大模型使得AIGC有了更多的可能
大模型使得AIGC有了更多的可能
- 视觉大模型提高AIGC感知能力
以图像和视频为代表的视觉数据是我们这个时代下信息的主要载体之一,这些视觉信息时刻记录着物理世界的状态,反映着人的想法、观念和价值主张。在深度学习时代,主要是基于深度神经网络模型,比如深度残差网络(ResNet),这类模型往往针对单一感知任务进行设计,很难同时完成多种视觉感知任务。而大模型则可以让AIGC技术解决掉不同场景、环境和条件下的视觉感知问题,并实现鲁棒、准确、高效的视觉理解。近年来基于Transformer衍生出来的一系列大模型架构如Swin Transformer、ViTAE Transformer,通过无监督预训练和微调的范式,在图像分类、目标检测、语义分割、姿态估计、图像编辑以及遥感图像解译等多个感知任务上取得了相比过去精心设计的多种算法模型更加优异的性能和表现,有望成为基础视觉模型(Foundation Vision Model),显著提升感知能力,助力AIGC领域的发展。
- 语言大模型增强AIGC认知能力
作为是人类文明的重要记录方式,语言和文字记录了人类社会的历史变迁、科学文化和知识文化。基于语言的认知智能可以更快加速通用人工智能(AGI)的到来。在如今信息复杂的场景中,数据质量参差不齐、任务种类多,存在着数据孤岛和模型孤岛的问题,深度学习时代对自然语言的处理有着很明显的不足,包括模型设计、部署困难;数据难以复用;海量无标签难以进行数据挖掘、知识提取。谷歌和OpenAI分别提出的大规模预训练模型BERT和GPT,今年来在诸多自然语言理解和生成任务上取得了突破性的性能提升,相信大家现在已经深有感触。
- 多模态大模型升级AIGC内容创作能力
在日常生活中,视觉和语言是最常见且最重要的两种模态,视觉大模型可以构建出人工智能更加强大的环境感知能力,语言大模型则可以学习到人类文明的抽象概念以及认知的能力。如果AIGC技术只能生成单一模态的内容,那么其应用场景将极为有限、不足以推动内容生产方式的革新。多模态大模型的出现,则让融合性创新成为可能,极大丰富AIGC技术可应用的广度。多模态大模型将不同模态的原始数据映射到统一或者相似语义空间中,实现不同模态信号之间的相互理解与对齐。基于多模态大模型,AIGC才能具备更接近于人类的创作能力,并真正的开始展示出代替人类进行内容创作,进一步解放生产力的潜力。
3.4 大模型不是人人玩得起的
大模型门槛比较高,具体表现为参数大、数据大、算力大
参数:语言大模型的参数规模亿级~万亿级(BERT作为baseline),图像大模型参数规模在亿级~百亿级范围。模型参数越大,代表着需要存储模型空间也越变大,需要的成本也就越高。
模型参数是什么?
aX1+bX2=Y,X1和X2是变量,Y是计算结果,a和b是参数,同理,一个神经网络模型,无论规模多大,它都是一个函数,只不过这个函数极其复杂,维度极其多,但依然是由参数、变量来组成,我们通过数据来训练模型,数据就是变量,而参数,就是通过变量的变换,学到的最终的常量。
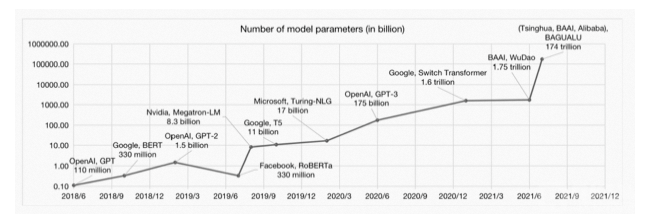
5年内,模型参数数量从亿级别发展到100万亿级,增长100万倍
数据:模型参数的大幅增长,必然需要更大的数据来训练,否则模型强大的表征能力就会轻易地过拟合。由于标注成本和训练周期的限制,传统有监督的方式将变得不现实,因此无法全用标注好的监督数据,需要利用自监督的方法,挖掘数据中的信息。从18年BERT的33亿词符,到19年XLNet的330亿词符,20年GPT-3的6800亿词符,数据量以十倍速度增长(英文数据集大小也差不多止于此),22年PaLM 使用了7800亿词符训练。
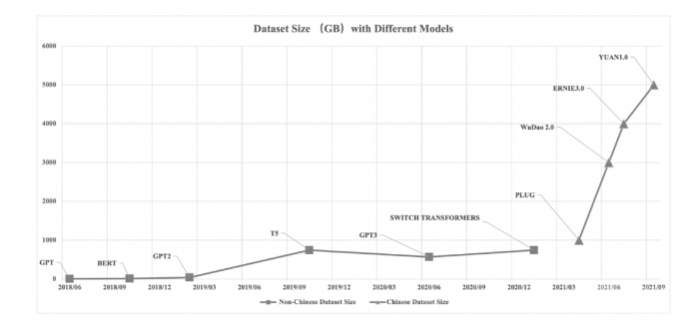
不同大模型预训练数据集规模(大小:GB)的增长对比
算力:尽管“小模型”阶段对算力的要求就一直持续增长,但那个阶段可以说用1张GPU卡可以解决,也算不上太夸张,很多个体,小企业也都可以玩,但是到了超大规模预训练模型阶段,超大的参数、数据带来对算力的要求,是普通玩家难以企及的。就算构建了网络结构,获取到了数据,但是算力不行,也训练不起来。从算力需求的角度看,从GPT的18k petaFLOPs,到 GPT-3的310M petaFLOPs,以及PaLM的2.5B petaFLOPs,更直观的可以看下面这张图。从成本的角度,感受大模型训练对算力成本的吞噬——GPT-3的训练使用了上万块英伟达v100 GPU,总成本高达2760万美元,个人如果要训练出一个PaLM也要花费900至1700万美元。
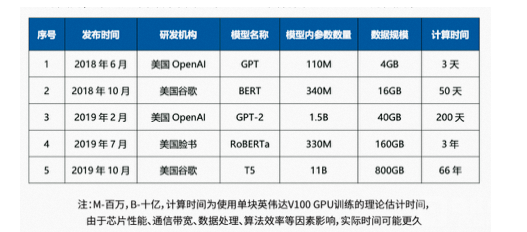
典型的大模型例如GPT BERT GPT-2等的训练时间
四、一些畅想
素材生产大模型:AIGC在素材图片生成已经有了落地成果,如果大模型加持下,其素材生成质量和图像内容理解会不会有一个质的飞跃?利用大模型理解用户动向,对文字素材进行个性化产出?
智能UI大模型:当下智能UI本质上还是规则约束,大模型会不会实现真正的智能?
用户理解大模型:推荐大模型?刻画用户画像和用户动向,统一长尾流量场景模型,预测新疆流用户偏好(真快,都有人发论文了Chat-REC)
阿里版GPT官宣:所有产品都将接入!

4月11日,在2023阿里云峰会上,阿里云推出通义千问大语言模型(LLM),该模型支持多轮交互及复杂指令理解、多模态融合、外部增强API等功能;同时,阿里云推出企业专属大模型产品。
会上,阿里董事会主席兼CEO张勇宣布,阿里所有产品未来将接入大模型全面升级,包括淘宝、天猫、高德地图、菜鸟、饿了么等所有国民级产品。
Foundation model仍然在早期,但未来可期:
Most information processing and analysis tasks, and perhaps even things like robotic control, will be handled by a specialization of one of a relatively small number of foundation models. These models will be expensive and time-consuming to train, but adapting them to different tasks will be quite easy; indeed, one might be able to do it simply with natural language instructions.
引用一句Manning大佬的原话,AI模型收敛到少数几个大模型会带来伦理上的风险。但是大模型这种将海量数据中学来的知识应用到多种多样任务上的能力,在历史上第一次地非常地接近了(通用)AI的目标:对单一的机器模型发出简单的指令就做到各种各样的事情。


