谷歌李飞飞:我们依旧站在人工智能研究的起点
人工智能大健康
说起人工智能,孕育了卷积神经网络和深度学习算法的 ImageNet 挑战赛恐怕是世界上最著名的 AI 数据集。8 年来,在 ImageNet 数据集的训练下,人工智能对于图像识别的准确度整整提高了 10 倍,甚至超越了人类视觉本身。
然而,AI 领域的科学家们并没有停下前进的脚步。上个周末,人工智能领域最卓越的科学家之一:斯坦福大学终身教授、谷歌云首席科学家李飞飞在未来论坛年会上,为我们做了一场名为“超越 ImageNet 的视觉智能”的精彩演讲。她告诉我们,AI 不仅仅能够精准辨认物体,还能够理解图片内容、甚至能根据一张图片写一小段文章,还能“看懂”视频……
我们都知道,地球上有很多种动物,这其中的绝大多数都有眼睛,这告诉我们视觉是最为重要的一种感觉和认知方式。它对动物的生存和发展至关重要。
所以无论我们在讨论动物智能还是机器智能,视觉是非常重要的基石。世界上所存在的这些系统当中,我们目前了解最深入的是人类的视觉系统。从 5 亿多年前寒武纪大爆发开始,我们的视觉系统就不断地进化发展,这一重要的过程得以让我们理解这个世界。而且视觉系统是我们大脑当中最为复杂的系统,大脑中负责视觉加工的皮层占所有皮层的 50%,这告诉我们,人类的视觉系统非常了不起。
寒武纪物种大爆发
一位认知心理学家做过一个非常著名的实验,这个实验能告诉大家,人类的视觉体系有多么了不起。大家看一下这个视频,你的任务是如果看到一个人的话就举手。每张图呈现的时间是非常短的,也就是 1/10 秒。不仅这样,如果让大家去寻找一个人,你并不知道对方是什么样的人,或者 TA 站在哪里,用什么样的姿势,穿什么样的衣服,然而你仍然能快速准确地识别出这个人。
1996 年的时候,法国著名的心理学家、神经科学家 Simon J. Thorpe 的论文证明出视觉认知能力是人类大脑当中最为了不起的能力,因为它的速度非常快,大概是 150 毫秒。在 150 毫秒之内,我们的大脑能够把非常复杂的含动物和不含动物的图像区别出来。那个时候计算机与人类存在天壤之别,这激励着计算机科学家,他们希望解决的最为基本的问题就是图像识别问题。
在 ImageNet 之外,在单纯的物体识别之外,我们还能做些什么?
过了 20 年到现在,计算机领域内的专家们也针对物体识别发明了几代技术,这个就是众所周知的 ImageNet。我们在图像识别领域内取得了非常大的进步:8 年的时间里,在 ImageNet 挑战赛中,计算机对图像分类的错误率降低了 10 倍。同时,这 8 年当中一项巨大的革命也出现了: 2012 年,卷积神经网络(convolutionary neural network)和 GPU(图形处理器,Graphic Processing Unit)技术的出现,对于计算机视觉和人工智能研究来说是个非常令人激动的进步。作为科学家,我也在思考,在 ImageNet 之外,在单纯的物体识别之外,我们还能做些什么?
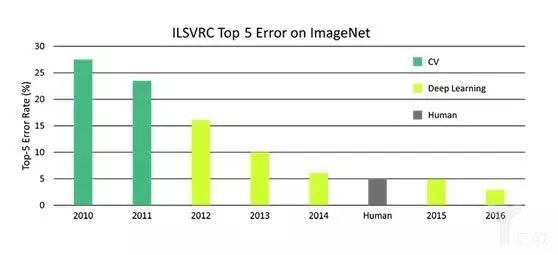
8年的时间里,在ImageNet挑战赛中,计算机对图像分类的错误率降低了10倍。
通过一个例子告诉大家:两张图片,都包含一个动物和一个人,如果只是单纯的观察这两张图中出现的事物,这两张图是非常相似的,但是他们呈现出来的故事却是完全不同的。当然你肯定不想出现在右边这张图的场景当中。

这里体现出了一个非常重要的问题,也就是人类能够做到的、最为重要、最为基础的图像识别功能——理解图像中物体之间的关系。为了模拟人类,在计算机的图像识别任务中,输入的是图像,计算机所输出的信息包括图像中的物体、它们所处的位置以及物体之间的关系。目前我们有一些前期工作,但是绝大多数由计算机所判断的物体之间的关系都是十分有限的。
1 2 下一页>
