谷歌DeepMind团队围棋类AI新进展:AlphaGo升级版AlphaZero强势来袭
AI锐见近日,据外媒报道,谷歌DeepMind团队带来了一个全新的通用的版本。这个程序被称为AlphaZero,它教会自己在短短三天内玩三种不同的棋盘游戏(国际象棋、围棋和日本版国际象棋),没有人为干预,这一描述成就的论文发表在《科学》杂志上。

DeepMind首席执行官兼联合创始人Demis Hassabis说“从完全随机的游戏开始,AlphaZero逐渐学会了什么是好的游戏,并形成了自己对游戏的评价。从这个意义上讲,它不受人类对游戏思考方式的限制。”
AlphaZero是DeepMind旗下AlphaGo的直系后代。2016年,AlphaGo打败了围棋(人类)世界冠军李世石(Lee Sedol),成为世界各地的头条新闻。AlphaGo并不满足于此,去年获得了一次重大升级,能够在不需要人工干预的情况下自学获胜策略。
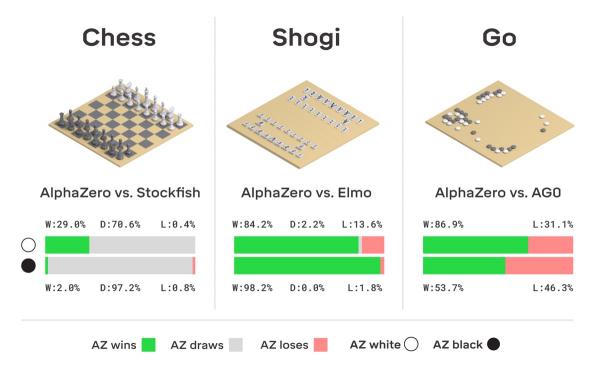
通过一遍又一遍地与自己下棋,AlphaGo Zero (AGZ)训练自己在短短三天时间内从零开始,以0比100完胜最初的AlphaGo 100。它得到的唯一输入是游戏的基本规则。
AlphaZero通过应用大量处理能力,5,000张处理单元(TPU),相当于一台非常大的超级计算机,很快地学会了玩三种棋盘游戏中的每一种。

不像以前的国际象棋机器那样以极快的速度处理人类的指令和知识,AlphaZero会产生自己的知识,它只需几个小时即可完成,其结果已超过任何已知的人或机器。
但是,AlphaZero的基本算法实际上仅适用于可以采取相当数量的操作问题。它还需要一个强大的环境模型,即游戏规则。
