“AI大模型”已经成创业热点
Ai芯天下前言:
ChatGPT热潮涌动,正处于冷静期的人工智能投资和产业布局迎来小阳春。
这也意味着[AI大模型的元年]来了,这场大模型之战,参赛选手不止巨头,也不会是只有一两个幸存者的生存游戏。
作者 | 方文三
图片来源 | 网 络
AI大模型已经成为创业热点
2012年,李志飞选择回国,在语音交互领域创业,创立出门问问。
前商汤科技副总裁、通用智能技术负责人闫俊杰已进军多模态AI大模型领域,于2021年11月成立人工智能公司MiniMax。
MiniMax从底层做起,形成了文本到视觉(texttovisual)、文本到语音(texttoaudio)、文本到文本(texttotext)三大模态的基础模型架构。
这可能是国内第一家同时拥有3个模态大模型能力的创业公司。
在toC方向,其首款AI虚拟聊天社交软件Glow推出四个月已经积累数百万用户;在toB方向,MiniMax计划在今年对外开放API。
Glow的基本玩法是在应用中创建虚拟AI机器人,可以根据用户意愿赋予其性格,实现实时沟通、互动并建立情感连接。

助推AI应用走向具体落地
如果将AI比作电力,那么大模型则相当于发电机,能将智能在更大的规模和范围普及。
大模型的智能能力在未来将成为一种公共基础资源,像电力或自来水一样随取随用。
每个智能终端、每个APP,每个智能服务平台,都可以像接入电网一样,接入由IT基础设施组成的智力网络,让AI算法与技术能够更广泛地应用于各行各业。
最底层是AI通用大模型,上面可以做AIGC,比如说Midjourney可以画画,Jasper可以写文案等;
也可以基于底层模型做对话机器人,比如基于ChatGPT。
在美国,除了OpenAI和巨头,还有另外三、四家创业公司也都在做AI通用大模型,都有大几亿美金的投入。
首先它有超强的语言能力,在学习语言的过程中,也学习了很多知识和逻辑。
模型学会了非常底层的结构和机制。万物都是自然产生的,语言也好,生物结构也好,它一定符合某种我们目前难以解释的规律。
模型经过互联网上所有的数据训练之后,它也获得了某种属于自己的解读方式。
现在的通用大模型,即使进行了微调后,依旧可以做多个任务。
预训练的核心是让它有基础的认知和逻辑能力,通过微调引导,让它能够在各项任务上处理得更好,知道怎么使用已有的知识。
国内公司与机构竞相研发
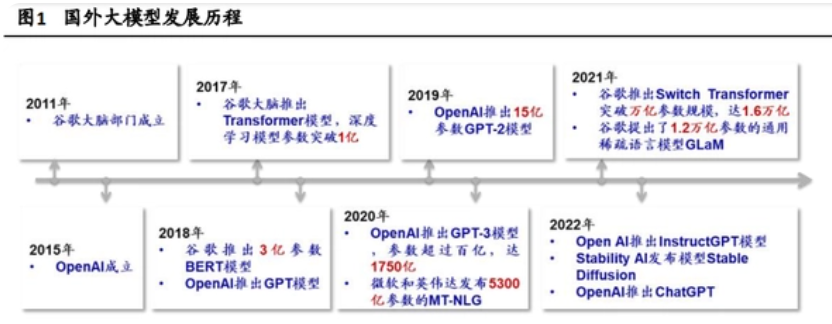
AI大模型先后经历了预训练模型、大规模预训练模型、超大规模预训练模型三个阶段,参数量实现了从亿级到百万亿级的突破。
国外的超大规模预训练模型起步于2018年,并在2021年进入[军备竞赛]阶段。
而在国内,超大模型研发展异常迅速,2021年成为中国AI大模型的爆发年。
2021年,商汤发布了书生(INTERN)大模型,拥有100亿的参数量,这是一个相当庞大的训练工作。
在训练过程中,大概有10个以上的监督信号帮助模型,适配各种不同的视觉或者NLP任务,截至2021年中,商汤已建成世界上最大的计算器视觉模型,该模型拥有超过300亿个参数;
同年4月,华为云联合循环智能发布盘古NLP超大规模预训练语言模型,参数规模达1000亿;
联合北京大学发布盘古α超大规模预训练模型,参数规模达2000亿。
阿里达摩院发布270亿参数的中文预训练语言模型PLUG,联合清华大学发布参数规模达到1000亿的中文多模态预训练模型M6;
7月,百度推出ERNIE3.0知识增强大模型,参数规模达到百亿;
10月,浪潮信息发布约2500亿的超大规模预训练模型[源1.0];
12月,百度推出ERNIE3.0Titan模型,参数规模达2600亿。
而达摩院的M6模型参数达到10万亿,将大模型参数直接提升了一个量级。
2022年,基于清华大学、阿里达摩院等研究成果以及超算基础实现的[脑级人工智能模型]八卦炉(BAGUALU)完成建立。
其模型参数模型突破了174万亿个,完全可以与人脑中的突触数量相媲美。
2021年12月,百度发布了全球首个知识增强千亿级大模型——鹏城-百度·文心大模型,产业级知识增强[文心大模型]系列大模型也正式对外。
百度文心大模型正从技术自主创新和加速产业应用两方面,推动中国AI发展更进一步。
2022年11月,百度发布了文心大模型的最新升级,包括新增11个大模型,大模型总量增至36个。
部分公司中国公司虽然目前还没有正式推出自身大模型产品,但是也在积极进行研发。
云从科技的研究团队高度认同[预训练大模型+下游任务迁移]的技术趋势,从2020年开始,已经陆续在NLP、OCR、机器视觉、语音等多个领域开展预训练大模型的实践。
以商汤科技的书生(INTERN)为例,在分类、目标检测、语义分割、深度估计四大任务26个数据集上,基于同样下游场景数据(10%)。
相较于同期OpenAI发布的最强开源模型CLIP-R50x16,平均错误率降低了40.2%,47.3%,34.8%,9.4%。
实现从[手工作坊]到[工厂模式]的转变
在深度学习技术兴起的近10年间,AI模型基本上是针对特定应用场景需求进行训练的,即小模型,属于传统的定制化、作坊式的模型开发方式。
这意味着除了需要优秀的产品经理准确确定需求之外,还需要AI研发人员扎实的专业知识和协同合作能力完成大量复杂的工作。
模型无法复用和积累,同样导致了AI落地的高门槛、高成本与低效率。
而大模型通过从海量的、多类型的场景数据中学习,并总结不同场景、不同业务下的通用能力,学习出一种特征和规则,成为具有泛化能力的模型底座。
由此利用大模型的通用能力可以有效的应对多样化、碎片化的AI应用需求,为实现规模推广AI落地应用提供可能。
大模型相对于传统AI模型开发模式在研发时拥有更标准化的流程,在落地时拥有更强的通用性,可以泛化到多种应用场景;
并且大模型的自监督学习能力相较于传统的需要人工标注的模型训练能够显著降低研发成本,共同使得大模型对于AI产业具有重要意义。

结尾:
热潮已经袭来,有技术基础的企业在强势突围,没有技术基础的企业准备发力,尚待进场。
而等热潮退去,能否留在场上,还需看清自己的优势和短板。
中国要有自己的通用自然语义大模型,它需要有为全球通用人工智能提供中国智慧、中国价值体系和中国方案的愿景;
需要从语料库选择、模型建构与训练、参数调整的全过程前置规避风险和法律、道德与伦理问题,更需要的是定力和耐心。
无论如何,它不能投机。
