Meta猛攻CV,发布超强SAM抠图模型,可拯救元宇宙?
巨头们正在 AIGC 领域上激战,Meta在“计算机视觉(Computer vision,CV)”领域有了大动作。
本周三,Meta 研究部门发布了一篇名为其 “Segment Anything(分割一切)”的论文,文中介绍了一个全新的 Segment Anything Model(即SAM),可以用于识别图像和视频中的物体,甚至是从未被 AI 训练过的物品。
所谓的“图像分割”,通俗来讲就是抠图。Meta此次所展示的 AI 抠图能力,被认为是计算机视觉的 “GPT-3 时刻”,强到 CV 工作者直呼:AI 来抢饭碗,准备下岗了。
强在哪里?
如果你亲自尝试过抠图,即使借助了市面上较为成熟的“智能抠图”工具,你依然发现,想把照片抠得快、抠得准、抠得自然是件费时费力的事。
Meta此次发布的 SAM 给出了近乎完美的解决方案。
SAM 的第一项重大突破在于“识别速度和精度”有了显著提升,而速度和精度是计算机视觉领域的经典且复杂的任务。
SAM 的另一惊艳点在于,它并不局限于训练过的数据集,在遇到从未见过的物品和形状,SAM 也能将其准确识别并分割出来。
此外,SAM 支持用户使用交互性方式分离物体。比如经鼠标定位自动识别物体轮廓。即使是颜色非常相近、甚至连人眼都难以快速分辨的倒影,SAM 都能非常准确的找出轮廓边线。
用户还可通过“关键字查询”,SAM 可监测并标记出这个图片中的搜索对象。
还能支持对图片上物品的编辑。比如,识别出一张图片上模特的服饰,抠出来便可以改变颜色和尺码大小。
SAM 不仅仅能处理静态图片,还可以对动图、视频中的取片进行准确识别,并快速标记、统计出品类、大小和颜色等信息。
从静态图片中“抠”出来的椅子,进行3D渲染和编辑,让它动起来,还可以继续改变形状等创意操作。
未来,这一技术将和 Meta 的 AR/AR 头显进行广泛结合,助力元宇宙,将电影中的钢铁侠头盔将推向生活场景。
将有更大应用空间
SAM 发布之后,很多人第一时间进行了实测,一些网友还结合自身的工作领域打开了 SAM 更广的应用想象空间。
自然科学研究者——将SAM和卫星图像结合在了一起,表示SAM能够很好的识别和找到他标记的风貌类型。
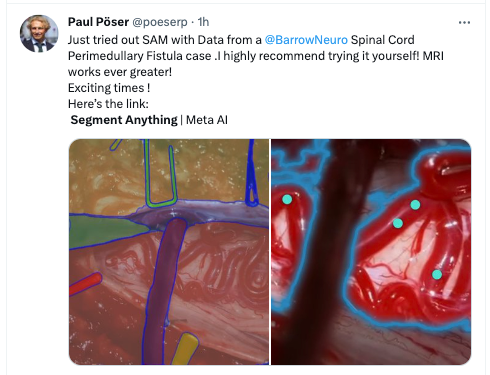
神经外科影像学从业者——将SAM用到了一个脊髓血管病的病例文件之中,认为SAM在帮助判断和分析病情上有很大帮助。
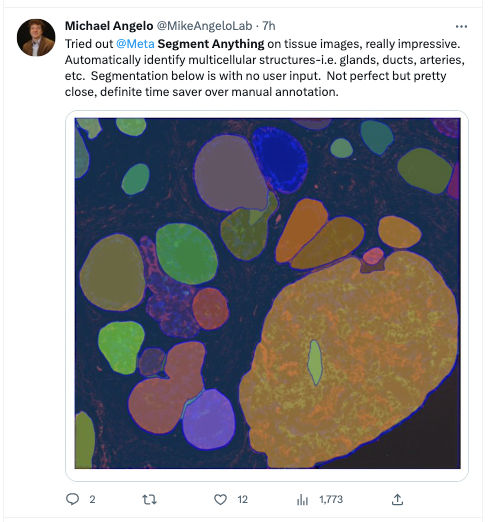
生物学家——输入一张显微镜下的组织图片,即使图中形状特征毫无规律,SAM也能够自动识别多细胞结构中的腺体、导管、动脉等,SAM 在未来能够节省大量手动注释的时间。
骑行爱好者——将地图和SAM结合起来,认为能够帮助自己未来更快更高效地给地图做标记。
农场管理者——借助 SAM 监管农场动物,进行作物培植生产研究等。
AI研究专家——英伟达人工智能科学家 Jim Fan 表示 SAM 已经基本能够理解“物品”的一般概念,即使对于未知对象、不熟悉的场景(例如水下和显微镜里的细胞)。
SAM 之于计算机视觉,就像是 GPT 之于大语言模型。
论文解读
在 Meta 的论文《Segment Anything》中,新模型全名为Segment Anything Model,图像注释集名为Segment Anything 1-Billion (SA-1B),据称这是有史以来最大的分割数据集。

论文地址:https://arxiv.org/abs/2304.02643
此前解决分割问题大致有两种方法。第一种是交互式分割,第二种是自动分割。前者需要人通过迭代完善一个遮罩来指导模型,后者需要大量的手动注释对象来训练。两种方法都无法实现全自动的图像分割。SAM 很好的概括了这两种方法,可以轻松地执行交互式分割和自动分割。
本篇论文中,研发人员提到了SAM 的灵感来源于自然语言处理领域。在 NLP 领域,基础模型可以使用prompting技术对新数据集和任务执行零样本和少样本学习。
而在CV领域,具体到 SAM 中,研究人员训练的 SAM 可以针对任何提示返回有效的分割掩码。提示可以是前景、背景点、粗框或掩码、自由格式文本等等能指示图像中要分割内容的任何信息。
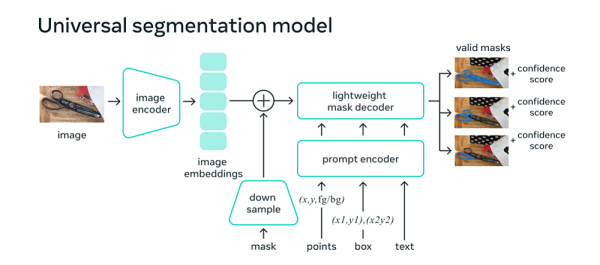
在Web浏览器中,SAM有效映射图像特征和一组提示嵌入来生成分割掩码
除了新模型 SAM,Meta还发布了迄今为止最大的分割数据集 SA-1B。
数据集由 SAM 收集,此数据集已是迄今为止最大的数据。注释员使用 SAM 交互式地注释图像,然后新注释的数据反过来更新 SAM,重复执行此循环来改善模型和数据集。
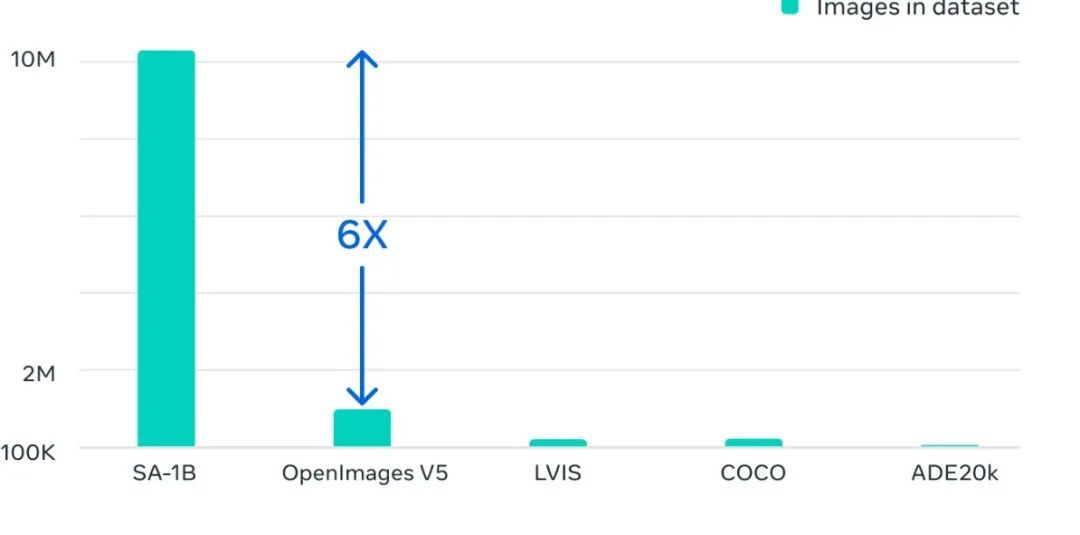
SA-1B 图像数据集包含超过11亿个掩码,这些掩码是从1100万张已经获得许可、并且保护隐私的高分辨率图像中收集的,这些图像的分辨率达到了1500×2250 pixels,平均每张图像约有100个掩码。甚至可以媲美以前规模小得多、完全手动注释的数据集中的掩码。
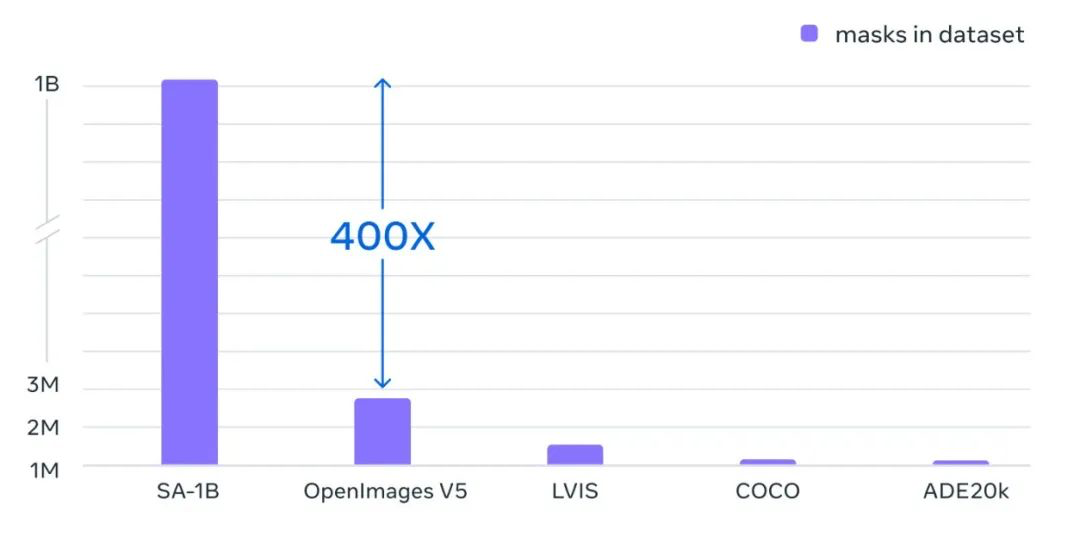
Meta 官方称,通过在业内共享这项研究和数据集,进一步加速对分割图像视频的研究,为AR/VR、内容创作、科学领域和更普遍的 AI 系统等领域的强大组件,释放出更加强大、通用的人工智能系统。
