一文看懂数据可用性(DA)对区块链的重要意义
洒脱喜注:原文来自medium,作者是Blockchain Capital 高级分析师Yuan Han Li。
你可能听说过,以太坊的分片路线图基本上已取消了执行分片,现在它只专注于数据分片,以最大限度地提高以太坊的数据空间吞吐量。
你可能还在最近看到了关于模块化区块链的讨论,深入研究了rollup并了解了volition或validium?,然后听说了“数据可用性解决方案”。
但也许你会产生困惑,挠了挠头,然后问自己数据可用性(DA)到底是什么?
在我们深入研究之前,复习一下大多数区块链是如何工作的基础知识,可能会有所帮助。
交易、节点以及著名的“区块链不可能三角”
当你遇到一个新的带有高APY的OHM分叉项目时,你的下一步行动可能就是猛按“stake”按钮,但是当你实际通过Metamask提交该tx时会发生什么?
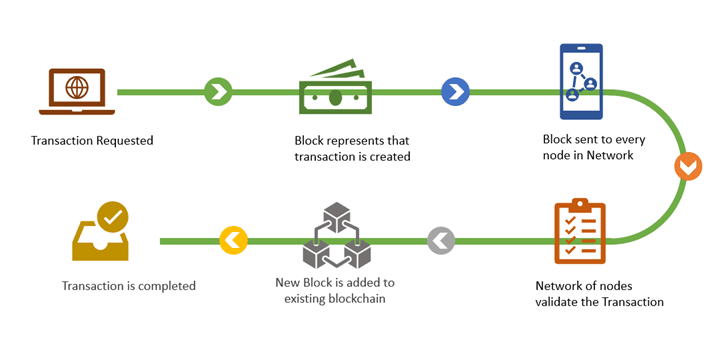
简单地说,你的交易会进入mempool存储池,假设你给矿工或验证者的贿赂足够高,你提交的交易就会被纳入到下一个区块中,并被添加至区块链。然后,包含你的交易的这个区块,会被广播到区块链节点的网络。全节点将下载这个新区块,执行/计算该区块中包含的每笔交易(包括你的),并确保它们都是有效的。例如,对于你的交易,这些全节点可能验证你没有从其他人那里窃取资金,并且你实际上有足够的ETH来支付gas费用等等。因此,全节点执行了有关矿工/验证者的强制区块链规则的重要任务。
正是由于这种机制,导致传统区块链遇到了扩容方面的问题,由于全节点检查每笔交易以验证它们是否遵循区块链的规则,区块链无法在不增加运行全节点的硬件要求的情况下,每秒去处理更多的tx(更好的硬件=更强大的全节点=全节点可以检查更多tx=允许包含更多tx的更大区块)。但是,如果运行全节点的硬件要求提高,那么全节点的数量就会减少,系统的去中心化属性就会受到影响。也就是说,如果检查矿工/验证器工作以保持诚实的人减少,这将是危险的(因为信任假设会增加)!
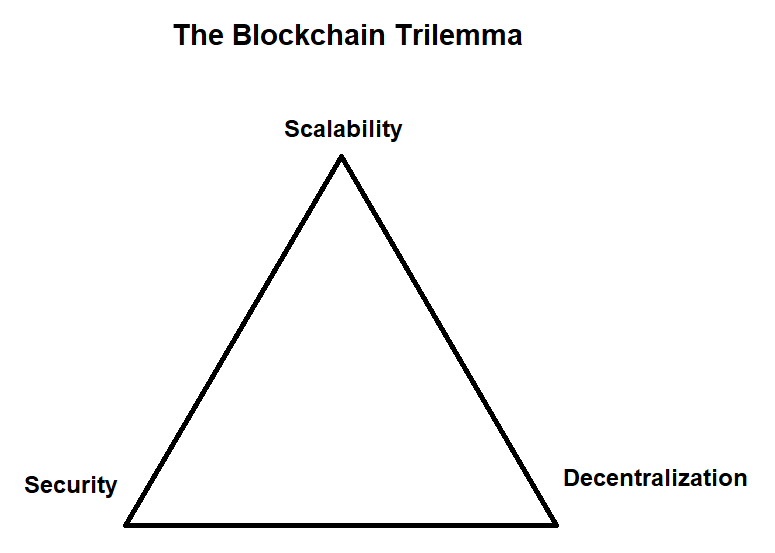
要让数据可用的需要,是我们无法同时拥有全部3个区块链属性的主要原因之一
该机制还描述了在传统单体区块链中保证数据可用性的重要性:区块生产者(矿工/验证器)必须广播并提供来自其产生的区块的交易数据,以便全节点可以检查其工作。如果区块生产者不让其生产的区块中的交易数据可用,我们将处于这样一种情况:即全节点无法检查他们的工作并通过执行区块链的规则集来保持矿工/验证者的诚实!
现在你了解了,为什么数据可用性在传统的单体区块链中很重要,让我们来继续讨论,它(DA)如何影响大家最喜欢的可扩展性解决方案——rollup。
在Rollup环境中,数据可用性的重要性
让我们首先回顾一下rollup是如何帮助解决可扩展性问题的:与其提高运行全节点的硬件要求,不如减少全节点必须检查是否有效的tx数量?我们可通过将tx计算和执行从全节点转移到功能更强大的计算机(称为定序器)来实现这一点。
那这不意味着我们必须相信定序器吗?如果要保持低的全节点硬件要求,那么在尝试检查定序器的工作时肯定会落后于定序器。
那么,我们如何确保该定序器提出的新区块是有效的(即,定序器没有窃取每个人的资金)?考虑到它已经被反复提过,我相信你已经知道了这个问题的答案,但请耐心等待(如果你需要复习,可以阅读下Benjamin Simon的文章?,或者是Vitalik的文章?):
对于 Optimistic Rollup,我们依靠称为欺诈证明的东西来保持定序器是诚实的(我们假设定序器正在运行,除非有人提交表明定序器包含无效/恶意交易的欺诈证明)。但如果我们希望其他人能够计算欺诈证明,他们将需要定序器执行的交易中的tx数据才能提交欺诈证明。换句话说,定序器必须使tx数据可用,否则的话,没有人能够保证 optimistic rollup的定序器是诚实的!
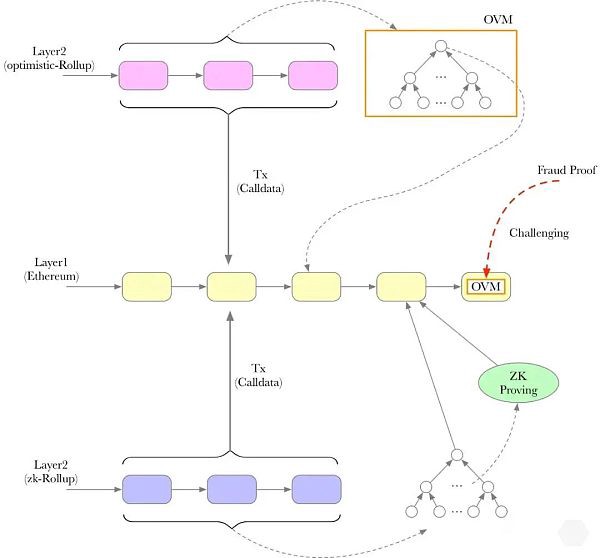
而在ZK Rollup的情况下,要保持定序器诚实就简单多了:定序器在执行一批tx时,必须提交有效性证明(ZK-SNARK/STACK),而这种有效性证明可保证没有任何tx是无效的/恶意的。此外,任何人(甚至是智能合约)都可以轻松验证提交的证明。但对于ZK Rollup的定序器来说,让数据可用仍然是非常重要的。这是因为,作为上述rollup的用户,如果我们想使用垃圾币,我们需要知道Rollup上的账户余额是多少。如果交易数据不可用,我们将无法知道我们的帐户余额如何,并且将无法再与rollup 进行交互。
请注意,以上内容让我们确切地看到了,为什么人们一直在吹捧rollup。鉴于全节点不需要跟上定序器,为什么不让定序器成为一台功能强大的计算机呢?这将使定序器每秒执行的tx量达到可怕的程度,从而降低gas费用,让每个人都感到高兴。但是,你还记得定序器需要如何使tx数据可用吗?这意味着即使定序器是一台真正的超级计算机,它每秒实际可计算的tx数量,仍将受到其使用的底层数据可用性解决方案/层的数据吞吐量的限制。
简而言之,如果rollup所使用的数据可用性解决方案/层,无法跟上rollup的定序器希望转储到其上的数据量,那么定序器(以及rollup)即使愿意,也无法处理更多的tx,这会导致我们今天在以太坊上看到的gas费用飙升的情况。
这正是数据可用性极其重要的原因:保证数据可用性使我们能够确保rollup定序器的行为,如果rollup要最大化其tx吞吐量,则最大化数据可用性解决方案/层的数据空间吞吐量是至关重要的。
但是细心的读者可能会意识到,我们实际上还没有完全解决确保定序器正常工作的问题。如果rollup结算的“父”区块链的全节点不需要跟上定序器,定序器可以选择扣留大部分交易数据。父区块链的节点如何强制定序器将数据转储到数据可用性层?如果节点无法强制执行,我们实际上在可扩展性方面没有取得任何进展,因为我们将被迫信任定序器,或者自己去购买超级计算机!
这一问题就被称为“数据可用性问题”。
“数据可用性问题”的解决方案
数据可用性问题最显而易见的解决方案,就是强制全节点将定序器转储的所有数据下载到数据可用性层/解决方案,但我们知道,这并不现实,因为它需要全节点跟上定序器的tx计算速率,从而提高了运行全节点的硬件要求(降低了去中心化)。
因此很明显,我们需要一个更好的解决方案来解决这个问题,而且,我们确实有一个好的解决方案!
数据可用性(DA)证明
每次定序器转储一个新的tx数据区块时,节点可使用称为数据可用性证明的新发明“采样”数据,确保定序器确实提供了数据。
这些数据可用性证明的实际工作原理非常复杂(涉及到很多术语和数学),但无论如何,我都会去尽力解释(感谢John Adler?)。
我们可以首先要求对定序器转储的tx数据块进行纠删码( erasure-coded),这基本上意味着减半原始数据大小,然后新的/额外的数据用冗余片段编码(这部分就是我们所说的纠删码)。通过对数据进行纠删码处理,我们可以用任意50%的纠删码数据恢复全部原始数据。

但是请注意,通过对tx数据块进行纠删码,这将需要行为不端的定序器扣留超过50%的区块数据。如果该区块没有被纠删码,定序器可能会因为只扣留了1%的数据而出现错误-因此通过对数据进行纠删码,我们已经大大提高了全节点可以拥有的置信度,即定序器确实在使数据可用。
尽管如此,我们希望尽可能多地保证定序器使所有数据可用,理想情况下,我们希望像直接下载整个tx数据块一样自信。事实上,这是可能的:全节点可随机选择从区块中下载一些数据。如果定序器行为不端,全节点被愚弄的可能性<50%,即当定序器试图扣留数据时,随机下载一段数据。这是因为,如果定序器试图行为不端并扣留数据,请记住,他们必须扣留>50%的纠删码数据。
请注意,这意味着通过再次执行此操作,全节点可以大大降低被欺骗的可能性。通过随机选择另一块数据进行第二次下载,被欺骗的可能性将小于 25%。事实上,当一个全节点第七次尝试随机下载一部分数据时,它未能检测到定序器正在扣留数据的可能性将小于1%。
这一过程就被称为数据可用性证明抽样,或简称为数据可用性抽样。它的效率是令人难以置信的,因为这意味着节点可以只下载父区块链上定序器发布的完整数据块的一部分,并且具有与下载和检查整个数据块基本相同的保证(节点可以使用父区块链上的merkle根查找采样内容/位置)。为了确保我真正把这一点牢记在心:想象一下,如果在附近散步10分钟所消耗的热量,与跑步10公里所消耗的热量一样多。这就是数据可用性采样技术的突破性意义。
通过让父区块链的全节点能够进行数据可用性采样,我们现在已经解决了我们之前的困境,即如何确保rollup定序器不会出现错误行为。我们现在都觉得很开心了,因为我们可以相信rollup确实能够扩展我们最喜欢的区块链。但是,等一下,在你停止阅读这篇文章之前,请记住,如果我们想要让区块链被全世界的人使用(因此我们的投资标的可以有更多的上升空间),我们仍然需要找到一种方法来扩展数据可用性本身。我们需要rollup,如果我们希望用rollup来扩展区块链,我们不仅需要削弱定序器作恶的能力,我们还必须扩展数据空间吞吐量,以便定序器有一个廉价的地方来转储其tx数据。
数据可用性证明也是扩展数据空间吞吐量的关键
目前,以太坊(Ethereum)作为最知名的L1公链,其路线图侧重于扩展数据空间吞吐量。以太坊希望通过数据分片来实现这一点,这本质上意味着并非每个验证器都会继续下载与节点当前相同的tx数据(验证器也会运行节点)。相反,以太坊将把它的验证器网络分成不同的分区(称为“分片”),如果你有 1000 个验证器,所有这些验证器都用来存储相同的数据,而你将其分成4组,每组250个验证器,那么用于转储数据的 rollup可用空间就突然增加了4倍!这听上去很简单,对吧?
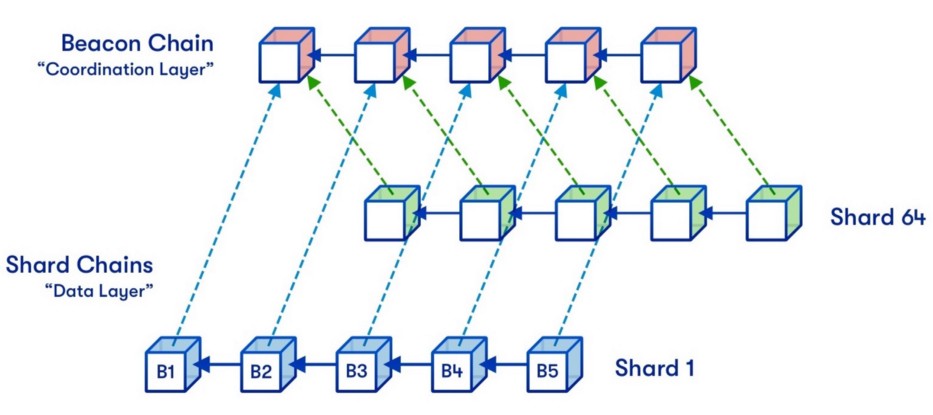
以太坊近期的数据分片路线图争取实现64个数据分片
然而,问题是,分片内的验证器只会下载转储到其分片的tx数据。这意味着,一个分片中的验证器不能保证定序器转储的所有数据都是可用的,它们只能保证转储到其分片区的数据是可用的,但不能保证其余数据可用于其他分片。
这意味着我们会遇到这样一种情况,即一个分片中的验证器无法确保定序器没有出现错误,因为它们不知道其他分片中发生了什么,这就是我们的朋友(数据可用性采样)再次派上用场的地方。如果你是一个分片中的验证者,那么你可以在每个其他分片中使用数据可用性证明简单地采样数据可用性!这将为你提供基本相同的保证,就像你是每个分片中的验证者一样,从而允许以太坊安全地实现数据分片。
还有其他的区块链(例如Celestia和Polygon Avail),它们希望扩展到海量的数据空间吞吐量。与大多数其他区块链不同,Celestia和Polygon Avail仅寻求做两件事:排序区块和交易,并成为数据可用性层。这意味着要保持 Celestia / Polygon Avail 的验证器诚实,重要的是要有一个去中心化的节点网络,以确保验证器确实正确地存储和排序tx数据。但是,由于不需要解释(即执行/或计算)这些数据,你不需要一个全节点来保证验证器的行为!相反,执行数据可用性采样的轻节点,将具有与全节点基本相同的保证,并且有许多轻节点采样数据可用性证明将足以让验证器负责保证数据可用性。这意味着,只要有足够多的节点使用数据可用性证明对数据可用性进行采样(这很容易,因为数据可用性证明甚至可通过手机计算),你可以使区块大小更大并增加验证器的硬件要求,从而提高数据空间吞吐量。

现在,总结一下:数据可用性问题可能是区块链三难困境的症结所在,它影响到了我们所有的扩容工作。幸运的是,我们能通过数据可用性证明的核心技术,来解决数据可用性问题。这使我们能够大规模地扩展数据空间吞吐量,为rollup提供了一个廉价的地方来转储足够的tx数据来处理足够的tx,以供全球人口使用。此外,数据可用性证明意味着我们不必信任rollup定序器,我们可以让它们保持诚实并验证它们的行为。现在,希望这篇文章可以帮助你准确理解,为什么数据可用性对rollup发挥其全部潜力而言是至关重要的。
想更深入一些吗?我建议你钻进以下的兔子洞:
- 最初的论文提出了一个欺诈和数据可用性证明系统,以提高轻客户端安全性并扩展区块链(这篇论文?由Mustafa Al-Bassam、Alberto Sonnino和Vitalik Buterin共同撰写?)。
- 更容易理解以及更简短的版本?。
- 以太坊以rollup为中心的路线图?。
- Vitalik演讲:2020年及以后如何扩展以太坊?
- John Adler谈论数据可用性问题?
- Ismail Khoffi谈论Celestia?
- zkSync的Angela Lu、Arbitrum的Daniel Goldman以及Fuel Labs的John Adler一起录制的内容?,为我们提供了Rollup和以太坊数据分片路线图的很多信息。


