以太坊 2.0 主网事故回顾
ECN以太坊中国来源 |?Prysmatic Labs
作者 |?Raul Jordan
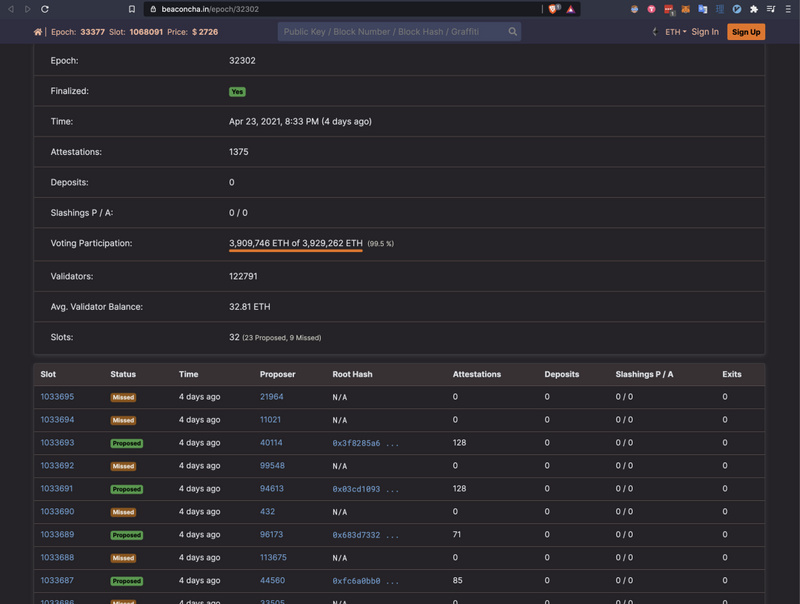
https://beaconcha.in/epoch/32302
事故概要
从 epoch 32302 开始,信标链丢失了大量区块提议。由于 Prysm 是 Eth2 客户端中用户最多的,因此问题最有可能出现在 Prysm 上。一段时间之后,我们在本地重现了该错误。这其实是我们已知的一个与 eth1 数据投票和验证者存款相关的问题。尽管之前已经有人向我们报告过此问题了,但是我们无法重现这个 bug 并将其视为孤立事件。而且这个问题从未在任何测试网或者主网中广泛传播过。这是该问题首次导致区块提议失败事故。
在这 18 个 epochs 内,几乎所有 Prysm 信标节点都无法生产新区块。Epoch 32320 又开始正常运行了,当时大家普遍认为该事故已经结束了。然而大约 24 小时后,该事故再次发生,造成了类似的影响。
关于此事故的正式事后剖析报告已发布,访问链接查看:https://docs.google.com/document/d/1nJr6_bd-UnLBxvhT8lcRYdAZr69QdVQ3zJNUr3LgW-0/edit
该回顾详细介绍了事故的时间线;分析了根本原因以及列出了 Eth2 质押者和参与者需要注意的问题。
影响
一些初步数据表明,第一次事故中,每个受影响的验证者平均损失 122950 gwei (按文章攥写时的价格计算为 0.3 美元)。而该次事故发生的 24 小时内,又发生了第二次相同的事故,每个受影响的验证者损失约为 0.22 美元。
一些关键事实:
??没有验证者被罚没
??对信标链的敲定没有影响
??参与率还是很高 (最低点也有 84.8%) (编者注,此数据与 Ben Edgington 编写的最新一期《Eth2 进展更新》有出入。)
??大多数验证者丢失 2 到 3 个证明,不管哪个客户端类型
??这次不像是一次恶意或故意的攻击
在整个团队经过大约 30 个小时的努力之后,我们诊断了其根本原因,并在 UTC 时间 4 月 25 日早上 6 点为所有 Prysm 节点部署了修复版本。在节点尚未完全升级之前,类似的事故仍发生了最后一次。给节点运行者足够的时间升级客户端之后,此类事故没有再发生过了,并且有证据表明该问题已得到完全解决。
问题解答
成为验证者的捷径此事故是否会削弱大家对 Eth2 的信心?
不会。该事故并没有造成共识失败,并且该事件的影响范围与 Eth2 主网的规模相比非常小 (在第一次事故中,每个受影响的验证者平均损失约 0.3 美元)。自创世以来,Eth2 一直都非常强大,验证者参与率非常高,并且每个 epoch 都完成了敲定。从我们的角度来看,故障解决了之后,网络有能力恢复到完美运行的状态,反而增强了社区对以太坊的复原能力的信心。
此事故是否会削弱大家对 Prysmatic Labs 团队的信心?我们对此次事故做出的反应和解决方法与此前我们处理 Eth2 测试网中的故障时完全不同。此次事故发生后,我们团队马上排除了错误信息;量化影响;以及在等待解决方案时,给验证者们列出了明确的应对步骤。再者,我们完全确定了解决方案之后,才去让大家升级客户端版本。值得注意的是,由于 Prysm 客户端是以太坊 2.0 网络中用户占比最大的软件,因此出现的任何 bug 都可能会引起更严重的问题。
对于核心开发者来说,工作的关键是要“约束复杂性” (bound complexity)。诸如 Eth2 之类的分布式系统具有如此多的变量,我们每个团队都尽一切努力以减少其出 bug 的可能性。当然,在这个的软件中,出现 bug 是不可避免的,并且我们承认,Prysmatic Labs 确实出错了。但是我们希望可以展现出我们团队解决问题的动力与能力,同时为验证者平衡速度和准确性之间的问题。
事故根本原因总结
Eth2 和 Eth1 链松散地连接着,Eth2 仅在验证者存款验证时需要用到 Eth1。也就是说,即使验证者对垃圾数据进行了投票,Eth2 PoS 链也可以继续运行。而唯一会影响到的事就是,新的验证者存款无法添加,直到 PoS 链再次对正确的 Eth1 数据进行投票。此“投票”是在“投票周期”中完成的,目前主网上将该周期设置为 64 epochs (大约 6.8 小时)。
投票的方式为一个简单的“绝对多数”原则,Eth2 验证者规范中有解释其运作方式。不幸的是,Prysm 在实行该原则 (按照绝对多数原则投票) 时,丢失了一些验证。该事故中,由于 Prysm 出现了 bug,导致一名区块提议者创建了一个完全无效的 Eth1 存款树根,而其他 Prysm 节点首先发现了该区块提议。随后,他们对此投了有效票,因为 Prysm 客户端遵循的是简单的“绝对多数投票”原则,而没有做明确的验证。
然后,所有 Prysm 节点”滚雪球“般地对无效信息投票,导致了区块提议者无法将具有存款的区块打包进链。这是因为,这些存款对节点的 Eth1 存款树根未进行验证,所以区块提议会失败。而在投票期结束之后,该问题就自动解决了,但如果 bug 未修复,将再次出现这种问题。
实际上,这次出现无效 Eth1 存款数据树根的根本原因是,存款缓存初始化中出现了 bug,但仅影响了使用 Prysm 客户端的一部分信标节点。这导致这些节点生产错误的存款树根,而其他 Prysm 节点对其进行投票,从而造成了此次事故。
事件时间线
注意,下面是技术细节!大家可以跳到下一部分,阅读解决方案以及该次事故带来的经验教训。
区块提议失败Epoch 32302 开始出现区块提议丢失的问题。
Nishant 通知了团队,并召开了全体会议。然后,我们通过本地的主网信标节点重现事故,并开始了调查。
调查显示,Prysm 对奇怪的、错误的 eth1 存款树根投票我们注意到 Prysm 的节点正对奇怪的树根投票,该默克尔根用于验证 PoS 链中的验证者存款合约的存款完整性。在公共浏览器上查看了最初的区块提议者的历史信息之后 (为了保护该验证者,就不公布其身份了),我们推断这并不是一起攻击事件。
排除法最初的怀疑是关于 Prysm 如何在验证者提议代码路径中处理 eth1 数据投票。尤其是,我们试图排除一些问题:
1.打包存款进区块这里有问题吗?
2.存款日志信息获取和 eth1 信息混了或者不确定吗?
3.我们的存款默克尔树出现问题了吗?
在接下来的 16 个小时左右,我们花费了大量的时间共同努力诊断潜在的问题。我们梳理了代码行,试图通过单元测试来重现故障过程,并尝试了各种方法。尽管我们已经有了一个潜在的解决方案,我们也因缺乏信心而对发布修复版本而紧张。
较合理的根本原因此前在处理 Eth2 测试网中的 bug 时,我们得到了一些经验教训,光对根本原因有信心是不够的。在高风险的情况下,在向用户公布解决方案之前,我们需要有 100% 的信心。在事故发生后 28 小时,我们坐下来并问自己:”我们还有什么是不知道的呢?我们还可以问什么问题来让我们更接近发生故障的根本原因呢?”然后我们知道了以下几点:
1.我们的稀疏默克尔树 (sparse merkle tree) 实现并没有严重的 bug,因为它使用主网和 Prater 测试网的存款,与 Lighthouse 和 Protolambda 的 Eth2 zrnt 实现相匹配。
2.我们用于从 Eth1 节点检索 Eth1 数据的代码路径没有 bug,也没有返回不正确的数据。
我们不知道的有:
1.无效的存款树根是如何产生的
2.为什么这个问题在一些节点中是可以重现的,而其他节点不可以
3.为什么 Prysm 节点在确定区块中的存款数量时,出现了”off-by-one“错误
修复问题为了回答这些问题,我们看了初始化我们的存款树的代码路径。结果发现,在早期添加了一个缓存层以避免质押者每次启动他们的节点时都必须下载所有验证者存款记录。此外,我们添加了一个新功能——在客户端内部可以从一个内嵌的创世状态中启动 Prysm。在填充缓存时,我们存款树的一个错误预设导致信息的讹误:

问题根源
事实证明,如果我们的存款树是空的,函数 len(items) 将始终返回 1。这意味着当实际上我们应该把?lastReceivedMerkleIndex?的值设为 -1 时,我们会把它设为 0。上面的代码会导致一些在该代码路径的 Prysm 节点跳过把第 0 笔存款嵌入到树里。我们代码库的其他部分都指向问题出在我们存款树实现的这个奇怪部分,而不是这个代码路径。
为了检验这个假设,我们尝试使用 Protolambda 提供给我们的测试夹具尽可能地复制代码路径。我们直觉我们漏了将第 0 笔存款嵌入到存款树。当然,我们能够在一个可重复的测试中找到导致整个事件发生的、有问题的存款树根!然后,我们围绕该代码路径添加条件,以避免该条件再次出现,并准备推出最终确定的修复版本。

问题解决
根本原因总结??Prysm 把 eth1 数据保存在磁盘上,以防止用户在每次重启进程时都必须对验证者存款合约日志发出请求。
??如果一个节点重启并把 eth1 数据保存在磁盘上,我们会从这些数据初始化我们的存款缓存,但由于我们的稀疏默克尔树 (sparse merkle tree,SMT) 协助程序包的工作方式与从磁盘上的数据初始化此缓存的代码路径不相同,我们会跳过把第 0 笔存款嵌入存款树,造成无效存款树根。这个代码路径只影响那些创世以来还没有数据库的节点,后来被修复了。
??在官方规范里,Prysm 节点遵循“绝对多数”的原则执行一个 eth1 数据投票算法,但是,Prysm 并没有完全实现该算法的一些有效条件。Prysm 节点随绝对多数 eth1数据投票进行投票,该投票数据引用的是一个现存的区块根,这可能导致 Prysm 节点投票给一个由有问题的存款树生成的存款树哈希值,因为这些存款是未被验证的。
??由于网络里大部分的节点都是 Prysm 节点,随绝对多数原则投票给有问题存款根这个问题的滚雪球效应发展成一个严重问题,因为 Prysm 节点在随后一段时间里无法在主网上生成区块。
??一旦 eth1数据投票期重置了,Prysm 节点又可以正确地提议区块了,直到在未来又遇到该漏洞。
解决方案在北京时间 4 月 25 日周日 13:00,在不确定性中煎熬了多个小时后,我们发布了对该问题的修复。我们对这个解决方案有十足的把握,并非常有信心在节点升级后,该问题在 Eth2 中不会再出现。
吸取教训
??在事件中,对我们的解决方案有信心和与外界的谨慎沟通是至关重要的当我们遭遇 Eth2 的 Medalla 测试网事故时,我们上了关于良好沟通的价值的重要一课。每个公共评论和语言的精确表达都会对事件的结果产生严重影响。在测试网的事件里,我们以为一个立即的解决方案是通过公共渠道告诉大家“重启你们的节点”。这个草率的决定导致网络上大部分的节点都掉线了,然后争先恐后在一堆坏的对等节点里找好的,以实现与区块链的同步。此外,我们很快发布了一个没有 100% 信心能解决问题的软件升级热补丁。这给系统带来更多的混乱,并造成节点运行商对解决方案的疑虑。
相较之下,在这次主网新事故的整个过程里,我们一直注意慎重与精确的沟通。另外,在我们对问题的根源和解决方法有 100% 的信心之前我们没有发布热补丁。
??保持耐心与冷静有助于解决问题
我们团队经过了过去几年构建 Eth2 ,学到了如何在面对逆境时保持冷静。我们相信在解决问题过程中,保持冷静、频繁交流状态报告、确保团队感受到支持和正面的反馈是非常重要的。我们能够花时间收集尽可能多的证据,并与我们的用户进行细致的合作,我们将成功解决这个问题。更重要的是,我们在开始时就花时间对事件影响进行量化,以减少质押者与因缺乏信息而产生的忧虑。这个教训对在高度紧张与睡眠不足的情况下工作非常重要。慢下来,用适当的方法解决它,并不惜一切代价避免把问题弄得更糟。
??Eth2 测试网不等于主网
对于 Prysm 客户端,我们在公共 Eth2 测试网中对 Prysm 产品前的候选版本进行了广泛的测试和监听。Prater 和 Pyrmont 测试网都是用户在加入到 Eth2 主网前用来测试他们的设置的好工具。但是,这些测试网都预设四个产品级 Eth2 客户端的占比是接近平均分的,即没有哪个客户端在验证者中有明显的多数份额。不幸的是,这可能没有考虑到当某个客户端为大多数人所使用时才会出现的漏洞。在未来,Prysmatic Labs 会在一个更接近主网环境、或一个 Prysm 网络节点 50% 的环境里进行内部测试网里进行测试。
此外,我们建议其他客户端也在它们自己的内容测试中加入这样的环境,在它们成为大多数客户端的时候,它们也可以了解自己客户端的潜在问题。
质押者应该思考什么
为什么使用 Prysm 客户端做质押

https://launchpad.ethereum.org
人们选择运行 Prysm 时因为从一开始我们团队已经专注于使他们参与以太坊质押的体验更简单。我与我们的用户沟通过很多次,很多人选择一个客户端不是因为微观上的优化或与其他客户端相比相对小的收益差别,而是因为我们使得他们的体验更简单——良好的文档资料,一直给所有的社区成员提供重要的帮助。对于新手来说 Eth2 是可怕的,质押也充满不确定性和风险。我们团队的使命是让用户知道我们在他们身边,以及无论他们的问题多小都会得到我们的支持。特别地,我们一直关注那些可能对命令行不太熟悉、不太了解 UNIX 操作系统的普通质押者。
在未来,你可以对我们团队有以下期待:
??提高实现规范条件的准确性,确保预设和有效条件在任何代码被写入前都被充分审核和质疑
??我们不因要提高这个体验,还要加倍努力,使 Prysm 比今天提升很多倍,使使用我们客户端的质押者更容易参与网络,包括网页界面的改进。
??Prysm 将在研发方面加倍努力,在 eth1 <> eth2 的合并前提供关键的功能与改进。
??我们相信健康的竞争能形成一个强大的激励机制,推动 ETH 的权益证明能有更多人参与,也因此更安全,因为所有客户端团队都不断改善他们的软件
??我们团队致力于以最高的专业水准来解决和质押者可能会遇到的问题。我们相信我们做好处理我们路上会遇到的任何问题,并向我们的社区保证我们会把质押者体验作为我们的最高优先级。
??最后,我们相信还有很多重要功能可以使 Prysm 变成参与 Eth2 的、更有吸引力的软件,我们将朝着这个目标不断迭代
??Prysm 有一些验证者收益的高级优化还没对所有质押者设为默认启动。我们相信这些功能发布后,Prysm 的质押者会看到最高水平的收益。
回顾客户端多样性的对话
自 Eth2 创世以来,我们一直听到的一个共同主题是客户端多样性。Eth2 是一个有世界各地的人作为验证者参与的分布式系统。不同人用不同的软件参与到区块链的共识里,如果某个软件出现严重问题,如果运行网络的客户端实现由一个平衡分布的话,影响会更小。
Leonardo Bautista-Gomez 早在一月的时候公布了一份数据分析,结果现实 Prysm 节点占网络的65%,此次事件也显示 Prysm 验证者在今天占了大多数。
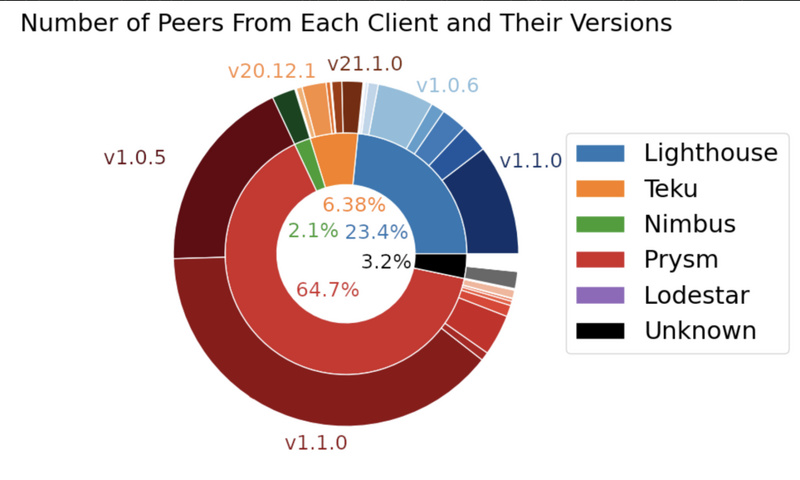
https://github.com/leobago/BSC-ETH2/tree/master/armiarma
我们建议你们客观地看待每个客户端:它的软件、它的社区、还有它的韧性,然后决定选哪个软件及其背后的团队是最适合你的需求的。如果某个 Eth2 客户端缺少了对你来说很重要的东西,者正式你不选他们的客户端的理由,我们强烈推荐你提出一个功能请求。Prysmatic Labs 会继续专注于帮助你参与到以太坊网络,并推动区块链软件的边界。
如果你想沟通和对本文由疑问的话,请加入我们的Discord。
参考
? 事件的沟通 https://www.reddit.com/r/ethstaker/comments/mxpz57/regarding_the_recent_beacon_chain_incident/
? 事后检讨报告 https://docs.google.com/document/d/1nJr6_bd-UnLBxvhT8lcRYdAZr69QdVQ3zJNUr3LgW-0/edit?usp=sharing
? Medalla 测试网事件 https://medium.com/prysmatic-labs/eth2-medalla-testnet-incident-f7fbc3cc934a
https://medium.com/prysmatic-labs/tagged/blockchain)
原文链接:https://medium.com/prysmatic-labs/eth2-mainnet-incident-retrospective-f0338814340c


