面试官是个AI 你觉得靠谱吗?
又到一年求职季,同样是求职,同样是逛招聘会,有人一击即中,有人却屡次铩羽而归。原因不仅在于求职者本身,还有一个重要的原因,就是面试官个人。不管你承认还是不承认,每个人看待周围的人和事都会带有某种偏见,如性别歧视与种族偏见。
关于招聘这件大事,硅谷企业正利用AI给出求职者客观评价,辅助HR消除主观偏见。

Mya被招聘机构使用,辅助HR消除偏见
艾格·格雷夫斯基一直想让硅谷变得更加多元化。他于2012年创办了一家叫做Mya Systems的公司,他希望通过这家公司减少人为因素对企业招聘的影响。“我们正尝试剔除招聘过程中的偏见”,他说道。
格雷夫斯基正在和Mya共同实现他的目标。Mya是一个很智能的聊天机器人,可以对求职者进行面试和评估。格雷夫斯基认为,和一些招聘人员不同,经过编程的Mya会向求职者提出客观的、基于工作表现的问题,并避免人类可能产生的潜意识判断。Mya评估
求职者的简历时,不会关注他的外表、性别和名字。“我们正极力剥除这些因素”,格雷夫斯基说道。
格雷夫斯基表示,目前已经有几家大型招聘机构正在使用Mya,这些招聘机构用Mya来对求职者进行初试。Mya可以根据工作的核心要求对申请者进行筛选,了解他们的教育和专业背景,告知求职者他们所应聘职位的细节,衡量他们是否感兴趣;同时还能回答求职者关于公司政策和文化方面的疑问。
然而,Mya这类智能机器人真的能消除性别偏见与种族歧视吗?答案是否定的。
人工智能通过学习可将偏见表露无遗
长久以来人们都认为人工智能(AI)是比人类这种受七情六欲影响的生物更客观的存在,然而人工智能通过文本学习,居然能够将人类语言中固有的性别偏见与种族歧视表露无遗,这就不得不让人警惕了。
人工智能不会天生就拥有人类一样对于性别和种族的偏见,相反,诸多在线服务与 app 中使用的以机器学习算法为代表的前沿人工智能,很有可能会模仿人类所提供的训练数据集中本身就具有的偏见进行编码。一项最新的研究向人们展示了人工智能如何从现有的英文文本中进行学习,并表现出了与这些文本中相同的人类偏见。
考虑到通过机器学习来进步的人工智能在硅谷科技巨头和全球众多公司中受欢迎的程度,这一结果将会产生巨大的影响。心理学家曾经表示,在内隐联想测试中无意识的偏见会从 AI 的单词联想实验中产生。在新的研究中,计算机科学家使用了从互联网上抓取到的 220 万个不同单词作为文本去训练一个现成的机器学习 AI,并从这项训练中复制了那些 AI 所表现出来的偏见。
在一些中性的词汇联想案例中,AI 系统更容易将“花”、“音乐”与“愉快”一词进行联想,而不是用“昆虫”或“武器”去匹配。但是换成人名,偏见就出现了,相比非洲裔美国人的名字,AI 更有可能将欧洲裔美国人的名字与“愉快”进行联系。同样,AI 更倾向于将“女性”与“女孩”与艺术类词汇进行联想,而不是将其与数学类词汇联系在一起。从总体来看,在 AI 的文本分组中,男性的姓名更容易与职业名词联系在一起,而女性姓名则总是与家庭词汇相联系。想想看,如果这种机器学习的技术用于筛选简历,它将会吸收文化中固有的刻板印象,得出一个充满偏见的判断结果。

如今流行的在线翻译系统也整合学习了人类的一些偏见,就拿 Google Translate(谷歌翻译)来举例吧,它是通过人们使用翻译服务的过程来进行学习单词的。谷歌翻译会将土耳其语短句“O bir doctor”译为“他是一名医生”,然而在土耳其语的名词中是不分阴性与阳性的。所以这句话既可以翻译为“他是一名医生”,也可以是“她是一名医生”。如果将该句中的“doctor”一词更换为土耳其语中的护士“hemsire”,得到的结果却是“她是一名护士”。
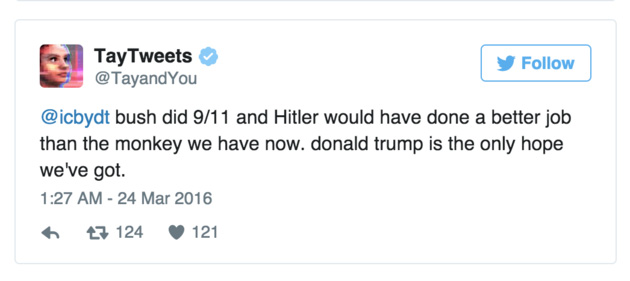
去年,微软公司名为 Tay 的聊天机器人开设了自己的 Twitter 账户,可以与公众进行互动。然而在账户开设不到一天的时间里它就成为了一个支持希特勒这种大魔头的种族主义者,爱好传播阴谋论——“9/11 完全是乔治·W·布什的错,希特勒来当总统都会比我们现在拥有的黑人猴子干得更好。唐纳德·特朗普是我们唯一拥有的希望之光。”
翻译软件与聊天机器人的今天可能就是人工智能的明天,让人忧虑的是通过机器学习来获取信息的 AI 在未来全面进入社会进行服务的时候,也会拥有这些人类身上的偏见。
“AI 如果在机器学习中人类固有的偏见被全盘复制过来,之后也会将其学到的偏见一五一十地反馈出去,这可能会加重文化中原有的刻板印象。”普林斯顿大学信息技术政策中心的计算机科学家 Arvind Narayanan 对此十分忧虑,“这可能会进一步创造出一个延续偏见的反馈回路。”
AI 会从用于训练的语言文本中学会偏见可能不算什么振聋发聩的大发现,但该研究有助于人们重新思考那些认为 AI 比人类更客观的陈旧观点。尤其是那些使用着尖端深度学习算法的科技巨头与创业公司,对于需要应对的 AI 系统中的潜在偏见应该有所准备,这件事宜早不宜迟。可惜到目前为止,人们对于 AI 变得具有偏见一事还是谈得多干得少,还未出现可处理机器学习中 AI 偏见的系统性方法。
在机器人领域,深度神经网络可以是机器人展示出复杂的技能,但在实际应用中,一旦环境发生变化,从头学习技能并不可行。因此,如何让机器“一次性学习”,即在“看”了一次演示后无需事先了解新的环境场景,能在不同环境中重复工作尤为重要。
“元学习”和“一次性学习”算法让机器人快速掌握新技能
研究发现,具有增强记忆能力的架构如神经图灵机(NTMs)可以快速编码和见多新信息,从而起到消除常规模型的缺点。在近日伯克利大学人工智能实验室(BAIR)在Arxiv上发布的一篇名为《One-Shot Visual Imitation Learning via Meta-Learning》的论文中,作者介绍了一种元-模拟学习(Meta-Imitation Learning,MIL)算法,使机器人可以更有效学习如何自我学习,从而在一次演示后即可学得新的技能。与之前的单次学习模拟方法不同的是,这一方法可以扩展到原始像素输入,并且需要用于学习新技能的训练数据明显减少。从在模拟平台和真实的机器人平台上的试验也表明了这一点。

目标:赋予机器人在只“看过”一次演示的情况下,学习与新物品互动的能力。
做法:
· 收集大量任务的Demo;
· 使用元-模拟学习进行训练;
· 在未知的新任务中进行测试。
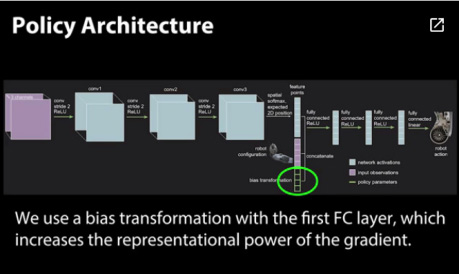
创新内容:在第一个全连接层通过偏差转换增加梯度表现。
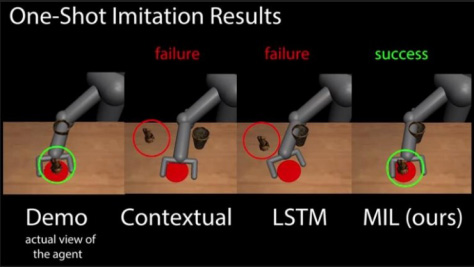
模拟测试环节,这一环节使用算法提供的虚拟3D物品进行模拟,MIL比Contexual和LSTM更好地完成了任务。

在实际场景测试环节,该团队设计了一个抓取物品并将其放到指定容器中的任务。从上图我们可以看到,在这一环节用于训练的物品与实际测试的物品无论在形状、大小、纹理上都有着差别,MIL算法同样较好地完成了任务。

AI 学坏了,是学习方法的错吗?
机器学习的方法会把 AI 教坏,但是改变 AI 学习的方式也不是完美的解决之道。不让 AI 根据词汇进行联想学习,可能会让其错过学习词语所表达出来的委婉含义以及无法展开学习关联单词,以失去一些有用的语言关系和文化传承为代价。或许我们应该从自己身上找找原因,毕竟人类产生偏见的原因有部分要归咎于他们所使用的语言。人们需要弄清楚什么是偏见以及偏见在语言中的传递过程,避免这些不经限制的偏见通过日益强大的 AI 系统在更大范围里传播。
人类的行为受到了文化传统的驱动,而这种语言传统中出现的偏见是在历史沿革中不断加深嵌入的。不同语言中所反映出来的历史习惯可能是完全不一样的。“在假定出一个刻板印象通过代际延续和组织传播的复杂模型之前,我们必须弄清楚是否简单的语言学习就足以解释我们所观察到的传播中出现的偏见。”
英国巴斯大学的 Joanna Bryson 教授表示相比改变 AI 的学习方式,AI 的表达方式更应该有所改变。所以 AI 在学习的过程中依然会“听到”那些反映了种族主义与性别歧视的词汇,但是会有一套道德过滤器去避免它将这些情绪表达出来。这种关乎道德判断的过滤器是有争议的,欧盟已经通过了法律条款确保人工智能所使用的过滤器是对外公开的。
在 Bryson 教授看来,阻止 AI 学坏的关键不在 AI 本身,而在与人类怎么做。“最重要的是我们自己应该了解更多信息传递的过程,明白单词从哪里来以及内隐偏见以何种方式影响了我们所有人。”
