人工智能之深度强化学习DRL
AI优化生活前言:人工智能机器学习有关算法内容,人工智能之机器学习主要有三大类:1)分类;2)回归;3)聚类。今天我们重点探讨一下深度强化学习。
之前介绍过深度学习DL和强化学习RL,那么人们不禁会问会不会有深度强化学习DRL呢? 答案是Exactly!
我们先回顾一下深度学习DL和强化学习RL。
深度学习DL是机器学习中一种基于对数据进行表征学习的方法。深度学习DL有监督和非监督之分,都已经得到广泛的研究和应用。
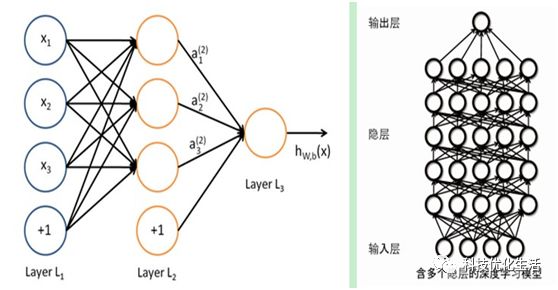
强化学习RL是通过对未知环境一边探索一边建立环境模型以及学习得到一个最优策略。强化学习是机器学习中一种快速、高效且不可替代的学习算法。
然后今天我们重点跟跟大家一起探讨一下深度强化学习DRL。

深度强化学习DRL自提出以来, 已在理论和应用方面均取得了显著的成果。尤其是谷歌DeepMind团队基于深度强化学习DRL研发的AlphaGo,将深度强化学习DRL成推上新的热点和高度,成为人工智能历史上一个新的里程碑。因此,深度强化学习DRL非常值得研究。
深度强化学习概念:
深度强化学习DRL将深度学习DL的感知能力和强化学习RL的决策能力相结合, 可以直接根据输入的信息进行控制,是一种更接近人类思维方式的人工智能方法。
在与世界的正常互动过程中,强化学习会通过试错法利用奖励来学习。它跟自然学习过程非常相似,而与深度学习不同。在强化学习中,可以用较少的训练信息,这样做的优势是信息更充足,而且不受监督者技能限制。
深度强化学习DRL是深度学习和强化学习的结合。这两种学习方式在很大程度上是正交问题,二者结合得很好。强化学习定义了优化的目标,深度学习给出了运行机制——表征问题的方式以及解决问题的方式。将强化学习和深度学习结合在一起,寻求一个能够解决任何人类级别任务的代理,得到了能够解决很多复杂问题的一种能力——通用智能。深度强化学习DRL将有助于革新AI领域,它是朝向构建对视觉世界拥有更高级理解的自主系统迈出的一步。从某种意义上讲,深度强化学习DRL是人工智能的未来。
深度强化学习本质:
深度强化学习DRL的Autonomous Agent使用强化学习的试错算法和累计奖励函数来加速神经网络设计。这些设计为很多依靠监督/无监督学习的人工智能应用提供支持。它涉及对强化学习驱动Autonomous Agent的使用,以快速探索与无数体系结构、节点类型、连接、超参数设置相关的性能权衡,以及对深度学习、机器学习和其他人工智能模型设计人员可用的其它选择。

深度强化学习原理:
深度Q网络通过使用深度学习DL和强化学习RL两种技术,来解决在强化学习RL中使用函数逼近的基本不稳定性问题:经验重放和目标网络。经验重放使得强化学习RL智能体能够从先前观察到的数据离线进行抽样和训练。这不仅大大减少了环境所需的交互量,而且可以对一批经验进行抽样,减少学习更新的差异。此外,通过从大存储器均匀采样,可能对强化学习RL算法产生不利影响的时间相关性被打破了。最后,从实际的角度看,可以通过现代硬件并行地高效地处理批量的数据,从而提高吞吐量。
Q学习的核心思想就是通过Bellman方程来迭代求解Q函数。

损失函数:
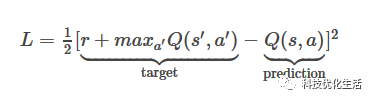
Q值更新:
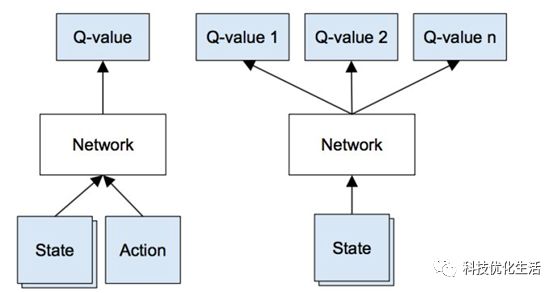
1)使用当前的状态s通过神经网络计算出所有动作的Q值
2)使用下一个状态s’通过神经网络计算出 Q(s’, a’),并获取最大值max a’ Q(s’, a’)
3)将该动作a的目标Q值设为 r + γmax a’ Q(s’, a’),对于其他动作,把目标Q值设为第1步返回的Q值,使误差为0
4)使用反向传播来更新Q网络权重。
带有经验回放的深度Q学习算法如下:

注:
1)经验回放会使训练任务更近似于通常的监督式学习,从而简化了算法的调式和测试。
2)深度Q网络之后,有好多关于 DQN 的改进。比如双深度 Q 网络(DoubleDQN),确定优先级的经历回放和决斗网络(Dueling Network)等。
策略搜索方法通过无梯度或梯度方法直接查找策略。无梯度的策略搜索算法可以选择遗传算法。遗传方法依赖于评估一组智能体的表现。因此,对于具有许多参数的一大群智能体来说遗传算法的使用成本很高。然而,作为黑盒优化方法,它们可以用于优化任意的不可微分的模型,并且天然能够在参数空间中进行更多的探索。结合神经网络权重的压缩表示,遗传算法甚至可以用于训练大型网络;这种技术也带来了第一个直接从高维视觉输入学习RL任务的深度神经网络。
深度策略网络

策略梯度

Actor-Critic算法将策略搜索方法的优点与学习到的价值函数结合起来,从而能够从TD错误中学习,近来很受欢迎。

异步优势Actor Critic 算法(A3C)结合 Policy 和 Value Function 的产物。

确定策略梯度(Deterministic Policy Gradient)算法

虚拟自我对抗 (FSP)

深度强化学习挑战:
目前深度强化学习研究领域仍然存在着挑战。
1)提高数据有效性方面;
2)算法探索性和开发性平衡方面;
3)处理层次化强化学习方面;
4)利用其它系统控制器的学习轨迹来引导学习过程;
5)评估深度强化学习效果;
6)多主体强化学习;
7)迁移学习;
8)深度强化学习基准测试。
。。。。。。
深度强化学习应用:
深度强化学习DRL应用范围较广,灵活性很大,扩展性很强。它在图像处理、游戏、机器人、无人驾驶及系统控制等领域得到越来越广泛的应用。
深度强化学习DRL算法已被应用于各种各样的问题,例如机器人技术,创建能够进行元学习(“学会学习”learning to learn)的智能体,这种智能体能泛化处理以前从未见过的复杂视觉环境。
结语:
强化学习和深度学习是两种技术,但是深度学习可以用到强化学习上,叫做深度强化学习DRL。深度学习不仅能够为强化学习带来端到端优化的便利,而且使得强化学习不再受限于低维的空间中,极大地拓展了强化学习的使用范围。深度强化学习DRL自提出以来, 已在理论和应用方面均取得了显著的成果。尤其是谷歌DeepMind团队基于深度强化学习DRL研发的AlphaGo,将深度强化学习DRL成推上新的热点和高度,成为人工智能历史上一个新的里程碑。因此,深度强化学习DRL很值得大家研究。深度强化学习将有助于革新AI领域,它是朝向构建对视觉世界拥有更高级理解的自主系统迈出的一步。难怪谷歌DeepMind中深度强化学习领头人David Silver曾经说过,深度学习(DL) + 强化学习(RL) = 深度强化学习DRL=人工智能(AI)。深度强化学习应用范围较广,灵活性很大,扩展性很强。它在图像处理、游戏、机器人、无人驾驶及系统控制等领域得到越来越广泛的应用。
