遥遥领先!华为AI“盘古Chat”要来了
“先有华为后有天”
别看百度、阿里、360、科大讯飞等等一线互联网大厂在AI潮里“上蹿下跳”,都想勇立潮头,掀风裹雨。
但是要问最期待哪家推出自研AI大模型,毫无疑问当属菊厂——华为。

近日,华为官宣将在7月7日举行华为云开发者大会 (HDC.Cloud2023),这场开发者大会有一个众人皆知的主题,就是全新的鸿蒙4.0。而除此之外,更令人期待的还有华为自己的“ChatGPT”。
盘古Chat,这次不“遥遥领先”了?
据可靠的“内部消息”,华为将在本次的开发者大会上正式推出华为AI大模型——“盘古Chat”。不过目前,华为官方未就此消息表态。但“无风不起浪”,现在业内小道消息的准确率越来越高,辟谣都当官宣听。

对标ChatGPT,是华为对“盘古Chat”的预期和目标,该大模型拥有千亿级别参数,支持多模态能力,有望争一争国产最强大模型的宝座。
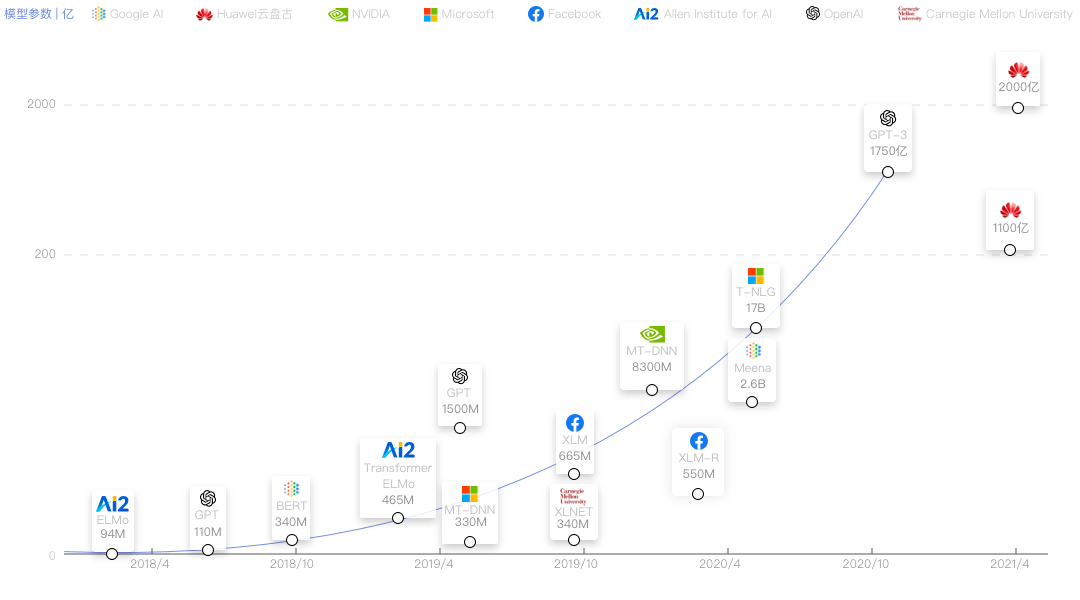
华为还是谦虚了。虽然对外称盘古有千亿级别参数,但是在一份华为公布的论文数据里,盘古 PanGu-Σ 大模型参数最多为 1.085 万亿。
而目前最强的GPT4拥有百万亿参数,ChatGPT(GPT3.5)参数量为1750亿。国内大模型普遍参数范围在1000亿到10万亿之间,其中最高的是宣称拥有那个10万亿+参数规模的阿里“通义千问”大模型。
虽说参数量不代表AI大模型的最终实力,毕竟谷歌最新的PaLM2模型有3400亿参数规模,比前代5400亿还少了,可无论是从速度还是能力上,都远强于一代。(降本增效原来是有用的啊!)
但,参数规模还是初期阶段评价一个大模型能力的关键标准。在这方面,盘古Chat虽没有秉承华为一贯“遥遥领先”的架势,可也说不上掉队。
来自天眼查的消息,华为技术有限公司于近期申请注册了两枚“HUAWEINETGPT”商标,国际分类为科学仪器、网站服务,当前商标状态为申请中。
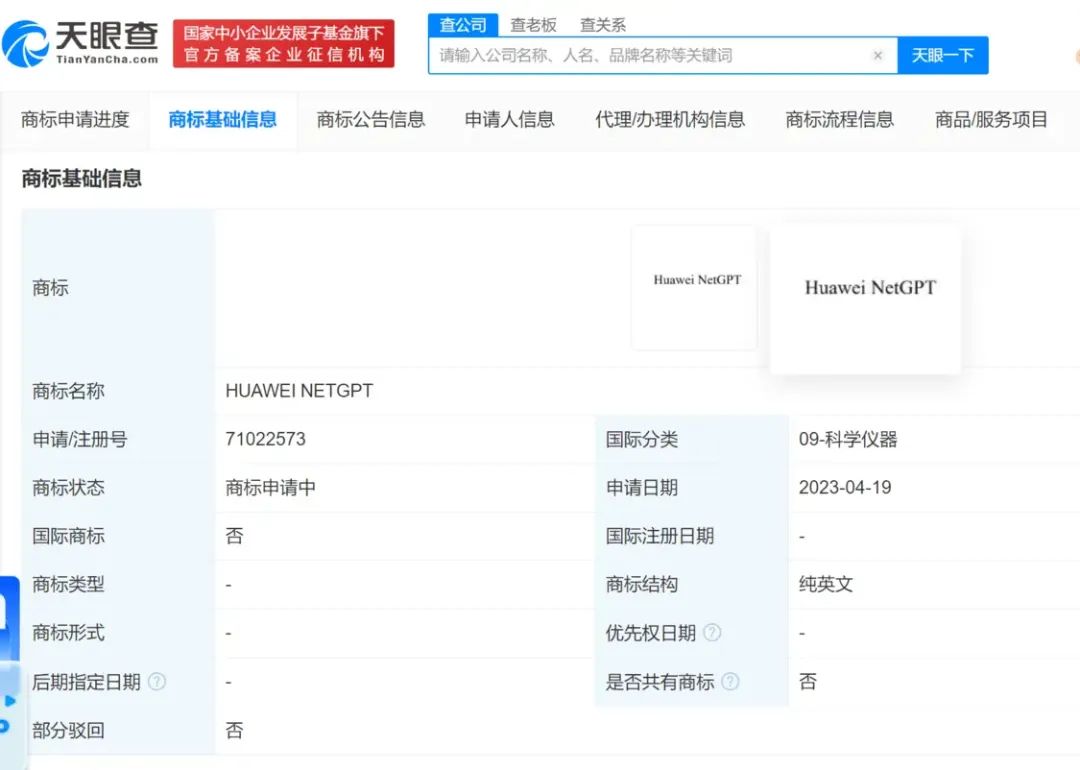
此外,华为已成功注册多枚“盘古”“PANGU”商标。
搞大模型,华为“完全没问题”
其实,盘古不算是华为的“秘密项目”。因为华为早就对外公开发布了盘古大模型,只是那时候还没有ChatGPT这个“惊爆点”出现。
最早,盘古于 2020 年 11 月在华为云内部立项成功。当时对于盘古大模型的定位,华为内部确立了三项最关键的核心设计原则:
一是模型要大,可以吸收海量数据;
二是网络结构要强,能够真正发挥出模型的性能;
三是要具有优秀的泛化能力,可以真正落地到各行各业的工作场景。
这之后,2021年4月华为云盘古大模型正式对外发布,后来又在2022年4月升级到2.0版本。
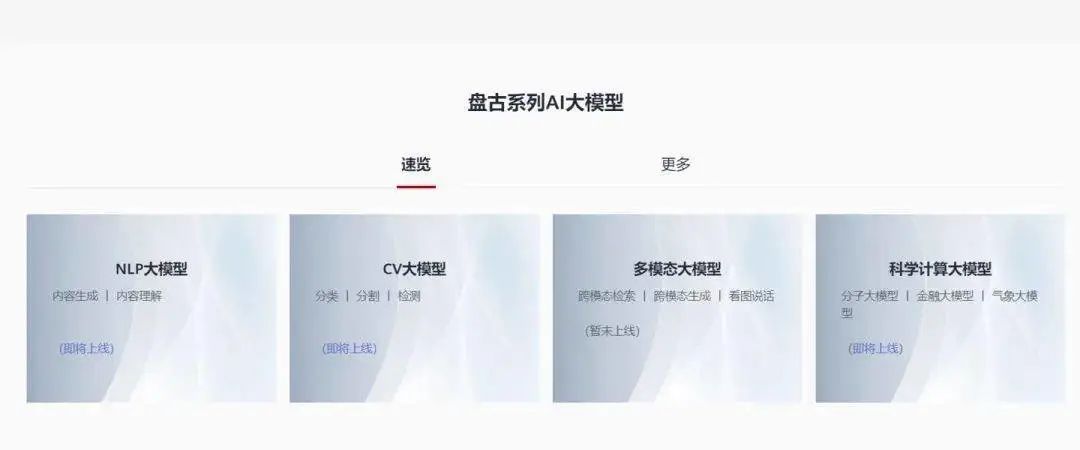
根据华为云高管的演讲 PPT 信息,目前华为“盘古系列 AI 大模型”基础层主要包括 NLP 大模型、CV 大模型、以及科学计算大模型等,上层则是与合作伙伴开发的华为行业大模型。
其中,即将现世的“盘古Chat”最核心的基础——盘古NLP大模型,其使用的算法和训练方式都是针对中文文本的,这可以盘古更能适应中文语境下的应用场景,也是业界首个千亿参数的中文预训练大模型。
这就不得不提科大讯飞之前发布的星火大模型了。星火拥有1000亿参数规模,和盘古在参数基础上相类似。科大讯飞最近称10月份,星火大模型将在中文能力上超越GPT。而它和盘古究竟孰强孰弱,到时肯定会番较量的。
目前,AI 大模型中的 NLP 大模型、CV 大模型以及科学计算大模型(气象大模型)均已被标记为即将上线状态。
华为对加入AI竞赛,有自己的想法。华为昇腾计算业务CTO周斌曾经被问到“是否有信心承载ChatGPT这类规模的应用”的问题。
他回答说,“我们已经服务了国内几十家合作伙伴的大模型,至少从底层技术软硬件的规模上来讲,华为不比ChatGPT少,ChatGPT所需的算力需求,我们已经经过了大规模验证,是完全没问题的。”。
据悉,此次开发者大会上要发布的“盘古Chat”主要面向To B/G政企端客户,但既然是开发者大会,内测资格肯定还是要发放的,具体功力如何,静待发布。
而同期发布的鸿蒙4.0,将会和盘古大模型产生什么化学反应,也是业内予以高度关注的焦点。
“先有华为后有天”,这句调侃的话在坊间流传甚广,菊厂内部没听过是不可能的。而“盘古”作为古代神话中“开天辟地”的大神,被华为用以冠名自己的AI大模型,此间含义不言则明。
