大厂齐刷刷跟进ChatGPT,为何只有百度做出了文心一言?
一见财经
这些年,互联网大厂们齐刷刷的对一种技术浪潮表态,一共有两次。
一次是2018年“中兴事件”后,大厂们纷纷表示,要掌握核心技术,积极“造芯”;另一次是前一段时间,ChatGPT大火之后,大厂们的人工智能热情被点燃。
一见财经注意到,就在两三天时间内,大厂们纷纷向外界透露了自己的类ChatGPT研发计划。
2月7日,百度官宣将在3月上线文心一言(ERNIE Bot),称公司在文心一言的底层模型“文心”系列上已布局多年,“ChatGPT相关技术,百度都有”。
2月8日,阿里巴巴一名资深技术专家爆料,阿里达摩院正在研发类ChatGPT的对话机器人,目前已开放给公司内员工测试。
同日,科大讯飞在投资者互动平台回应称,ChatGPT主要涉及到自然语言处理相关技术,公司在该方向技术和应用具备长期深厚的积累。
2月9日,腾讯对外回应称,公司目前在相关方向上已有布局,专项研究也在有序推进。
短短数日,“ChatGPT热”席卷了几乎所有的国内互联网大厂,好像不和ChatGPT沾点边,公司就不属于互联网科技公司了。
但很多人发现,明确表态推出具体产品的只有百度。
不是喊口号
除了大厂们积极表态跟进,“ChatGPT热”也烧到了资本圈, ChatGPT热度不减,相关概念股受到资本追捧,股价涨幅较大。
2月8日,海天瑞声临近尾盘20%涨停;云从科技自1月30日以来的八个交易日内收获了三个20%涨停板。
不过,几天之后“ChatGPT概念股”股价相继回落,原因之一是个别公司存在炒概念的情况,根本就没有实际产品。
比如,自称“人工智能服务器领域市占率位居全球AI服务器市场第一”的浪潮信息在不到两个月的时间里股价接近翻倍,但最近面对监管机构的问询函,公司称相关应用与ChatGPT存在差距,存在短期内无法大规模落地行业应用的风险,且相关应用尚未产生实际收入。
而该公司此前曾表示,公司于2021年发布的“源1.0”超大规模预训练自然语言模型,结构与GPT-3类似,与GPT-3相比参数量增加40%,训练数据集提升10倍,达到2457亿参数。
分析人士指出,要搞出中国的ChatGPT,并不是通过喊口号就能实现的,既需要雄厚的财力、人才储备,更需要长期的技术沉淀。
ChatGPT表面上看是一款聊天机器人,但他是基于全世界最强大的大语言模型之一GPT-3,该模型由1750亿个统计性联系组成,在约三分之二互联网、整个维基百科和两个大型图书数据中集中训练。
从目前各公司公布的进展看,百度决心最大,而且有成型的产品,这和百度这些年在该领域的深厚技术积淀有很大关系。
ChatGPT受关注,本质上是其背后的公司OpenAI在NLP(自然语言处理)技术领域获得了突破,再加上采取了通过聊天的形式来训练,获得了全球追捧。
NLP被称为“人工智能皇冠上的明珠”,其实百度很早就开始NLP方面的研究了,在百度诞生时,百度处理用户的第一次搜索开始,NLP技术就成为搜索技术的重要组成部分。
2010年初,百度对NLP的工作进行了重新梳理与规划,成立百度自然语言处理部。
2013年,百度设立深度学习研究院,连投十年,超过1000亿元。2018年,百度将深度学习平台“飞桨”升级为操作系统(文心一言的支持系统),并不计成本投入人力财力。
2019年3月,百度提出知识增强的语义理解框架ERNIE(文心一言的前身),在深度学习的基础上融入知识,同时具备持续学习能力,曾一举登顶全球权威数据集GLUE榜单。
2021年9月,百度发布了PLATO-XL,这是全球首个百亿参数的对话大模型,一举超过Facebook的Blender、谷歌的Meena和微软的DialoGPT。
现在,该模型已更新迭代至文心ERNIE3.0,参数规模高达2600亿,几乎比谷歌LaMDA(1350亿)高了一倍,也高于ChatGPT(1750亿),是全球最大的中文单体模型。
“目前在国内公司中,豪不夸张的说,没有一家公司的水平接近百度。”有业内人士指出,百度之所以敢明确表示推出文心一言,是因为已经在这个领域默默耕耘了十几年。
需要硬实力
ChatGPT的背后是大语言模型,而大语言模型背后则包含底层芯片、深度学习框架、海量数据、强大的算力以及雄厚的资金实力。
2月13日,原美团联合创始人王慧文在朋友圈发文:5000万美元,带资进组,不在意岗位、薪资和title,求组队。
海通证券分析师郑宏达第二天就表示:“5000万美元够干什么的?大模型训练一次就花500万美元,训练10次?”言外之意,要搞中国的ChatGPT,一定是非常烧钱的。
其实,OpenAI创立之初就得到了来自硅谷很多大佬在资金上的支持,比如埃隆·马斯克、彼得·泰尔、雷德·霍夫曼等,2019年7月,微软还对OpenAI进行了10亿美元投资。
一见财经相信,国内能拿出巨资搞中国ChatGPT的互联网巨头不在少数,但有钱只是第一步,搞人工智能最关键的在于算法、数据和超强的算力。
360公司董事长兼CEO周鸿祎最近指出,拥有技术积累的企业才能搭上这辆车,“没有在服务器、算力上投入,也没有AI团队的企业,宣布入局都是在蹭热度。”
OpenAI背后,有微软为其提供资金和超强算力,有GPU巨头英伟达提供高性能AI芯片,而OpenAI主要专注于算法和大数据模型。
目前,在国内能集齐以上超能力的,放眼望去可能只有百度,百度在人工智能四层架构中有全栈布局,包括底层AI芯片、深度学习框架、大模型以及最上层的搜索等应用,而文心一言则位于模型层。
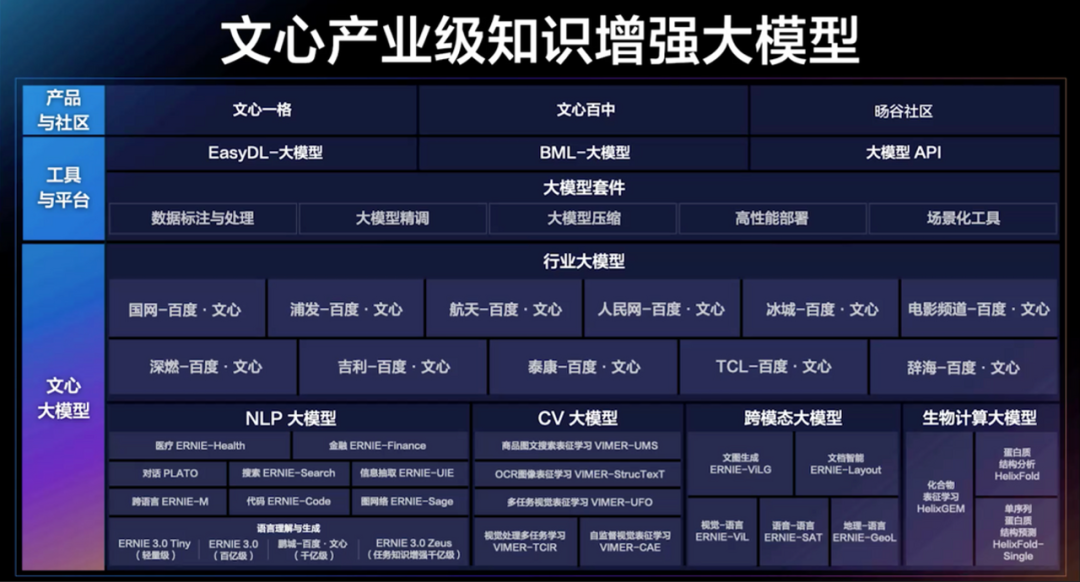
百度的文心大模型和OpenAI的GPT模型类似,2019年就已经推出,并且已经迭代了多代,从单一的自然语言理解延申到多模态,包括视觉、文档、文图、语音等。
最新发布的ERNIE3.0 Zeus迭代于ERNIE3.0,拥有千亿级参数。其已经具备智能创作等各类自然语言理解和生成能力。
算法方面,百度拥有多个超算集群。百度还自研了AI芯片“昆仑”,已在多场景实际部署。
深度学习框架层面,百度飞桨平台在2022年底已凝聚535万开发者,基于飞桨创建了67万个模型,服务20万家企事业单位。
数据层面,百度的搜索业务本来就积累了很多数据,其在用户需求理解方面有比较明显的优势,这些数据都能支撑ERNIE bot(文心一言)的充分预训练,而随着3月文心一言上线公测,这个模型可能会被训练的更聪明。
中金互联网行业首席分析师白洋最近表示:“AI的三要素包括算力、算法和数据,我们认为百度在这三项上拥有领先优势。”
“文心一言”或重塑百度
ChatGPT火爆初期,有人预测会革了搜索的命,谷歌内部拉响“红色警报”,没几天就宣布推出名为“Bard”的AI聊天机器人。
在国内,也有观点认为,百度搜索业务也可能会受影响。但深入研究发现,百度和谷歌不同,面对ChatGPT谷歌是被威胁者,而百度是受益者。
今年以来,百度股价飙升了近36%,而在2月7日百度官宣“文心一言”的消息时,百度股价当天收盘涨幅超过15%,创下自去年2月以来的历史新高。
国盛证券在研报中称,百度在人工智能端具备从芯片到应用的全栈技术布局,在自然语言处理领域的积累深厚,同时AI大模型在其他领域也有应用落地。
分析人士指出,在“文心一言”的应用上,百度的思路有点像微软。
微软除了将ChatGPT与Bing搜索结合,还将OpenAl的多项技术模型引入Azure云服务中,并在Ofice、Teams和安全软件中采用更多的OpenAl技术。
中金公司在研报中预测,百度通过其生成式AI产品文心一言,面向B端提供标准化Al能力,助力企业智能化转型。
“百度股价弹性来自于云、AIGC和自动驾驶等新业务,若对标OpenAI目前的估值290亿美元左右,百度的技术和商业实力不弱于OpenAI。”中金公司在研报中称。
据了解,目前已有接近三百家企业接入文心一言Al能力。
另外,在近期流出的一份百度内部讲话中,百度CEO李彦宏指出,ChatGPT是AI技术发展到一定阶段后的新机会,技术已经到了临界点。百度已经宣布将为百度搜索升级“生成式搜索”能力,为用户开放式的搜索提问或定制化的信息需求“创作答案”。
百度最新发布的2022年财报显示,实现营收1236.75亿,净利润206.8亿元,同比增长10%,其中第四季度营收330.77亿元,净利润53.71亿元,同比增长32%。
另外一个值得注意的数据是,2022年百度核心研发费用达到214.16亿元,占百度核心收入比例达22.4%,已连续九个季度超过20%。
这些年百度一直在加大技术方面的研发投入,有些技术虽然短期看不到效果,但是长远来看,成果正在显现,比如“文心一言”、自动驾驶、AIGC等都是厚积薄发的成果。
有人说,在国内互联网大厂中,百度对AI的投入是马拉松式的,所以能做出文心一言也就不奇怪了。
