人工智能–GAN算法
AI优化生活前言:人工智能机器学习有关算法内容,人工智能之机器学习主要有三大类:1)分类;2)回归;3)聚类。今天我们重点探讨一下GAN算法。
我们知道机器学习模型有:生成模型(GenerativeModel)和判别模型(Discriminative Model)。判别模型需要输入变量x,通过某种模型来预测p(y|x)。生成模型是给定某种隐含信息,来随机产生观测数据。
不管何种模型,其损失函数(Loss Function)选择,将影响到训练结果质量,是机器学习模型设计的重要部分。对于判别模型,损失函数是容易定义的,因为输出的目标相对简单。但对于生成模型,损失函数却是不容易定义的。
2014年GoodFellow等人发表了一篇论文“Goodfellow, Ian, et al. Generative adversarial nets." Advances inNeural Information Processing Systems. 2014”,引发了GAN生成式对抗网络的研究,值得学习和探讨。今天就跟大家探讨一下GAN算法。
GAN算法概念:
GAN生成式对抗网络(Generative Adversarial Networks )是一种深度学习(请参见人工智能(23))模型,是近年来复杂分布上无监督学习最具有前景的方法之一。 GAN生成式对抗网络的模型至少包括两个模块:G模型-生成模型(Generative Model)和D模型-判别模型(Discriminative Model)。两者互相博弈学习产生相当好的输出结果。GAN 理论中,并不要求G、D模型都是神经网络,只需要是能拟合相应生成和判别的函数即可。但实际应用中一般均使用深度神经网络作为G、D模型。
对于生成结果的期望,往往是一个难以数学公理化定义的范式。所以不妨把生成模型的回馈部分,交给判别模型处理。于是Goodfellow等人将机器学习中的两类模型(G、D模型)紧密地联合在了一起(该算法最巧妙的地方!)。
一个优秀的GAN模型应用需要有良好的训练方法,否则可能由于神经网络模型的自由性而导致输出结果不理想。
GAN算法原理:
1.先以生成图片为例进行说明:
假设有两个网络,分别为G(Generator)和D(Discriminator),它们的功能分别是:
1)G是一个生成图片的网络,它接收一个随机的噪声z,通过这个噪声生成图片,记做G(z)。
2)D是一个判别网络,判别一张图片是不是“真实的”。它的输入参数是x,x代表一张图片,输出D(x)代表x为真实图片的概率,如果为1,就代表100%是真实的图片,而输出为0,就代表不可能是真实的图片。
3)在最理想的状态下,G可以生成足以“以假乱真”的图片G(z)。对于D来说,它难以判定G生成的图片究竟是不是真实的,因此D(G(z)) = 0.5。
4)这样目的就达成了:得到了一个生成式的模型G,它可以用来生成图片。
在训练过程中,生成网络G的目标就是尽量生成真实的图片去欺骗判别网络D。而判别网络D的目标就是尽量把G生成的图片和真实的图片分别开来。这样,G和D构成了一个动态的“博弈过程”。
2.再以理论抽象进行说明:
GAN是一种通过对抗过程估计生成模型的新框架。框架中同时训练两个模型:捕获数据分布的生成模型G,和估计样本来自训练数据的概率的判别模型D。G的训练程序是将D错误的概率最大化。可以证明在任意函数G和D的空间中,存在唯一的解决方案,使得G重现训练数据分布,而D=0.5(D判断不出真假,50%概率,跟抛硬币决定一样)。在G和D由多层感知器定义的情况下,整个系统可以用反向传播进行训练。在训练或生成样本期间,不需要任何马尔科夫链或展开的近似推理网络。实验通过对生成的样品的定性和定量评估,证明了GAN框架的潜在优势。
Goodfellow从理论上证明了该算法的收敛性。在模型收敛时,生成数据和真实数据具有相同分布,从而保证了模型效果。
GAN公式形式如下:
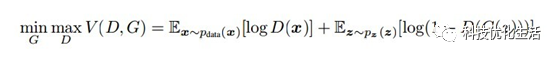
GAN公式说明如下:
1)公式中x表示真实图片,z表示输入G网络的噪声,G(z)表示G网络生成的图片;
2)D(x)表示D网络判断图片是否真实的概率,因为x就是真实的,所以对于D来说,这个值越接近1越好。
3)G的目的:D(G(z))是D网络判断G生成的图片的是否真实的概率。G应该希望自己生成的图片“越接近真实越好”。也就是说,G希望D(G(z))尽可能得大,这时V(D, G)会变小。因此公式的最前面记号是min_G。
4)D的目的:D的能力越强,D(x)应该越大,D(G(x))应该越小。这时V(D,G)会变大。因此式子对于D来说是求最大max_D。
GAN训练过程:
GAN通过随机梯度下降法来训练D和G。
1) 首先训练D,D希望V(G, D)越大越好,所以是加上梯度(ascending)
2) 然后训练G时,G希望V(G, D)越小越好,所以是减去梯度(descending);
3) 整个训练过程交替进行。
GAN训练具体过程如下:

GAN算法优点:
1)使用了latent code,用以表达latent dimension、控制数据隐含关系等;
2)数据会逐渐统一;
3)不需要马尔可夫链;
4)被认为可以生成最好的样本(不过没法鉴定“好”与“不好”);
5)只有反向传播被用来获得梯度,学习期间不需要推理;
6)各种各样的功能可以被纳入到模型中;
7)可以表示非常尖锐,甚至退化的分布。
GAN算法缺点:
1)Pg(x)没有显式表示;
2)D在训练过程中必须与G同步良好;
3)G不能被训练太多;
4)波兹曼机必须在学习步骤之间保持最新。
GAN算法扩展:
GAN框架允许有许多扩展:
1)通过将C作为输入,输入G和D,可以得到条件生成模型P(x|c);
2)学习近似推理,可以通过训练辅助网络来预测Z。
3)通过训练一组共享参数的条件模型,可以近似地模拟所有条件。本质上,可以使用对抗性网络实现确定性MP-DBM的随机扩展。
4)半监督学习:当仅有有限标记数据时,来自判别器或推理网络的特征可以提高分类器的性能。
5)效率改进:通过划分更好的方法可以大大加快训练,更好的方法包括:a)协调G和D; b) 在训练期间,确定训练样本Z的更好分布。
GAN算法应用:
GAN的应用范围较广,扩展性也强,可应用于图像生成、数据增强和图像处理等领域。
1)图像生成:
目前GAN最常使用的地方就是图像生成,如超分辨率任务,语义分割等。
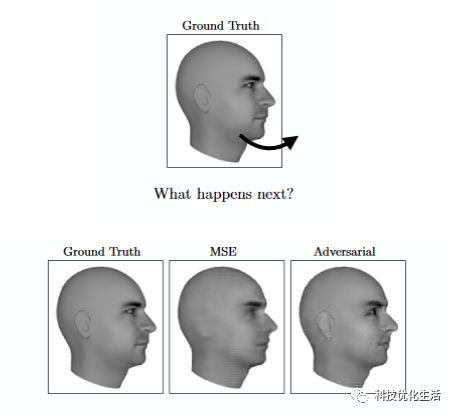
2)数据增强:
用GAN生成的图像来做数据增强。主要解决的问题是a)对于小数据集,数据量不足,可以生成一些数据;b)用原始数据训练一个GAN,GAN生成的数据label不同类别。
结语:
GAN生成式对抗网络是一种深度学习模型,是近年来复杂分布上无监督学习最具有前景的方法之一,值得深入研究。GAN生成式对抗网络的模型至少包括两个模块:G模型-生成模型和D模型-判别模型。两者互相博弈学习产生相当好的输出结果。GAN算法应用范围较广,扩展性也强,可应用于图像生成、数据增强和图像处理等领域。
