Vitalik:用 calldata 扩展和分片降低以太坊rollup成本
隔夜的粥注:原文作者是以太坊联合创始人vitalik buterin。
Rollup 是以太坊唯一的去信任扩容解决方案,它是短期和中期的解决方案,也可能会是长期的解决方案。几个月来,以太坊L1上的交易费用一直居高不下,而且我们迫切需要做任何必要的事情来帮助促进整个生态系统向rollup的迁移。Rollup 已经帮助很多以太坊用户显著降低了费用:根据l2fees.info显示,Optimism 和 Arbitrum 提供的费用比以太坊基础层本身低约 3-8 倍,而ZK rollup方案具有更好的数据压缩,并且可以避免包含签名,因此这些L2的费用比基础层低约40-100倍。
然而,这样的费用对很多用户来说还是太贵了。长期以来,人们一直认为改善目前形式rollup的解决方案是数据分片,这将为链中的rollup增加约1-2 MB/s的专用数据空间。本文描述了实现该解决方案的实用途径,以尽快为rollup打开数据空间,并随着时间的推移增加额外的空间及安全性。
步骤1: tx calldata扩展
今天现有的rollup使用了tx calldata,因此,如果我们想在不要求rollup 团队做任何额外工作的情况下,短期提升 rollup 容量并降低成本,我们只需降低tx calldata的成本。今天的平均区块大小远不会威胁到网络稳定性,因此可以安全地做到这一点,尽管它可能需要一些额外的逻辑来防止非常不安全的边缘情况。
请参阅:EIP 4488,或替代方案EIP 4490?(更简单但效果更温和)。
EIP 4488 应将可用于rollup的的数据空间增加到每个slot 约 1 MB 的理论最大值,并将rollup成本降低至原来的1/5,它可以比后面的步骤更快地实施。
步骤2: 一些分片
同时,我们可开展工作以推出“适当的”分片。以完整形式实现适当的分片需要很长时间,但我们可以做的是一点一点地实现它,并从每个部分中受益。要实现的第一个自然部分是分片规范的“业务逻辑”,通过将分片的初始数量保持在非常低的水平(例如 4),以避免大部分与网络相关的困难。每个分片都将在其自己的子网上广播。默认情况下,验证者会信任委员会,但如果他们愿意,他们可以选择在每个子网上,并且只有在他们看到信标区块确认的任何分片区块的完整body主体后才接受一个信标区块。
分片规范本身并不是特别困难,这是一个与最近发布的Altair 硬分叉类似的样板代码更改(Altair 信标更改规范文件长 728 行,分片信标更改规范文件长 888 行),因此可以合理地期望它可实现与 Altair 的实施和部署相似的时间范围内。
为了使分片数据真正可用于rollup,rollup需要能将证明放入分片数据中,这有两种选择:
- 添加 BEACONBLOCKROOT 操作码,rollup 将添加代码来验证植根于历史信标链区块根的 Merkle 证明。
- 添加面向未来的状态和历史访问预编译,以便在未来承诺方案发生变化时,rollup不需要更改其代码。
这会将rollup数据空间增加到每个slot约 2 MB(每个分片 250 kB * 4 个分片,加上步骤 1 中扩展的 calldata)。
第 3 步:N 个分片,受委员会保护
这一步将活动分片的数量从 4 个增加到 64 个,分片数据现在将进入子网,因此此时 P2P 层必须已经足够稳固,可以拆分成更多的子网。数据可用性的安全性将基于诚实多数,依赖于委员会的安全性。
这会将rollup数据空间增加到每个slot约 16 MB(每个分片 250 kB * 64 个分片),我们假设此时 rollup 已经从执行链中迁移出来。
第4步:数据可用性抽样 (DAS)
到了这一步,我们会添加数据可用性采样(DAS)以确保更高级别的安全性,即使在发生不诚实的多数攻击时也能保护用户。数据可用性采样可以分阶段推出:首先,以非绑定方式允许网络对其进行测试,然后作为接受信标区块的要求,甚至可能在其他客户端之前在某些客户端上进行。
一旦完全引入数据可用性采样,分片部署就完成了。
分片环境下的Optimistic和ZK rollup
分片世界和现状之间的一个主要区别是,在分片世界中,rollup数据实际上不可能成为将rollup区块提交到智能合约的交易的一部分。相反,数据发布步骤和rollup区块提交步骤必须分开:
首先,数据发布步骤将数据放在链上(放入分片中),然后提交步骤提交其header,以及指向基础数据。
Optimism 和 Arbitrum 已经为rollup区块提交使用了一个两步设计,因此这对两者来说都是一个小的代码更改。
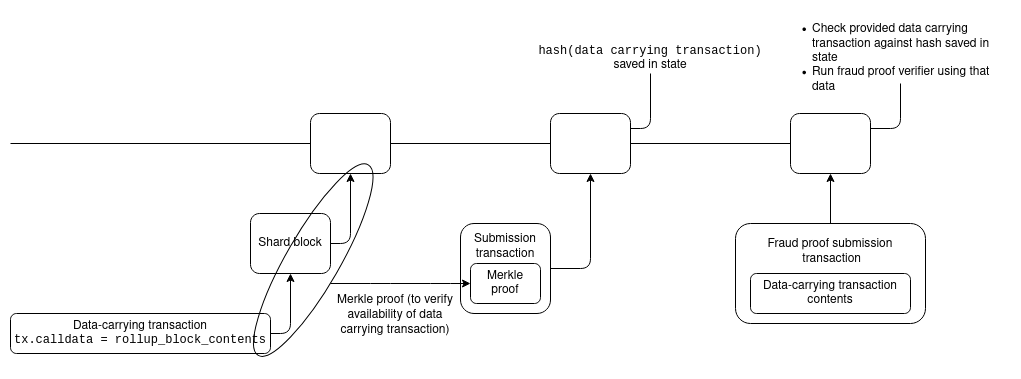
而对于ZK rollup而言,事情有点棘手,因为提交交易需要提供直接对数据进行操作的证明。他们可以做一个 ZK-SNARK 的证明,证明分片中的数据与信标链上的承诺相匹配,但这非常昂贵。幸运的是,还有更便宜的选择。
如果ZK-SNARK是基于BLS12-381的PLONK证明,那么他们可以直接将分片数据提交作为输入。BLS12-381 分片数据承诺是 KZG 承诺,与 PLONK 中的承诺类型相同,因此它可以作为公共输入直接传递到证明中。
如果 ZK-SNARK 使用一些不同的方案(甚至只是 BLS12-381 PLONK,但具有更大的可信设置),则它可以包括自己对数据的承诺,并使用等价性证明来验证证明中的承诺和信标链中的承诺是否承诺了相同的数据。
谁将在分片环境下存储历史数据?
增加数据空间的一个必要条件,是删除以太坊核心协议负责永久维护所有达成共识的数据的属性。数据量太大,不需要这样做。例如:
1、EIP 4488导致理论上的最大链大小为每12秒(slot)大约1,262,861 字节,或每年 ~3.0 TB,但实际上每年 ~250-1000 GB 更有可能,尤其是在开始时。
2、4 个分片(每个slot 1 MB)每年增加(几乎保证)大约2.5 TB;
3、64 个分片(每个slot 16 MB)导致每年总共(几乎保证)约 40 TB 存储;
大多数用户的硬盘大小在 256 GB 到 2 TB 之间,1 TB 似乎是中位数。根据一组区块链研究人员的内部民意调查显示:
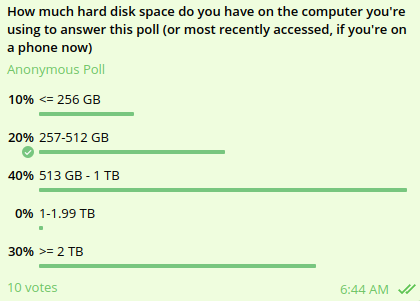
这意味着用户可以负担得起目前运行节点的费用,但如果该路线图的任何部分在没有进一步修改的情况下实施,则用户将无法负担。可以使用更大的硬盘,但用户必须竭尽全力购买它们,这显着增加了运行节点的复杂性。关于这个问题,领先的解决方案是EIP-4444,它消除了节点运营商存储超过 1 年的区块或收据的责任。在分片的环境下,这个时间段可能会进一步缩短,节点将只负责他们积极参与的子网上的分片。
这留下了一个问题:如果以太坊核心协议不存储这些数据,那谁来存储?
首先,重要的是要记住,即使使用分片,数据量也不会那么大。是的,对于运行“默认”消费硬件的个人来说,每年 40 TB 是不可接受的(事实上,即使是每年 1 TB 也是如此)。然而,它完全在愿意投入一些资源和工作来存储数据的专职个人的范围内。举例来说,一个48 TB 硬盘的售价是1729美元,14 TB硬盘的售价约 420 美元。
那么谁来存储这些数据呢?一些想法:
- 个人和机构志愿者;
- 区块链浏览器(etherchain.org、etherscan.io、amberdata.io...)肯定会存储所有的数据,因为向用户提供数据是他们的商业模式。
- Rollup DAO提名和支付参与者,以存储和提供与其rollup相关的历史记录;
- 历史数据可以通过torrents上传和共享;
- 客户端可自愿选择存储随机的0.05%的链历史记录(使用擦除编码)。
- Portal Network中的客户端可以存储链历史的随机部分,Portal Network将自动将数据请求定向到拥有数据的节点。
- 可以在协议内激励历史数据存储。
- 像 The Graph 这样的协议可以创建激励市场,客户端可通过其正确性的Merkle 证明来向服务器支付历史数据。这促使人们和机构运行存储历史数据并按需提供的服务器。
其中一些解决方案(个人和机构志愿者、区块浏览器)已经存在,特别是 p2p Torrent 场景是一个很好的例子,它是一个主要由志愿者驱动(存储大量数据内容)的生态系统。剩下的基于协议的解决方案更强大,因为它们提供了激励,但需要更长的时间来开发。从长远来看,通过这些第二层协议访问历史记录很可能比今天通过以太坊协议更有效。


