S1,就标志着小米在手机核心技术领域的自主创新。
随着时间的推移,小米凭借更多的创新技术,在市场上获得了极高的评价和广泛的用户基础。

同样地,在当前“套壳”的国产大模型企业中,也不排除存在着一些有着长期技术路线的企业。
倘若以这样的观点来看,所谓的“套壳”,也并不意味着国产大模型黑暗的前景。
从产业的角度来说,只有更多具有创新潜力的企业,从AI浪潮初期的“大过滤器”中幸存了下来,未来更多的自主创新,才可能相继出现。
