SwarmV1.0 - 终章(上)
WantPool前言
Swarm主网已经正式上线5天多了。对于节点收益的问题,如果对我之前文章有关注,应该知道缘由,一切其实在Swarm团队解释清楚激励设计那天起都已经明了。
对于如今1.0版本,在官方确认了不可能在修改白皮书的情况下,个人觉得很多事情已经可以下结论了。
在下结论前,让我们重新回顾下第一篇文章到现在的所有。
回顾背景
Swarm究竟要干什么,我们都知道他要做的是一个存储和通信的基础设施,但他们对未来愿望是什么?是“power the next generation of censorship resistant, unstoppable serverless apps.”看看他们说得多么的霸气外露,是要给下一代抗审查,不可阻止的无服务器应用充能。
为什么要做抗审查,无服务器的东西?
如果你看了我第一篇文章,你肯定了解了Web1.0,Web2.0的大致问题和优势,在我们身处的时代,我们见证了网络大爆发从数据满天飞到数据被中心化、被平台化,给控制。整个网络在我眼里是在收缩的,他不再是一片热土,不再是“法外之地”,而对于Freedom大于一切的极客老外来说,这是更加不能容忍的,所以不被审查是第一要素。
Swarm = BT+Whisper+Layer2
在官方宣布将激励部分大部分部署在Xdai链上时
我给Swarm的定义是:
Swarm = BT+Whisper+Layer2
BT
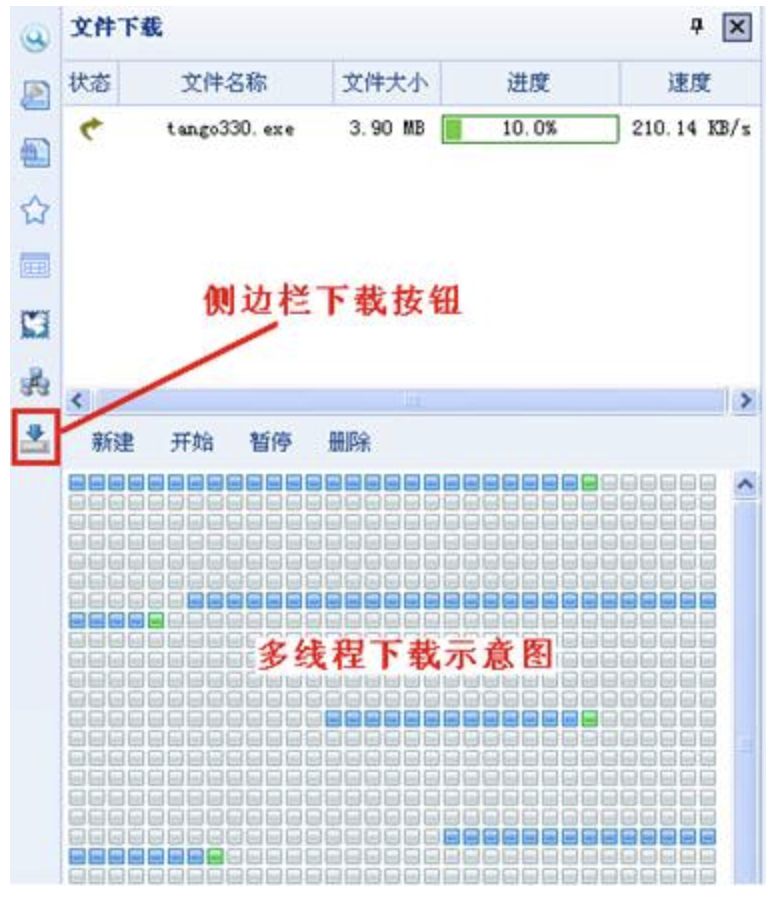
BT协议也是在第一篇文章时就提到过,如图,是的,有没有很感动?看那图片上一个个的小格子,回到年少时。那些格子就是我们今天说的区块,也可以理解就是Swarm用的DISC里面的块,虽然变了种,但原理不变。如果说Swarm的传输就是高级的BT协议,我觉得一点也没问题。
BT一开始最大的问题有两个,种子和Tracker都是中心化的。种子还好点,但Tracker是一个储存了地址,是一个在里面能查到哪几个人存了哪些区块,是绝对中心化的,虽然当时BT导致了盗版横行,但也很容易打击,因为只要打掉Tracker就好,经历过得都知道,就不阐述了。
然后呢怎么让Tracker去中心化,就有了DHT,就是“探索swarm的Whisper”那一篇提到的IPFS使用DHT,而DHT就是靠KAD拓扑来实现功能,KAD就是Kademlia拓扑,在之前好几个文章中都略提到过,就理解为找离自身最近的节点,然后存东西就好了。
到这里BT协议就升级了,于是升级后“在十几年前”电驴就出世了,包括如今的IPFS也是用的这个。
Whisper
继上面说的,使用了Kademlia拓扑后的DHT最大问题是防火墙问题。那Swarm是靠什么解决的?是Swarm的“Whisper”,具体请回看《探索Swarm的“Whisper”通信功能》,里面的PSS实现了所有的需要,所有传输通信都加密,隐私的。
区别
Swarm使用的BT技术和IPFS使用的BT技术区别在哪里?
在Kademlia拓扑。就如我在《Swarm设计架构之覆盖网络》那篇文章中提到“Kademlia这东西有两种算法方式,iterative/zooming 和 recursive/forwarding, 他们选的是第二种recursive/forwarding”
意思是Swarm不再像电驴和IPFS使用的技术那样是寻址的
我这里稍微再解释下什么叫寻址
打个比方:我今天要吃小笼包,但我不知道哪里有小笼包,我就翻自己手机去问了离小笼包最近的老赵,老赵翻了翻他的手机告诉你老钱是他认识离小笼包最近的,然后你又去问了老钱,他告诉你老孙是他知道离小笼包最近的,到最后你找到老孙,果然他知道小笼包在哪里,给了你小笼包地址,你自己直接开车去他给的地址买了小笼包。
Swarm是怎么运作的
同样场景,你问老赵,老赵直接去找了老王,然后老王直接去找了老孙,再然后老孙直接帮你买好,给了老王,老王给了老赵,最后是由老赵给了你。而经过这样一来,只要他们家里还有位置,小笼包以后直接能在老赵或老王或老孙那直接买到了。
最大的区别就是寻址技术存的是地址,让你自己去找地址然后在存了区块的地址上下载。而Swarm的是存的区块本身。以前的是拉,现在的是推,以前做种子,你要拉过来下载后才能本身作为新的种子以此类推,而现在的是我直接把区块推出去,自动储存和自动同步在最近的节点上。
虽然由此Swarm网络就解决了防火墙问题,但更大问题也随之出现就是需要更大的带宽和存储,要怎么解决这个问题就是节点利益了。因为要有合适的激励才有节点愿意去提供需求更大的带宽和存储。请看下期终章(下)